 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Overfocusing Bias of Convolutional Neural Networks: A Saliency-Guided Regularization Approach
Sep 25, 2024Despite transformers being considered as the new standard in computer vision, convolutional neural networks (CNNs) still outperform them in low-data regimes. Nonetheless, CNNs often make decisions based on narrow, specific regions of input images, especially when training data is limited. This behavior can severely compromise the model's generalization capabilities, making it disproportionately dependent on certain features that might not represent the broader context of images. While the conditions leading to this phenomenon remain elusive, the primary intent of this article is to shed light on this observed behavior of neural networks. Our research endeavors to prioritize comprehensive insight and to outline an initial response to this phenomenon. In line with this, we introduce Saliency Guided Dropout (SGDrop), a pioneering regularization approach tailored to address this specific issue. SGDrop utilizes attribution methods on the feature map to identify and then reduce the influence of the most salient features during training. This process encourages the network to diversify its attention and not focus solely on specific standout areas. Our experiments across several visual classification benchmarks validate SGDrop's role in enhancing generalization. Significantly, models incorporating SGDrop display more expansive attributions and neural activity, offering a more comprehensive view of input images in contrast to their traditionally trained counterparts.
Look where you look! Saliency-guided Q-networks for visual RL tasks
Sep 29, 2022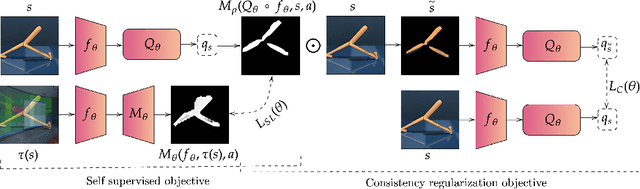
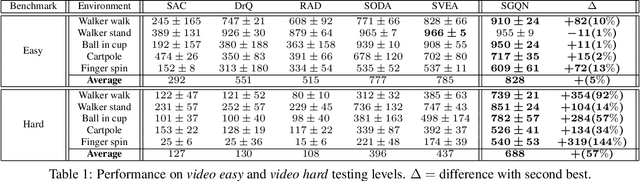

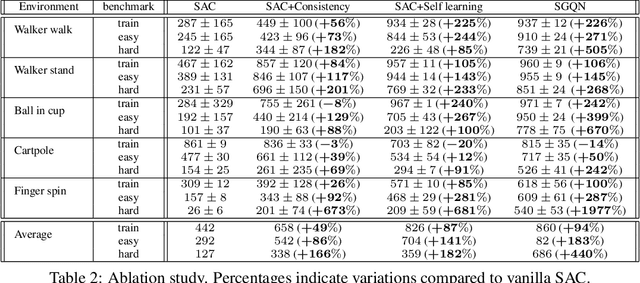
Deep reinforcement learning policies, despite their outstanding efficiency in simulated visual control tasks, have shown disappointing ability to generalize across disturbances in the input training images. Changes in image statistics or distracting background elements are pitfalls that prevent generalization and real-world applicability of such control policies. We elaborate on the intuition that a good visual policy should be able to identify which pixels are important for its decision, and preserve this identification of important sources of information across images. This implies that training of a policy with small generalization gap should focus on such important pixels and ignore the others. This leads to the introduction of saliency-guided Q-networks (SGQN), a generic method for visual reinforcement learning, that is compatible with any value function learning method. SGQN vastly improves the generalization capability of Soft Actor-Critic agents and outperforms existing stateof-the-art methods on the Deepmind Control Generalization benchmark, setting a new reference in terms of training efficiency, generalization gap, and policy interpretability.