 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCreativeBench: Benchmarking and Enhancing Machine Creativity via Self-Evolving Challenges
Mar 12, 2026The saturation of high-quality pre-training data has shifted research focus toward evolutionary systems capable of continuously generating novel artifacts, leading to the success of AlphaEvolve. However, the progress of such systems is hindered by the lack of rigorous, quantitative evaluation. To tackle this challenge, we introduce CreativeBench, a benchmark for evaluating machine creativity in code generation, grounded in a classical cognitive framework. Comprising two subsets -- CreativeBench-Combo and CreativeBench-Explore -- the benchmark targets combinatorial and exploratory creativity through an automated pipeline utilizing reverse engineering and self-play. By leveraging executable code, CreativeBench objectively distinguishes creativity from hallucination via a unified metric defined as the product of quality and novelty. Our analysis of state-of-the-art models reveals distinct behaviors: (1) scaling significantly improves combinatorial creativity but yields diminishing returns for exploration; (2) larger models exhibit ``convergence-by-scaling,'' becoming more correct but less divergent; and (3) reasoning capabilities primarily benefit constrained exploration rather than combination. Finally, we propose EvoRePE, a plug-and-play inference-time steering strategy that internalizes evolutionary search patterns to consistently enhance machine creativity.
Invariant Causal Routing for Governing Social Norms in Online Market Economies
Mar 04, 2026Social norms are stable behavioral patterns that emerge endogenously within economic systems through repeated interactions among agents. In online market economies, such norms -- like fair exposure, sustained participation, and balanced reinvestment -- are critical for long-term stability. We aim to understand the causal mechanisms driving these emergent norms and to design principled interventions that can steer them toward desired outcomes. This is challenging because norms arise from countless micro-level interactions that aggregate into macro-level regularities, making causal attribution and policy transferability difficult. To address this, we propose \textbf{Invariant Causal Routing (ICR)}, a causal governance framework that identifies policy-norm relations stable across heterogeneous environments. ICR integrates counterfactual reasoning with invariant causal discovery to separate genuine causal effects from spurious correlations and to construct interpretable, auditable policy rules that remain effective under distribution shift. In heterogeneous agent simulations calibrated with real data, ICR yields more stable norms, smaller generalization gaps, and more concise rules than correlation or coverage baselines, demonstrating that causal invariance offers a principled and interpretable foundation for governance.
Learning Generation Orders for Masked Discrete Diffusion Models via Variational Inference
Feb 27, 2026Masked discrete diffusion models (MDMs) are a promising new approach to generative modelling, offering the ability for parallel token generation and therefore greater efficiency than autoregressive counterparts. However, achieving an optimal balance between parallel generation and sample quality remains an open problem. Current approaches primarily address this issue through fixed, heuristic parallel sampling methods. There exist some recent learning based approaches to this problem, but its formulation from the perspective of variational inference remains underexplored. In this work, we propose a variational inference framework for learning parallel generation orders for MDMs. As part of our method, we propose a parameterisation for the approximate posterior of generation orders which facilitates parallelism and efficient sampling during training. Using this method, we conduct preliminary experiments on the GSM8K dataset, where our method performs competitively against heuristic sampling strategies in the regime of highly parallel generation. For example, our method achieves 33.1\% accuracy with an average of only only 4 generation steps, compared to 23.7-29.0\% accuracy achieved by standard competitor methods in the same number of steps. We believe further experiments and analysis of the method will yield valuable insights into the problem of parallel generation with MDMs.
Seeking Necessary and Sufficient Information from Multimodal Medical Data
Feb 27, 2026Learning multimodal representations from medical images and other data sources can provide richer information for decision-making. While various multimodal models have been developed for this, they overlook learning features that are both necessary (must be present for the outcome to occur) and sufficient (enough to determine the outcome). We argue learning such features is crucial as they can improve model performance by capturing essential predictive information, and enhance model robustness to missing modalities as each modality can provide adequate predictive signals. Such features can be learned by leveraging the Probability of Necessity and Sufficiency (PNS) as a learning objective, an approach that has proven effective in unimodal settings. However, extending PNS to multimodal scenarios remains underexplored and is non-trivial as key conditions of PNS estimation are violated. We address this by decomposing multimodal representations into modality-invariant and modality-specific components, then deriving tractable PNS objectives for each. Experiments on synthetic and real-world medical datasets demonstrate our method's effectiveness. Code will be available on GitHub.
A Very Big Video Reasoning Suite
Feb 24, 2026Rapid progress in video models has largely focused on visual quality, leaving their reasoning capabilities underexplored. Video reasoning grounds intelligence in spatiotemporally consistent visual environments that go beyond what text can naturally capture, enabling intuitive reasoning over spatiotemporal structure such as continuity, interaction, and causality. However, systematically studying video reasoning and its scaling behavior is hindered by the lack of large-scale training data. To address this gap, we introduce the Very Big Video Reasoning (VBVR) Dataset, an unprecedentedly large-scale resource spanning 200 curated reasoning tasks following a principled taxonomy and over one million video clips, approximately three orders of magnitude larger than existing datasets. We further present VBVR-Bench, a verifiable evaluation framework that moves beyond model-based judging by incorporating rule-based, human-aligned scorers, enabling reproducible and interpretable diagnosis of video reasoning capabilities. Leveraging the VBVR suite, we conduct one of the first large-scale scaling studies of video reasoning and observe early signs of emergent generalization to unseen reasoning tasks. Together, VBVR lays a foundation for the next stage of research in generalizable video reasoning. The data, benchmark toolkit, and models are publicly available at https://video-reason.com/ .
ProcMEM: Learning Reusable Procedural Memory from Experience via Non-Parametric PPO for LLM Agents
Feb 02, 2026LLM-driven agents demonstrate strong performance in sequential decision-making but often rely on on-the-fly reasoning, re-deriving solutions even in recurring scenarios. This insufficient experience reuse leads to computational redundancy and execution instability. To bridge this gap, we propose ProcMEM, a framework that enables agents to autonomously learn procedural memory from interaction experiences without parameter updates. By formalizing a Skill-MDP, ProcMEM transforms passive episodic narratives into executable Skills defined by activation, execution, and termination conditions to ensure executability. To achieve reliable reusability without capability degradation, we introduce Non-Parametric PPO, which leverages semantic gradients for high-quality candidate generation and a PPO Gate for robust Skill verification. Through score-based maintenance, ProcMEM sustains compact, high-quality procedural memory. Experimental results across in-domain, cross-task, and cross-agent scenarios demonstrate that ProcMEM achieves superior reuse rates and significant performance gains with extreme memory compression. Visualized evolutionary trajectories and Skill distributions further reveal how ProcMEM transparently accumulates, refines, and reuses procedural knowledge to facilitate long-term autonomy.
TriShGAN: Enhancing Sparsity and Robustness in Multivariate Time Series Counterfactuals Explanation
Nov 09, 2025In decision-making processes, stakeholders often rely on counterfactual explanations, which provide suggestions about what should be changed in the queried instance to alter the outcome of an AI system. However, generating these explanations for multivariate time series presents challenges due to their complex, multi-dimensional nature. Traditional Nearest Unlike Neighbor-based methods typically substitute subsequences in a queried time series with influential subsequences from an NUN, which is not always realistic in real-world scenarios due to the rigid direct substitution. Counterfactual with Residual Generative Adversarial Networks-based methods aim to address this by learning from the distribution of observed data to generate synthetic counterfactual explanations. However, these methods primarily focus on minimizing the cost from the queried time series to the counterfactual explanations and often neglect the importance of distancing the counterfactual explanation from the decision boundary. This oversight can result in explanations that no longer qualify as counterfactual if minor changes occur within the model. To generate a more robust counterfactual explanation, we introduce TriShGAN, under the CounteRGAN framework enhanced by the incorporation of triplet loss. This unsupervised learning approach uses distance metric learning to encourage the counterfactual explanations not only to remain close to the queried time series but also to capture the feature distribution of the instance with the desired outcome, thereby achieving a better balance between minimal cost and robustness. Additionally, we integrate a Shapelet Extractor that strategically selects the most discriminative parts of the high-dimensional queried time series to enhance the sparsity of counterfactual explanation and efficiency of the training process.
A Survey of Process Reward Models: From Outcome Signals to Process Supervisions for Large Language Models
Oct 09, 2025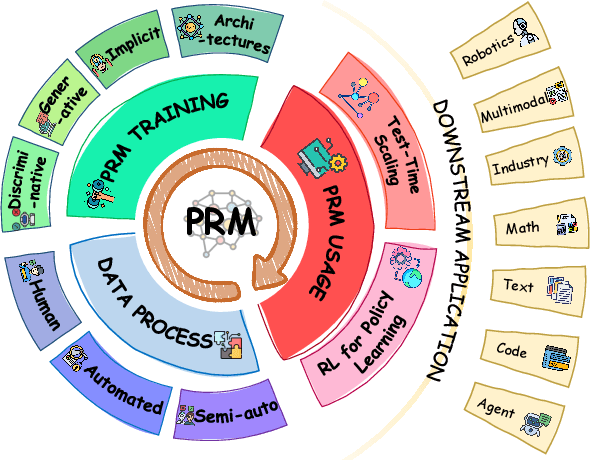

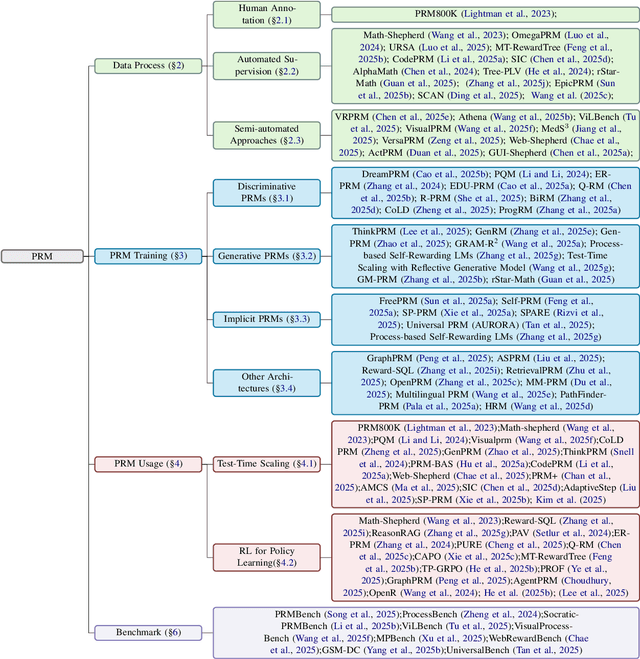
Although Large Language Models (LLMs) exhibit advanced reasoning ability, conventional alignment remains largely dominated by outcome reward models (ORMs) that judge only final answers. Process Reward Models(PRMs) address this gap by evaluating and guiding reasoning at the step or trajectory level. This survey provides a systematic overview of PRMs through the full loop: how to generate process data, build PRMs, and use PRMs for test-time scaling and reinforcement learning. We summarize applications across math, code, text, multimodal reasoning, robotics, and agents, and review emerging benchmarks. Our goal is to clarify design spaces, reveal open challenges, and guide future research toward fine-grained, robust reasoning alignment.
Causal Sufficiency and Necessity Improves Chain-of-Thought Reasoning
Jun 11, 2025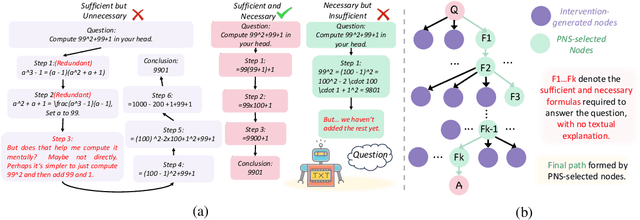
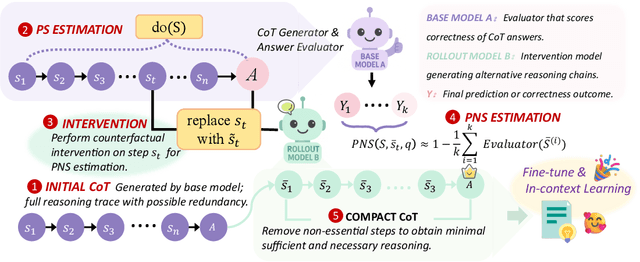
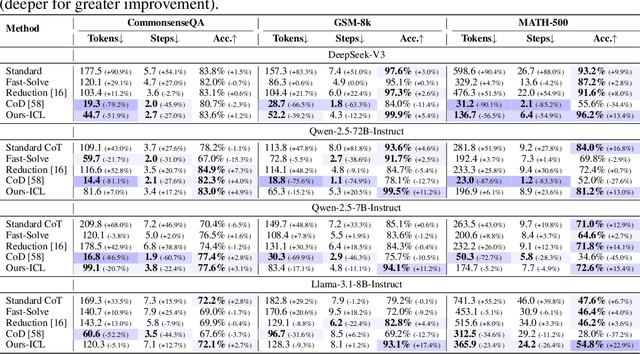
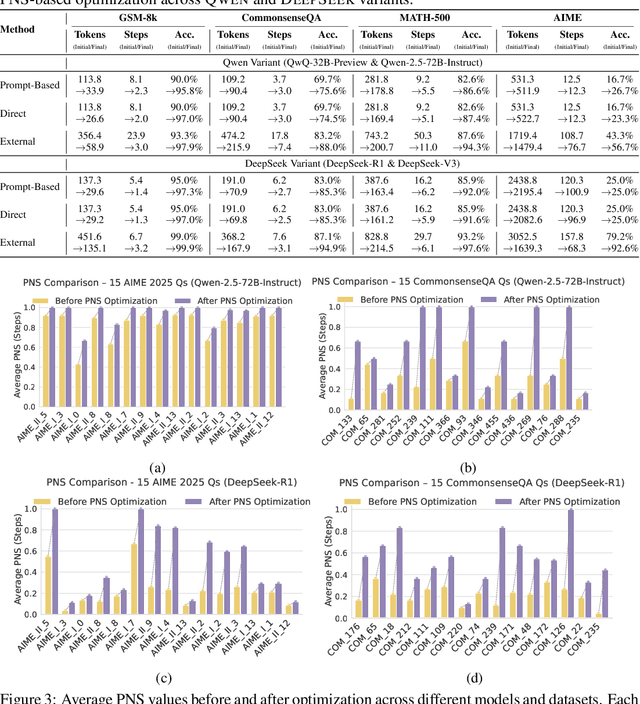
Chain-of-Thought (CoT) prompting plays an indispensable role in endowing large language models (LLMs) with complex reasoning capabilities. However, CoT currently faces two fundamental challenges: (1) Sufficiency, which ensures that the generated intermediate inference steps comprehensively cover and substantiate the final conclusion; and (2) Necessity, which identifies the inference steps that are truly indispensable for the soundness of the resulting answer. We propose a causal framework that characterizes CoT reasoning through the dual lenses of sufficiency and necessity. Incorporating causal Probability of Sufficiency and Necessity allows us not only to determine which steps are logically sufficient or necessary to the prediction outcome, but also to quantify their actual influence on the final reasoning outcome under different intervention scenarios, thereby enabling the automated addition of missing steps and the pruning of redundant ones. Extensive experimental results on various mathematical and commonsense reasoning benchmarks confirm substantial improvements in reasoning efficiency and reduced token usage without sacrificing accuracy. Our work provides a promising direction for improving LLM reasoning performance and cost-effectiveness.
Large Language Models are Demonstration Pre-Selectors for Themselves
Jun 06, 2025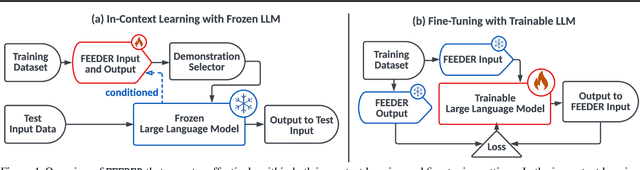
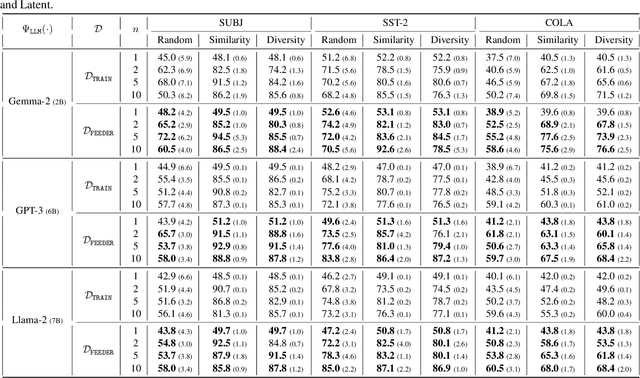
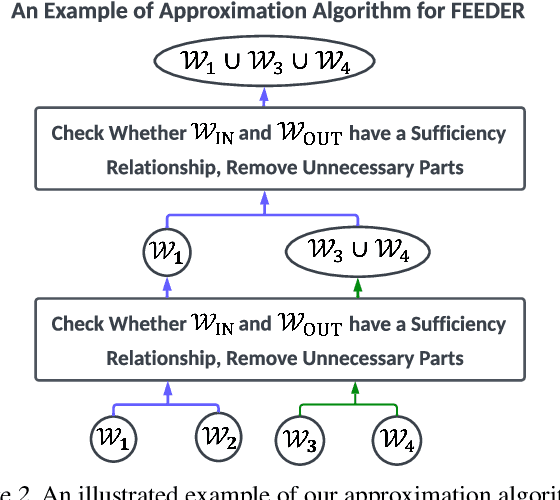
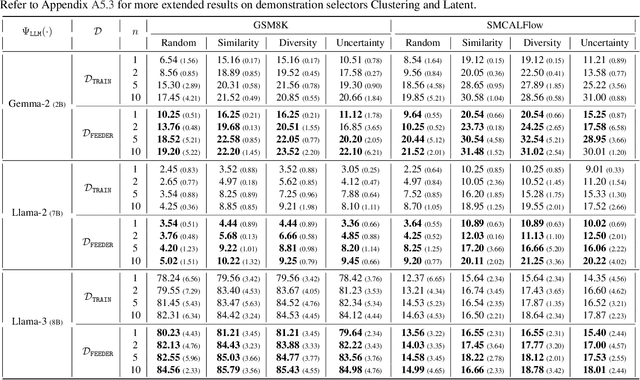
In-context learning (ICL) with large language models (LLMs) delivers strong few-shot performance by choosing few-shot demonstrations from the entire training data. However, existing ICL methods, which rely on similarity or diversity scores to choose demonstrations, incur high computational costs due to repeatedly retrieval from large-scale datasets for each query. To this end, we propose FEEDER (FEw yet Essential Demonstration prE-selectoR), a novel pre-selection framework that identifies a representative subset of demonstrations containing the most representative examples in the training data, tailored to specific LLMs. To construct this subset, we introduce the "sufficiency" and "necessity" metrics in the pre-selection stage and design a tree-based algorithm to identify representative examples efficiently. Once pre-selected, this representative subset can effectively replace the full training data, improving efficiency while maintaining comparable performance in ICL. Additionally, our pre-selected subset also benefits fine-tuning LLMs, where we introduce a bi-level optimization method that enhances training efficiency without sacrificing performance. Experiments with LLMs ranging from 300M to 8B parameters show that FEEDER can reduce training data size by over 20% while maintaining performance and seamlessly integrating with various downstream demonstration selection strategies in ICL.