 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Solve Complex Problems via Dataset Decomposition
Feb 23, 2026Curriculum learning is a class of training strategies that organizes the data being exposed to a model by difficulty, gradually from simpler to more complex examples. This research explores a reverse curriculum generation approach that recursively decomposes complex datasets into simpler, more learnable components. We propose a teacher-student framework where the teacher is equipped with the ability to reason step-by-step, which is used to recursively generate easier versions of examples, enabling the student model to progressively master difficult tasks. We propose a novel scoring system to measure data difficulty based on its structural complexity and conceptual depth, allowing curriculum construction over decomposed data. Experiments on math datasets (MATH and AIME) and code generation datasets demonstrate that models trained with curricula generated by our approach exhibit superior performance compared to standard training on original datasets.
Learning to Extract Context for Context-Aware LLM Inference
Dec 12, 2025User prompts to large language models (LLMs) are often ambiguous or under-specified, and subtle contextual cues shaped by user intentions, prior knowledge, and risk factors strongly influence what constitutes an appropriate response. Misinterpreting intent or risks may lead to unsafe outputs, while overly cautious interpretations can cause unnecessary refusal of benign requests. In this paper, we question the conventional framework in which LLMs generate immediate responses to requests without considering broader contextual factors. User requests are situated within broader contexts such as intentions, knowledge, and prior experience, which strongly influence what constitutes an appropriate answer. We propose a framework that extracts and leverages such contextual information from the user prompt itself. Specifically, a reinforcement learning based context generator, designed in an autoencoder-like fashion, is trained to infer contextual signals grounded in the prompt and use them to guide response generation. This approach is particularly important for safety tasks, where ambiguous requests may bypass safeguards while benign but confusing requests can trigger unnecessary refusals. Experiments show that our method reduces harmful responses by an average of 5.6% on the SafetyInstruct dataset across multiple foundation models and improves the harmonic mean of attack success rate and compliance on benign prompts by 6.2% on XSTest and WildJailbreak. These results demonstrate the effectiveness of context extraction for safer and more reliable LLM inferences.
Gistify! Codebase-Level Understanding via Runtime Execution
Oct 30, 2025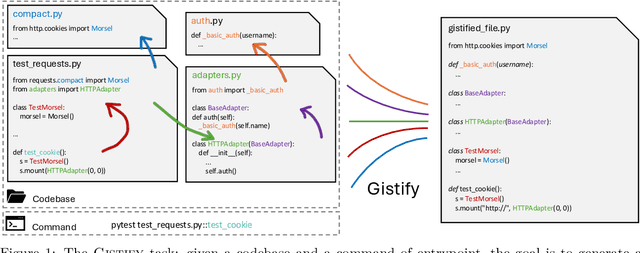
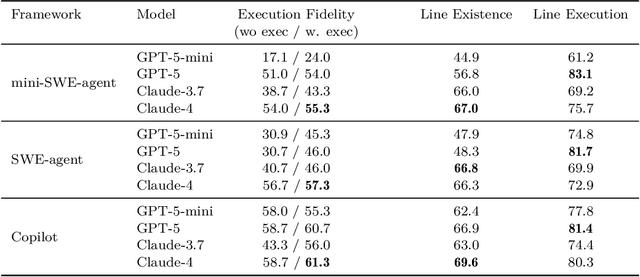

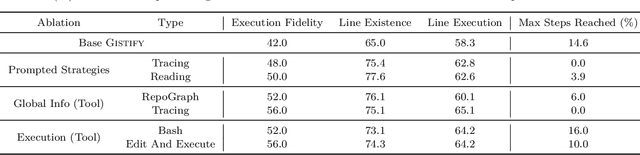
As coding agents are increasingly deployed in large codebases, the need to automatically design challenging, codebase-level evaluation is central. We propose Gistify, a task where a coding LLM must create a single, minimal, self-contained file that can reproduce a specific functionality of a codebase. The coding LLM is given full access to a codebase along with a specific entrypoint (e.g., a python command), and the generated file must replicate the output of the same command ran under the full codebase, while containing only the essential components necessary to execute the provided command. Success on Gistify requires both structural understanding of the codebase, accurate modeling of its execution flow as well as the ability to produce potentially large code patches. Our findings show that current state-of-the-art models struggle to reliably solve Gistify tasks, especially ones with long executions traces.
Optimising Language Models for Downstream Tasks: A Post-Training Perspective
Jun 26, 2025Language models (LMs) have demonstrated remarkable capabilities in NLP, yet adapting them efficiently and robustly to specific tasks remains challenging. As their scale and complexity grow, fine-tuning LMs on labelled data often underutilizes available unlabelled data, leads to overfitting on small task-specific sets, and imposes significant computational costs. These limitations hamper their application to the open-ended landscape of real-world language tasks. This thesis proposes a series of methods to better adapt LMs to downstream applications. First, we explore strategies for extracting task-relevant knowledge from unlabelled data, introducing a novel continued pre-training technique that outperforms state-of-the-art semi-supervised approaches. Next, we present a parameter-efficient fine-tuning method that substantially reduces memory and compute costs while maintaining competitive performance. We also introduce improved supervised fine-tuning methods that enable LMs to better follow instructions, especially when labelled data is scarce, enhancing their performance across a range of NLP tasks, including open-ended generation. Finally, we develop new evaluation methods and benchmarks, such as multi-hop spatial reasoning tasks, to assess LM capabilities and adaptation more comprehensively. Through extensive empirical studies across diverse NLP tasks, our results demonstrate that these approaches substantially improve LM robustness, efficiency, and generalization, making them more adaptable to a broad range of applications. These advances mark a significant step towards more robust and efficient LMs, bringing us closer to the goal of artificial general intelligence.
When Can Proxies Improve the Sample Complexity of Preference Learning?
Dec 21, 2024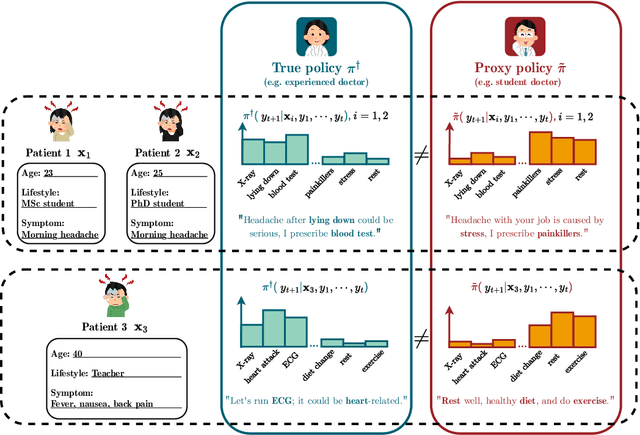
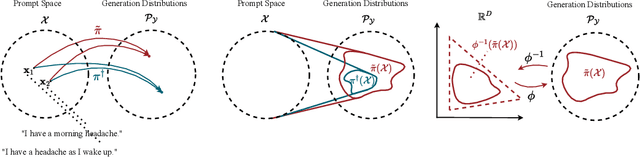
We address the problem of reward hacking, where maximising a proxy reward does not necessarily increase the true reward. This is a key concern for Large Language Models (LLMs), as they are often fine-tuned on human preferences that may not accurately reflect a true objective. Existing work uses various tricks such as regularisation, tweaks to the reward model, and reward hacking detectors, to limit the influence that such proxy preferences have on a model. Luckily, in many contexts such as medicine, education, and law, a sparse amount of expert data is often available. In these cases, it is often unclear whether the addition of proxy data can improve policy learning. We outline a set of sufficient conditions on proxy feedback that, if satisfied, indicate that proxy data can provably improve the sample complexity of learning the ground truth policy. These conditions can inform the data collection process for specific tasks. The result implies a parameterisation for LLMs that achieves this improved sample complexity. We detail how one can adapt existing architectures to yield this improved sample complexity.
Understanding Likelihood Over-optimisation in Direct Alignment Algorithms
Oct 15, 2024



Direct Alignment Algorithms (DAAs), such as Direct Preference Optimisation (DPO) and Identity Preference Optimisation (IPO), have emerged as alternatives to online Reinforcement Learning from Human Feedback (RLHF) algorithms such as Proximal Policy Optimisation (PPO) for aligning language models to human preferences, without the need for explicit reward modelling. These methods generally aim to increase the likelihood of generating better (preferred) completions while discouraging worse (non-preferred) ones, while staying close to the original model's behaviour. In this work, we explore the relationship between completion likelihood and model performance in state-of-the-art DAAs, and identify a critical issue of likelihood over-optimisation. Contrary to expectations, we find that higher likelihood of better completions and larger margins between better and worse completion likelihoods do not necessarily lead to better performance, and may even degrade it. Our analysis reveals that while higher likelihood correlates with better memorisation of factual knowledge patterns, a slightly lower completion likelihood tends to improve output diversity, thus leading to better generalisation to unseen scenarios. Moreover, we identify two key indicators that signal when over-optimised output diversity begins to harm performance: Decreasing Entropy over Top-k Tokens and Diminishing Top-k Probability Mass. Our experimental results validate that these indicators are reliable signs of declining performance under different regularisations, helping prevent over-optimisation and improve alignment with human preferences.
Understanding the Role of User Profile in the Personalization of Large Language Models
Jun 22, 2024



Utilizing user profiles to personalize Large Language Models (LLMs) has been shown to enhance the performance on a wide range of tasks. However, the precise role of user profiles and their effect mechanism on LLMs remains unclear. This study first confirms that the effectiveness of user profiles is primarily due to personalization information rather than semantic information. Furthermore, we investigate how user profiles affect the personalization of LLMs. Within the user profile, we reveal that it is the historical personalized response produced or approved by users that plays a pivotal role in personalizing LLMs. This discovery unlocks the potential of LLMs to incorporate a greater number of user profiles within the constraints of limited input length. As for the position of user profiles, we observe that user profiles integrated into different positions of the input context do not contribute equally to personalization. Instead, where the user profile that is closer to the beginning affects more on the personalization of LLMs. Our findings reveal the role of user profiles for the personalization of LLMs, and showcase how incorporating user profiles impacts performance providing insight to leverage user profiles effectively.
Instruction Tuning With Loss Over Instructions
May 23, 2024Instruction tuning plays a crucial role in shaping the outputs of language models (LMs) to desired styles. In this work, we propose a simple yet effective method, Instruction Modelling (IM), which trains LMs by applying a loss function to the instruction and prompt part rather than solely to the output part. Through experiments across 21 diverse benchmarks, we show that, in many scenarios, IM can effectively improve the LM performance on both NLP tasks (e.g., MMLU, TruthfulQA, and HumanEval) and open-ended generation benchmarks (e.g., MT-Bench and AlpacaEval). Remarkably, in the most advantageous case, IM boosts model performance on AlpacaEval 1.0 by over 100%. We identify two key factors influencing the effectiveness of IM: (1) The ratio between instruction length and output length in the training data; and (2) The number of training examples. We observe that IM is especially beneficial when trained on datasets with lengthy instructions paired with brief outputs, or under the Superficial Alignment Hypothesis (SAH) where a small amount of training examples are used for instruction tuning. Further analysis substantiates our hypothesis that the improvement can be attributed to reduced overfitting to instruction tuning datasets. Our work provides practical guidance for instruction tuning LMs, especially in low-resource scenarios.