 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhich Pieces Does Unigram Tokenization Really Need?
Dec 14, 2025



The Unigram tokenization algorithm offers a probabilistic alternative to the greedy heuristics of Byte-Pair Encoding. Despite its theoretical elegance, its implementation in practice is complex, limiting its adoption to the SentencePiece package and adapters thereof. We bridge this gap between theory and practice by providing a clear guide to implementation and parameter choices. We also identify a simpler algorithm that accepts slightly higher training loss in exchange for improved compression.
BPE Stays on SCRIPT: Structured Encoding for Robust Multilingual Pretokenization
May 30, 2025Byte Pair Encoding (BPE) tokenizers, widely used in Large Language Models, face challenges in multilingual settings, including penalization of non-Western scripts and the creation of tokens with partial UTF-8 sequences. Pretokenization, often reliant on complex regular expressions, can also introduce fragility and unexpected edge cases. We propose SCRIPT (Script Category Representation in PreTokenization), a novel encoding scheme that bypasses UTF-8 byte conversion by using initial tokens based on Unicode script and category properties. This approach enables a simple, rule-based pretokenization strategy that respects script boundaries, offering a robust alternative to pretokenization strategies based on regular expressions. We also introduce and validate a constrained BPE merging strategy that enforces character integrity, applicable to both SCRIPT-BPE and byte-based BPE. Our experiments demonstrate that SCRIPT-BPE achieves competitive compression while eliminating encoding-based penalties for non-Latin-script languages.
Command A: An Enterprise-Ready Large Language Model
Apr 01, 2025



In this report we describe the development of Command A, a powerful large language model purpose-built to excel at real-world enterprise use cases. Command A is an agent-optimised and multilingual-capable model, with support for 23 languages of global business, and a novel hybrid architecture balancing efficiency with top of the range performance. It offers best-in-class Retrieval Augmented Generation (RAG) capabilities with grounding and tool use to automate sophisticated business processes. These abilities are achieved through a decentralised training approach, including self-refinement algorithms and model merging techniques. We also include results for Command R7B which shares capability and architectural similarities to Command A. Weights for both models have been released for research purposes. This technical report details our original training pipeline and presents an extensive evaluation of our models across a suite of enterprise-relevant tasks and public benchmarks, demonstrating excellent performance and efficiency.
Understanding Likelihood Over-optimisation in Direct Alignment Algorithms
Oct 15, 2024



Direct Alignment Algorithms (DAAs), such as Direct Preference Optimisation (DPO) and Identity Preference Optimisation (IPO), have emerged as alternatives to online Reinforcement Learning from Human Feedback (RLHF) algorithms such as Proximal Policy Optimisation (PPO) for aligning language models to human preferences, without the need for explicit reward modelling. These methods generally aim to increase the likelihood of generating better (preferred) completions while discouraging worse (non-preferred) ones, while staying close to the original model's behaviour. In this work, we explore the relationship between completion likelihood and model performance in state-of-the-art DAAs, and identify a critical issue of likelihood over-optimisation. Contrary to expectations, we find that higher likelihood of better completions and larger margins between better and worse completion likelihoods do not necessarily lead to better performance, and may even degrade it. Our analysis reveals that while higher likelihood correlates with better memorisation of factual knowledge patterns, a slightly lower completion likelihood tends to improve output diversity, thus leading to better generalisation to unseen scenarios. Moreover, we identify two key indicators that signal when over-optimised output diversity begins to harm performance: Decreasing Entropy over Top-k Tokens and Diminishing Top-k Probability Mass. Our experimental results validate that these indicators are reliable signs of declining performance under different regularisations, helping prevent over-optimisation and improve alignment with human preferences.
Fishing for Magikarp: Automatically Detecting Under-trained Tokens in Large Language Models
May 08, 2024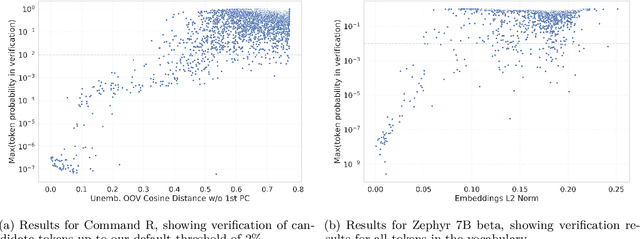
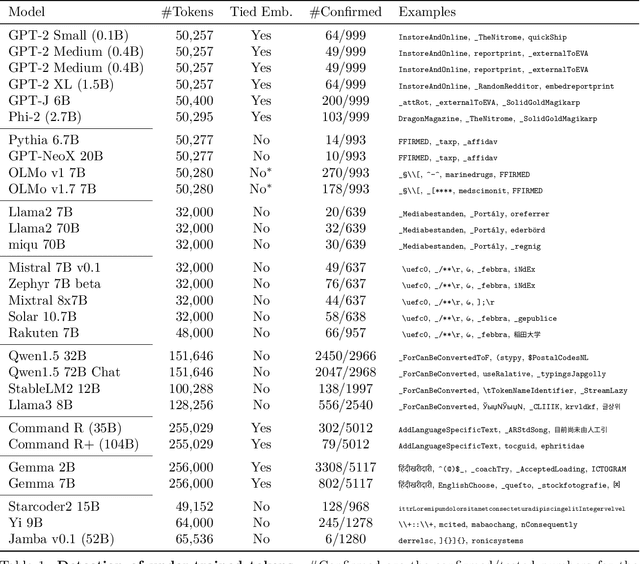
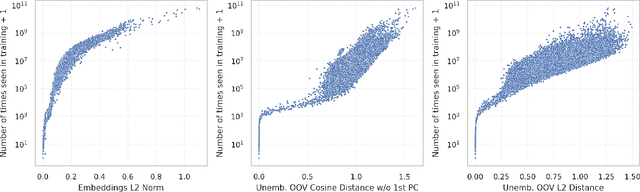
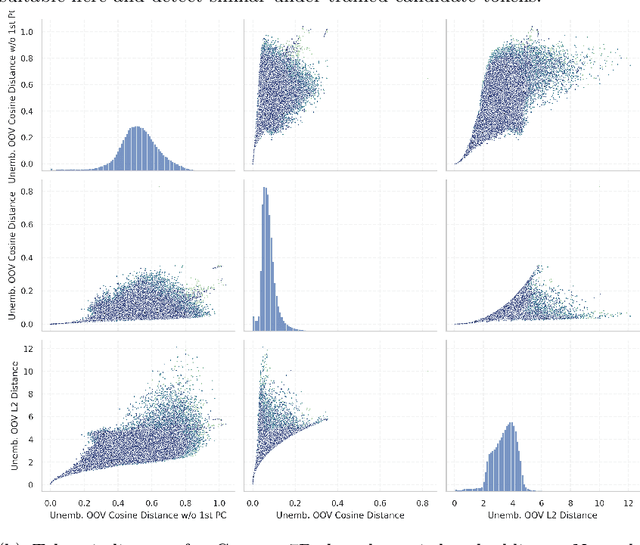
The disconnect between tokenizer creation and model training in language models has been known to allow for certain inputs, such as the infamous SolidGoldMagikarp token, to induce unwanted behaviour. Although such `glitch tokens' that are present in the tokenizer vocabulary, but are nearly or fully absent in training, have been observed across a variety of different models, a consistent way of identifying them has been missing. We present a comprehensive analysis of Large Language Model (LLM) tokenizers, specifically targeting this issue of detecting untrained and under-trained tokens. Through a combination of tokenizer analysis, model weight-based indicators, and prompting techniques, we develop effective methods for automatically detecting these problematic tokens. Our findings demonstrate the prevalence of such tokens across various models and provide insights into improving the efficiency and safety of language models.