 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond task performance: Decoding bioacoustic embeddings with speech features
Jun 12, 2026Pretrained audio embeddings are standard in bioacoustics, yet little is known about which acoustic features these models encode, nor which are useful for a given task. This hinders transparency and limits extension to rare species or data-scarce domains. Here we reveal which speech-like features are encoded in bioacoustic representations. Using the 88~eGeMAPS features across six taxonomic groups, we apply linear and nonlinear regression probes to quantify which acoustic properties each model captures. Results confirm a ``no free lunch'' pattern: no single model captures the full feature space. A concatenated embedding achieves the highest performance, suggesting complementary acoustic space coverage across models. Loudness features are best encoded ($R^2 = 0.76$) while F0 is hardest to recover ($R^2 = 0.33$). By cross-referencing recoverability with per-species feature salience (NMI), we derive data-driven model selection guidance for bioacoustics.
Multi-layer attentive probing improves transfer of audio representations for bioacoustics
May 11, 2026Probing heads map the representations learned from audio by a machine learning model to downstream task labels and are a key component in evaluating representation learning. Most bioacoustic benchmarks use a fixed, low-capacity probe, such as a linear layer on the final encoder layer. While this standardization enables model comparisons, it may bias results by overlooking the interaction between encoder features and probe design. In this work, we systematically study different probing strategies across two bioacoustic benchmarks, BEANs and BirdSet. We evaluate last- and multi-layer probing, across linear and attention probes. We show that larger probe heads that leverage time information have superior performance. Our results suggest that current benchmarks may misrepresent encoder quality when relying on a last-layer probing setup. Multi-layer probing improves downstream task performance across all tested models, while attention probing has superior performance to linear probing for transformer models.
Multi-agent imitation learning with function approximation: Linear Markov games and beyond
Feb 26, 2026In this work, we present the first theoretical analysis of multi-agent imitation learning (MAIL) in linear Markov games where both the transition dynamics and each agent's reward function are linear in some given features. We demonstrate that by leveraging this structure, it is possible to replace the state-action level "all policy deviation concentrability coefficient" (Freihaut et al., arXiv:2510.09325) with a concentrability coefficient defined at the feature level which can be much smaller than the state-action analog when the features are informative about states' similarity. Furthermore, to circumvent the need for any concentrability coefficient, we turn to the interactive setting. We provide the first, computationally efficient, interactive MAIL algorithm for linear Markov games and show that its sample complexity depends only on the dimension of the feature map $d$. Building on these theoretical findings, we propose a deep MAIL interactive algorithm which clearly outperforms BC on games such as Tic-Tac-Toe and Connect4.
Bench-MFG: A Benchmark Suite for Learning in Stationary Mean Field Games
Feb 13, 2026The intersection of Mean Field Games (MFGs) and Reinforcement Learning (RL) has fostered a growing family of algorithms designed to solve large-scale multi-agent systems. However, the field currently lacks a standardized evaluation protocol, forcing researchers to rely on bespoke, isolated, and often simplistic environments. This fragmentation makes it difficult to assess the robustness, generalization, and failure modes of emerging methods. To address this gap, we propose a comprehensive benchmark suite for MFGs (Bench-MFG), focusing on the discrete-time, discrete-space, stationary setting for the sake of clarity. We introduce a taxonomy of problem classes, ranging from no-interaction and monotone games to potential and dynamics-coupled games, and provide prototypical environments for each. Furthermore, we propose MF-Garnets, a method for generating random MFG instances to facilitate rigorous statistical testing. We benchmark a variety of learning algorithms across these environments, including a novel black-box approach (MF-PSO) for exploitability minimization. Based on our extensive empirical results, we propose guidelines to standardize future experimental comparisons. Code available at \href{https://github.com/lorenzomagnino/Bench-MFG}{https://github.com/lorenzomagnino/Bench-MFG}.
Audio-to-Image Bird Species Retrieval without Audio-Image Pairs via Text Distillation
Jan 31, 2026Audio-to-image retrieval offers an interpretable alternative to audio-only classification for bioacoustic species recognition, but learning aligned audio-image representations is challenging due to the scarcity of paired audio-image data. We propose a simple and data-efficient approach that enables audio-to-image retrieval without any audio-image supervision. Our proposed method uses text as a semantic intermediary: we distill the text embedding space of a pretrained image-text model (BioCLIP-2), which encodes rich visual and taxonomic structure, into a pretrained audio-text model (BioLingual) by fine-tuning its audio encoder with a contrastive objective. This distillation transfers visually grounded semantics into the audio representation, inducing emergent alignment between audio and image embeddings without using images during training. We evaluate the resulting model on multiple bioacoustic benchmarks. The distilled audio encoder preserves audio discriminative power while substantially improving audio-text alignment on focal recordings and soundscape datasets. Most importantly, on the SSW60 benchmark, the proposed approach achieves strong audio-to-image retrieval performance exceeding baselines based on zero-shot model combinations or learned mappings between text embeddings, despite not training on paired audio-image data. These results demonstrate that indirect semantic transfer through text is sufficient to induce meaningful audio-image alignment, providing a practical solution for visually grounded species recognition in data-scarce bioacoustic settings.
Compact Hypercube Embeddings for Fast Text-based Wildlife Observation Retrieval
Jan 30, 2026Large-scale biodiversity monitoring platforms increasingly rely on multimodal wildlife observations. While recent foundation models enable rich semantic representations across vision, audio, and language, retrieving relevant observations from massive archives remains challenging due to the computational cost of high-dimensional similarity search. In this work, we introduce compact hypercube embeddings for fast text-based wildlife observation retrieval, a framework that enables efficient text-based search over large-scale wildlife image and audio databases using compact binary representations. Building on the cross-view code alignment hashing framework, we extend lightweight hashing beyond a single-modality setup to align natural language descriptions with visual or acoustic observations in a shared Hamming space. Our approach leverages pretrained wildlife foundation models, including BioCLIP and BioLingual, and adapts them efficiently for hashing using parameter-efficient fine-tuning. We evaluate our method on large-scale benchmarks, including iNaturalist2024 for text-to-image retrieval and iNatSounds2024 for text-to-audio retrieval, as well as multiple soundscape datasets to assess robustness under domain shift. Results show that retrieval using discrete hypercube embeddings achieves competitive, and in several cases superior, performance compared to continuous embeddings, while drastically reducing memory and search cost. Moreover, we observe that the hashing objective consistently improves the underlying encoder representations, leading to stronger retrieval and zero-shot generalization. These results demonstrate that binary, language-based retrieval enables scalable and efficient search over large wildlife archives for biodiversity monitoring systems.
RL-AVIST: Reinforcement Learning for Autonomous Visual Inspection of Space Targets
Oct 26, 2025The growing need for autonomous on-orbit services such as inspection, maintenance, and situational awareness calls for intelligent spacecraft capable of complex maneuvers around large orbital targets. Traditional control systems often fall short in adaptability, especially under model uncertainties, multi-spacecraft configurations, or dynamically evolving mission contexts. This paper introduces RL-AVIST, a Reinforcement Learning framework for Autonomous Visual Inspection of Space Targets. Leveraging the Space Robotics Bench (SRB), we simulate high-fidelity 6-DOF spacecraft dynamics and train agents using DreamerV3, a state-of-the-art model-based RL algorithm, with PPO and TD3 as model-free baselines. Our investigation focuses on 3D proximity maneuvering tasks around targets such as the Lunar Gateway and other space assets. We evaluate task performance under two complementary regimes: generalized agents trained on randomized velocity vectors, and specialized agents trained to follow fixed trajectories emulating known inspection orbits. Furthermore, we assess the robustness and generalization of policies across multiple spacecraft morphologies and mission domains. Results demonstrate that model-based RL offers promising capabilities in trajectory fidelity, and sample efficiency, paving the way for scalable, retrainable control solutions for future space operations
Learning Equilibria from Data: Provably Efficient Multi-Agent Imitation Learning
May 23, 2025This paper provides the first expert sample complexity characterization for learning a Nash equilibrium from expert data in Markov Games. We show that a new quantity named the single policy deviation concentrability coefficient is unavoidable in the non-interactive imitation learning setting, and we provide an upper bound for behavioral cloning (BC) featuring such coefficient. BC exhibits substantial regret in games with high concentrability coefficient, leading us to utilize expert queries to develop and introduce two novel solution algorithms: MAIL-BRO and MURMAIL. The former employs a best response oracle and learns an $\varepsilon$-Nash equilibrium with $\mathcal{O}(\varepsilon^{-4})$ expert and oracle queries. The latter bypasses completely the best response oracle at the cost of a worse expert query complexity of order $\mathcal{O}(\varepsilon^{-8})$. Finally, we provide numerical evidence, confirming our theoretical findings.
NavBench: A Unified Robotics Benchmark for Reinforcement Learning-Based Autonomous Navigation
May 20, 2025Autonomous robots must navigate and operate in diverse environments, from terrestrial and aquatic settings to aerial and space domains. While Reinforcement Learning (RL) has shown promise in training policies for specific autonomous robots, existing benchmarks are often constrained to unique platforms, limiting generalization and fair comparisons across different mobility systems. In this paper, we present NavBench, a multi-domain benchmark for training and evaluating RL-based navigation policies across diverse robotic platforms and operational environments. Built on IsaacLab, our framework standardizes task definitions, enabling different robots to tackle various navigation challenges without the need for ad-hoc task redesigns or custom evaluation metrics. Our benchmark addresses three key challenges: (1) Unified cross-medium benchmarking, enabling direct evaluation of diverse actuation methods (thrusters, wheels, water-based propulsion) in realistic environments; (2) Scalable and modular design, facilitating seamless robot-task interchangeability and reproducible training pipelines; and (3) Robust sim-to-real validation, demonstrated through successful policy transfer to multiple real-world robots, including a satellite robotic simulator, an unmanned surface vessel, and a wheeled ground vehicle. By ensuring consistency between simulation and real-world deployment, NavBench simplifies the development of adaptable RL-based navigation strategies. Its modular design allows researchers to easily integrate custom robots and tasks by following the framework's predefined templates, making it accessible for a wide range of applications. Our code is publicly available at NavBench.
ShiQ: Bringing back Bellman to LLMs
May 16, 2025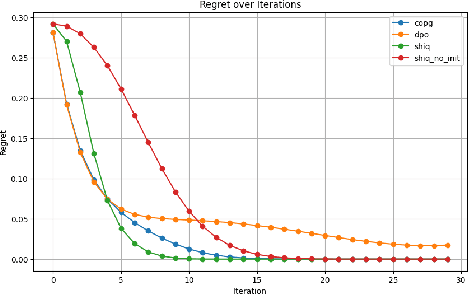
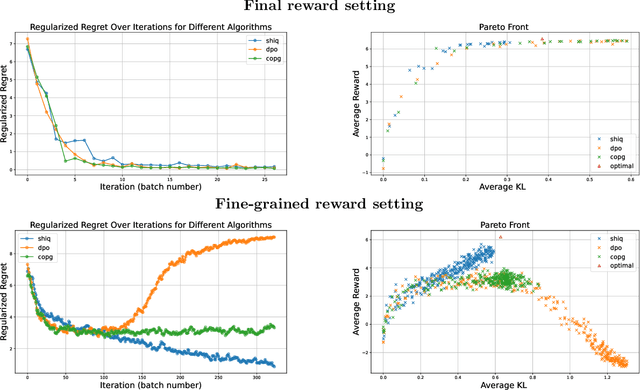

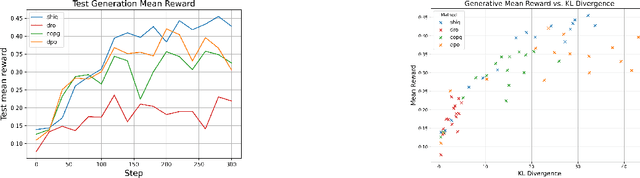
The fine-tuning of pre-trained large language models (LLMs) using reinforcement learning (RL) is generally formulated as direct policy optimization. This approach was naturally favored as it efficiently improves a pretrained LLM, seen as an initial policy. Another RL paradigm, Q-learning methods, has received far less attention in the LLM community while demonstrating major success in various non-LLM RL tasks. In particular, Q-learning effectiveness comes from its sample efficiency and ability to learn offline, which is particularly valuable given the high computational cost of sampling with LLMs. However, naively applying a Q-learning-style update to the model's logits is ineffective due to the specificity of LLMs. Our core contribution is to derive theoretically grounded loss functions from Bellman equations to adapt Q-learning methods to LLMs. To do so, we carefully adapt insights from the RL literature to account for LLM-specific characteristics, ensuring that the logits become reliable Q-value estimates. We then use this loss to build a practical algorithm, ShiQ for Shifted-Q, that supports off-policy, token-wise learning while remaining simple to implement. Finally, we evaluate ShiQ on both synthetic data and real-world benchmarks, e.g., UltraFeedback and BFCL-V3, demonstrating its effectiveness in both single-turn and multi-turn LLM settings