 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMF-LLM: Simulating Collective Decision Dynamics via a Mean-Field Large Language Model Framework
Apr 30, 2025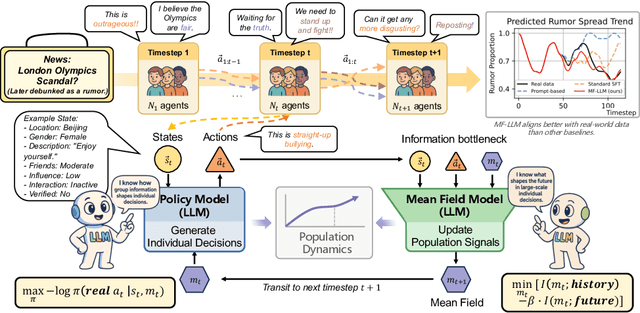
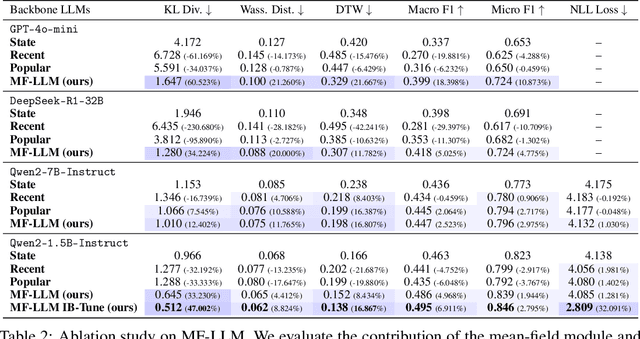
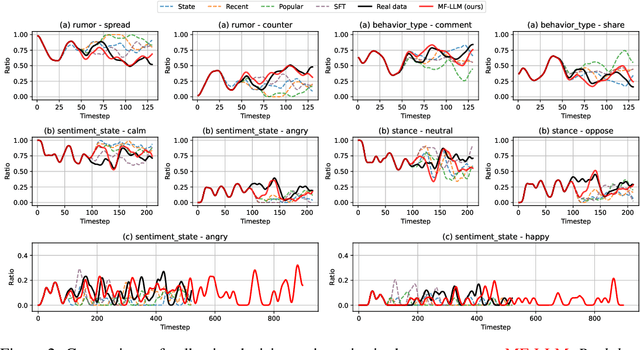

Simulating collective decision-making involves more than aggregating individual behaviors; it arises from dynamic interactions among individuals. While large language models (LLMs) show promise for social simulation, existing approaches often exhibit deviations from real-world data. To address this gap, we propose the Mean-Field LLM (MF-LLM) framework, which explicitly models the feedback loop between micro-level decisions and macro-level population. MF-LLM alternates between two models: a policy model that generates individual actions based on personal states and group-level information, and a mean field model that updates the population distribution from the latest individual decisions. Together, they produce rollouts that simulate the evolving trajectories of collective decision-making. To better match real-world data, we introduce IB-Tune, a fine-tuning method for LLMs grounded in the information bottleneck principle, which maximizes the relevance of population distributions to future actions while minimizing redundancy with historical data. We evaluate MF-LLM on a real-world social dataset, where it reduces KL divergence to human population distributions by 47 percent over non-mean-field baselines, and enables accurate trend forecasting and intervention planning. It generalizes across seven domains and four LLM backbones, providing a scalable foundation for high-fidelity social simulation.
Vairiational Stochastic Games
Mar 08, 2025The Control as Inference (CAI) framework has successfully transformed single-agent reinforcement learning (RL) by reframing control tasks as probabilistic inference problems. However, the extension of CAI to multi-agent, general-sum stochastic games (SGs) remains underexplored, particularly in decentralized settings where agents operate independently without centralized coordination. In this paper, we propose a novel variational inference framework tailored to decentralized multi-agent systems. Our framework addresses the challenges posed by non-stationarity and unaligned agent objectives, proving that the resulting policies form an $\epsilon$-Nash equilibrium. Additionally, we demonstrate theoretical convergence guarantees for the proposed decentralized algorithms. Leveraging this framework, we instantiate multiple algorithms to solve for Nash equilibrium, mean-field Nash equilibrium, and correlated equilibrium, with rigorous theoretical convergence analysis.
AWT: Transferring Vision-Language Models via Augmentation, Weighting, and Transportation
Jul 05, 2024Pre-trained vision-language models (VLMs) have shown impressive results in various visual classification tasks. However, we often fail to fully unleash their potential when adapting them for new concept understanding due to limited information on new classes. To address this limitation, we introduce a novel adaptation framework, AWT (Augment, Weight, then Transport). AWT comprises three key components: augmenting inputs with diverse visual perspectives and enriched class descriptions through image transformations and language models; dynamically weighting inputs based on the prediction entropy; and employing optimal transport to mine semantic correlations in the vision-language space. AWT can be seamlessly integrated into various VLMs, enhancing their zero-shot capabilities without additional training and facilitating few-shot learning through an integrated multimodal adapter module. We verify AWT in multiple challenging scenarios, including zero-shot and few-shot image classification, zero-shot video action recognition, and out-of-distribution generalization. AWT consistently outperforms the state-of-the-art methods in each setting. In addition, our extensive studies further demonstrate AWT's effectiveness and adaptability across different VLMs, architectures, and scales.
Learning Macroeconomic Policies based on Microfoundations: A Stackelberg Mean Field Game Approach
Mar 14, 2024Effective macroeconomic policies play a crucial role in promoting economic growth and social stability. This paper models the optimal macroeconomic policy problem based on the \textit{Stackelberg Mean Field Game} (SMFG), where the government acts as the leader in policy-making, and large-scale households dynamically respond as followers. This modeling method captures the asymmetric dynamic game between the government and large-scale households, and interpretably evaluates the effects of macroeconomic policies based on microfoundations, which is difficult for existing methods to achieve. We also propose a solution for SMFGs, incorporating pre-training on real data and a model-free \textit{Stackelberg mean-field reinforcement learning }(SMFRL) algorithm, which operates independently of prior environmental knowledge and transitions. Our experimental results showcase the superiority of the SMFG method over other economic policies in terms of performance, efficiency-equity tradeoff, and SMFG assumption analysis. This paper significantly contributes to the domain of AI for economics by providing a powerful tool for modeling and solving optimal macroeconomic policies.
Asymmetric Masked Distillation for Pre-Training Small Foundation Models
Nov 06, 2023
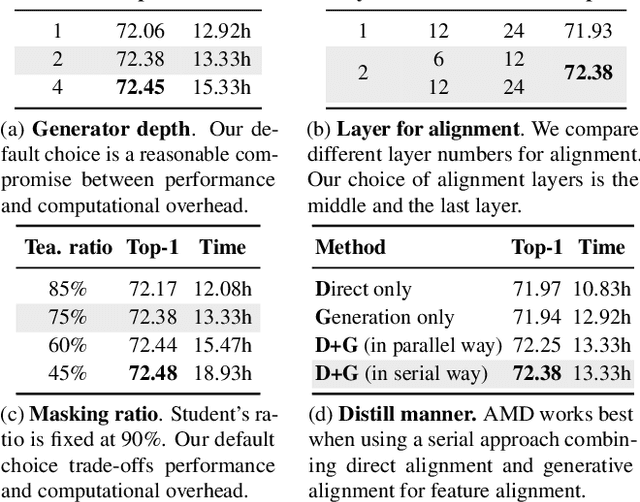


Self-supervised foundation models have shown great potential in computer vision thanks to the pre-training paradigm of masked autoencoding. Scale is a primary factor influencing the performance of these foundation models. However, these large foundation models often result in high computational cost that might limit their deployment. This paper focuses on pre-training relatively small vision transformer models that could be efficiently adapted to downstream tasks. Specifically, taking inspiration from knowledge distillation in model compression, we propose a new asymmetric masked distillation(AMD) framework for pre-training relatively small models with autoencoding. The core of AMD is to devise an asymmetric masking strategy, where the teacher model is enabled to see more context information with a lower masking ratio, while the student model still with high masking ratio to the original masked pre-training. We design customized multi-layer feature alignment between the teacher encoder and student encoder to regularize the pre-training of student MAE. To demonstrate the effectiveness and versatility of AMD, we apply it to both ImageMAE and VideoMAE for pre-training relatively small ViT models. AMD achieved 84.6% classification accuracy on IN1K using the ViT-B model. And AMD achieves 73.3% classification accuracy using the ViT-B model on the Something-in-Something V2 dataset, a 3.7% improvement over the original ViT-B model from VideoMAE. We also transfer AMD pre-trained models to downstream tasks and obtain consistent performance improvement over the standard pre-training.
MGMAE: Motion Guided Masking for Video Masked Autoencoding
Aug 21, 2023Masked autoencoding has shown excellent performance on self-supervised video representation learning. Temporal redundancy has led to a high masking ratio and customized masking strategy in VideoMAE. In this paper, we aim to further improve the performance of video masked autoencoding by introducing a motion guided masking strategy. Our key insight is that motion is a general and unique prior in video, which should be taken into account during masked pre-training. Our motion guided masking explicitly incorporates motion information to build temporal consistent masking volume. Based on this masking volume, we can track the unmasked tokens in time and sample a set of temporal consistent cubes from videos. These temporal aligned unmasked tokens will further relieve the information leakage issue in time and encourage the MGMAE to learn more useful structure information. We implement our MGMAE with an online efficient optical flow estimator and backward masking map warping strategy. We perform experiments on the datasets of Something-Something V2 and Kinetics-400, demonstrating the superior performance of our MGMAE to the original VideoMAE. In addition, we provide the visualization analysis to illustrate that our MGMAE can sample temporal consistent cubes in a motion-adaptive manner for more effective video pre-training.
VideoMAE V2: Scaling Video Masked Autoencoders with Dual Masking
Apr 18, 2023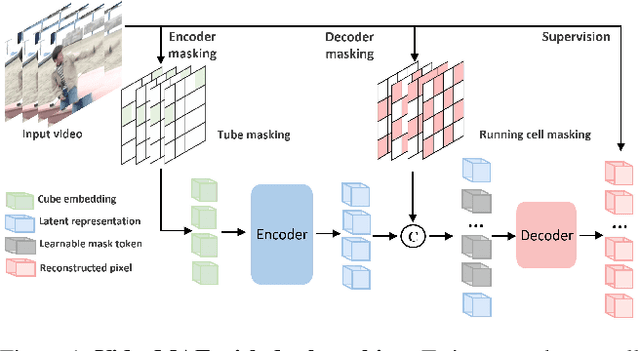



Scale is the primary factor for building a powerful foundation model that could well generalize to a variety of downstream tasks. However, it is still challenging to train video foundation models with billions of parameters. This paper shows that video masked autoencoder (VideoMAE) is a scalable and general self-supervised pre-trainer for building video foundation models. We scale the VideoMAE in both model and data with a core design. Specifically, we present a dual masking strategy for efficient pre-training, with an encoder operating on a subset of video tokens and a decoder processing another subset of video tokens. Although VideoMAE is very efficient due to high masking ratio in encoder, masking decoder can still further reduce the overall computational cost. This enables the efficient pre-training of billion-level models in video. We also use a progressive training paradigm that involves an initial pre-training on a diverse multi-sourced unlabeled dataset, followed by a post-pre-training on a mixed labeled dataset. Finally, we successfully train a video ViT model with a billion parameters, which achieves a new state-of-the-art performance on the datasets of Kinetics (90.0% on K400 and 89.9% on K600) and Something-Something (68.7% on V1 and 77.0% on V2). In addition, we extensively verify the pre-trained video ViT models on a variety of downstream tasks, demonstrating its effectiveness as a general video representation learner. The code and model is available at \url{https://github.com/OpenGVLab/VideoMAEv2}.
InternVideo: General Video Foundation Models via Generative and Discriminative Learning
Dec 07, 2022The foundation models have recently shown excellent performance on a variety of downstream tasks in computer vision. However, most existing vision foundation models simply focus on image-level pretraining and adpation, which are limited for dynamic and complex video-level understanding tasks. To fill the gap, we present general video foundation models, InternVideo, by taking advantage of both generative and discriminative self-supervised video learning. Specifically, InternVideo efficiently explores masked video modeling and video-language contrastive learning as the pretraining objectives, and selectively coordinates video representations of these two complementary frameworks in a learnable manner to boost various video applications. Without bells and whistles, InternVideo achieves state-of-the-art performance on 39 video datasets from extensive tasks including video action recognition/detection, video-language alignment, and open-world video applications. Especially, our methods can obtain 91.1% and 77.2% top-1 accuracy on the challenging Kinetics-400 and Something-Something V2 benchmarks, respectively. All of these results effectively show the generality of our InternVideo for video understanding. The code will be released at https://github.com/OpenGVLab/InternVideo .
InternVideo-Ego4D: A Pack of Champion Solutions to Ego4D Challenges
Nov 17, 2022



In this report, we present our champion solutions to five tracks at Ego4D challenge. We leverage our developed InternVideo, a video foundation model, for five Ego4D tasks, including Moment Queries, Natural Language Queries, Future Hand Prediction, State Change Object Detection, and Short-term Object Interaction Anticipation. InternVideo-Ego4D is an effective paradigm to adapt the strong foundation model to the downstream ego-centric video understanding tasks with simple head designs. In these five tasks, the performance of InternVideo-Ego4D comprehensively surpasses the baseline methods and the champions of CVPR2022, demonstrating the powerful representation ability of InternVideo as a video foundation model. Our code will be released at https://github.com/OpenGVLab/ego4d-eccv2022-solutions