 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Overfocusing Bias of Convolutional Neural Networks: A Saliency-Guided Regularization Approach
Sep 25, 2024Despite transformers being considered as the new standard in computer vision, convolutional neural networks (CNNs) still outperform them in low-data regimes. Nonetheless, CNNs often make decisions based on narrow, specific regions of input images, especially when training data is limited. This behavior can severely compromise the model's generalization capabilities, making it disproportionately dependent on certain features that might not represent the broader context of images. While the conditions leading to this phenomenon remain elusive, the primary intent of this article is to shed light on this observed behavior of neural networks. Our research endeavors to prioritize comprehensive insight and to outline an initial response to this phenomenon. In line with this, we introduce Saliency Guided Dropout (SGDrop), a pioneering regularization approach tailored to address this specific issue. SGDrop utilizes attribution methods on the feature map to identify and then reduce the influence of the most salient features during training. This process encourages the network to diversify its attention and not focus solely on specific standout areas. Our experiments across several visual classification benchmarks validate SGDrop's role in enhancing generalization. Significantly, models incorporating SGDrop display more expansive attributions and neural activity, offering a more comprehensive view of input images in contrast to their traditionally trained counterparts.
Time-Constrained Robust MDPs
Jun 12, 2024Robust reinforcement learning is essential for deploying reinforcement learning algorithms in real-world scenarios where environmental uncertainty predominates. Traditional robust reinforcement learning often depends on rectangularity assumptions, where adverse probability measures of outcome states are assumed to be independent across different states and actions. This assumption, rarely fulfilled in practice, leads to overly conservative policies. To address this problem, we introduce a new time-constrained robust MDP (TC-RMDP) formulation that considers multifactorial, correlated, and time-dependent disturbances, thus more accurately reflecting real-world dynamics. This formulation goes beyond the conventional rectangularity paradigm, offering new perspectives and expanding the analytical framework for robust RL. We propose three distinct algorithms, each using varying levels of environmental information, and evaluate them extensively on continuous control benchmarks. Our results demonstrate that these algorithms yield an efficient tradeoff between performance and robustness, outperforming traditional deep robust RL methods in time-constrained environments while preserving robustness in classical benchmarks. This study revisits the prevailing assumptions in robust RL and opens new avenues for developing more practical and realistic RL applications.
RRLS : Robust Reinforcement Learning Suite
Jun 12, 2024Robust reinforcement learning is the problem of learning control policies that provide optimal worst-case performance against a span of adversarial environments. It is a crucial ingredient for deploying algorithms in real-world scenarios with prevalent environmental uncertainties and has been a long-standing object of attention in the community, without a standardized set of benchmarks. This contribution endeavors to fill this gap. We introduce the Robust Reinforcement Learning Suite (RRLS), a benchmark suite based on Mujoco environments. RRLS provides six continuous control tasks with two types of uncertainty sets for training and evaluation. Our benchmark aims to standardize robust reinforcement learning tasks, facilitating reproducible and comparable experiments, in particular those from recent state-of-the-art contributions, for which we demonstrate the use of RRLS. It is also designed to be easily expandable to new environments. The source code is available at \href{https://github.com/SuReLI/RRLS}{https://github.com/SuReLI/RRLS}.
Look where you look! Saliency-guided Q-networks for visual RL tasks
Sep 29, 2022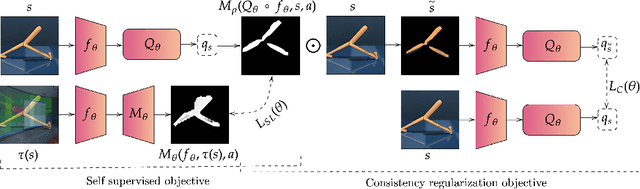
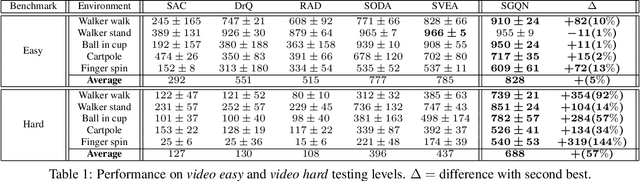

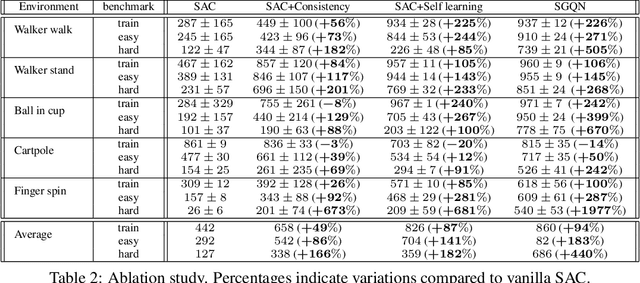
Deep reinforcement learning policies, despite their outstanding efficiency in simulated visual control tasks, have shown disappointing ability to generalize across disturbances in the input training images. Changes in image statistics or distracting background elements are pitfalls that prevent generalization and real-world applicability of such control policies. We elaborate on the intuition that a good visual policy should be able to identify which pixels are important for its decision, and preserve this identification of important sources of information across images. This implies that training of a policy with small generalization gap should focus on such important pixels and ignore the others. This leads to the introduction of saliency-guided Q-networks (SGQN), a generic method for visual reinforcement learning, that is compatible with any value function learning method. SGQN vastly improves the generalization capability of Soft Actor-Critic agents and outperforms existing stateof-the-art methods on the Deepmind Control Generalization benchmark, setting a new reference in terms of training efficiency, generalization gap, and policy interpretability.
Local Feature Swapping for Generalization in Reinforcement Learning
Apr 13, 2022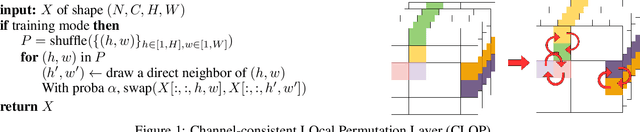



Over the past few years, the acceleration of computing resources and research in deep learning has led to significant practical successes in a range of tasks, including in particular in computer vision. Building on these advances, reinforcement learning has also seen a leap forward with the emergence of agents capable of making decisions directly from visual observations. Despite these successes, the over-parametrization of neural architectures leads to memorization of the data used during training and thus to a lack of generalization. Reinforcement learning agents based on visual inputs also suffer from this phenomenon by erroneously correlating rewards with unrelated visual features such as background elements. To alleviate this problem, we introduce a new regularization technique consisting of channel-consistent local permutations (CLOP) of the feature maps. The proposed permutations induce robustness to spatial correlations and help prevent overfitting behaviors in RL. We demonstrate, on the OpenAI Procgen Benchmark, that RL agents trained with the CLOP method exhibit robustness to visual changes and better generalization properties than agents trained using other state-of-the-art regularization techniques. We also demonstrate the effectiveness of CLOP as a general regularization technique in supervised learning.
Disentanglement by Cyclic Reconstruction
Dec 24, 2021



Deep neural networks have demonstrated their ability to automatically extract meaningful features from data. However, in supervised learning, information specific to the dataset used for training, but irrelevant to the task at hand, may remain encoded in the extracted representations. This remaining information introduces a domain-specific bias, weakening the generalization performance. In this work, we propose splitting the information into a task-related representation and its complementary context representation. We propose an original method, combining adversarial feature predictors and cyclic reconstruction, to disentangle these two representations in the single-domain supervised case. We then adapt this method to the unsupervised domain adaptation problem, consisting of training a model capable of performing on both a source and a target domain. In particular, our method promotes disentanglement in the target domain, despite the absence of training labels. This enables the isolation of task-specific information from both domains and a projection into a common representation. The task-specific representation allows efficient transfer of knowledge acquired from the source domain to the target domain. In the single-domain case, we demonstrate the quality of our representations on information retrieval tasks and the generalization benefits induced by sharpened task-specific representations. We then validate the proposed method on several classical domain adaptation benchmarks and illustrate the benefits of disentanglement for domain adaptation.
Numerical influence of ReLU'(0) on backpropagation
Jun 29, 2021

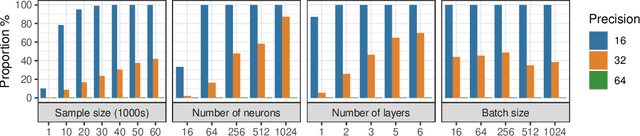
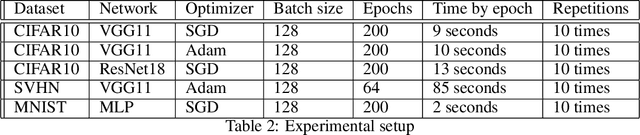
In theory, the choice of ReLU'(0) in [0, 1] for a neural network has a negligible influence both on backpropagation and training. Yet, in the real world, 32 bits default precision combined with the size of deep learning problems makes it a hyperparameter of training methods. We investigate the importance of the value of ReLU'(0) for several precision levels (16, 32, 64 bits), on various networks (fully connected, VGG, ResNet) and datasets (MNIST, CIFAR10, SVHN). We observe considerable variations of backpropagation outputs which occur around half of the time in 32 bits precision. The effect disappears with double precision, while it is systematic at 16 bits. For vanilla SGD training, the choice ReLU'(0) = 0 seems to be the most efficient. We also evidence that reconditioning approaches as batch-norm or ADAM tend to buffer the influence of ReLU'(0)'s value. Overall, the message we want to convey is that algorithmic differentiation of nonsmooth problems potentially hides parameters that could be tuned advantageously.