 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEchoReview: Learning Peer Review from the Echoes of Scientific Citations
Jan 31, 2026As the volume of scientific submissions continues to grow rapidly, traditional peer review systems are facing unprecedented scalability pressures, highlighting the urgent need for automated reviewing methods that are both scalable and reliable. Existing supervised fine-tuning approaches based on real review data are fundamentally constrained by single-source of data as well as the inherent subjectivity and inconsistency of human reviews, limiting their ability to support high-quality automated reviewers. To address these issues, we propose EchoReview, a citation-context-driven data synthesis framework that systematically mines implicit collective evaluative signals from academic citations and transforms scientific community's long-term judgments into structured review-style data. Based on this pipeline, we construct EchoReview-16K, the first large-scale, cross-conference, and cross-year citation-driven review dataset, and train an automated reviewer, EchoReviewer-7B. Experimental results demonstrate that EchoReviewer-7B can achieve significant and stable improvements on core review dimensions such as evidence support and review comprehensiveness, validating citation context as a robust and effective data paradigm for reliable automated peer review.
P1: Mastering Physics Olympiads with Reinforcement Learning
Nov 17, 2025Recent progress in large language models (LLMs) has moved the frontier from puzzle-solving to science-grade reasoning-the kind needed to tackle problems whose answers must stand against nature, not merely fit a rubric. Physics is the sharpest test of this shift, which binds symbols to reality in a fundamental way, serving as the cornerstone of most modern technologies. In this work, we manage to advance physics research by developing large language models with exceptional physics reasoning capabilities, especially excel at solving Olympiad-level physics problems. We introduce P1, a family of open-source physics reasoning models trained entirely through reinforcement learning (RL). Among them, P1-235B-A22B is the first open-source model with Gold-medal performance at the latest International Physics Olympiad (IPhO 2025), and wins 12 gold medals out of 13 international/regional physics competitions in 2024/2025. P1-30B-A3B also surpasses almost all other open-source models on IPhO 2025, getting a silver medal. Further equipped with an agentic framework PhysicsMinions, P1-235B-A22B+PhysicsMinions achieves overall No.1 on IPhO 2025, and obtains the highest average score over the 13 physics competitions. Besides physics, P1 models also present great performance on other reasoning tasks like math and coding, showing the great generalibility of P1 series.
Discrete Diffusion VLA: Bringing Discrete Diffusion to Action Decoding in Vision-Language-Action Policies
Aug 27, 2025Vision-Language-Action (VLA) models adapt large vision-language backbones to map images and instructions to robot actions. However, prevailing VLA decoders either generate actions autoregressively in a fixed left-to-right order or attach continuous diffusion or flow matching heads outside the backbone, demanding specialized training and iterative sampling that hinder a unified, scalable architecture. We present Discrete Diffusion VLA, a single-transformer policy that models discretized action chunks with discrete diffusion and is trained with the same cross-entropy objective as the VLM backbone. The design retains diffusion's progressive refinement paradigm while remaining natively compatible with the discrete token interface of VLMs. Our method achieves an adaptive decoding order that resolves easy action elements before harder ones and uses secondary remasking to revisit uncertain predictions across refinement rounds, which improves consistency and enables robust error correction. This unified decoder preserves pretrained vision language priors, supports parallel decoding, breaks the autoregressive bottleneck, and reduces the number of function evaluations. Discrete Diffusion VLA achieves 96.3% avg. SR on LIBERO, 71.2% visual matching on SimplerEnv Fractal and 49.3% overall on SimplerEnv Bridge, improving over both autoregressive and continuous diffusion baselines. These findings indicate that discrete-diffusion action decoder supports precise action modeling and consistent training, laying groundwork for scaling VLA to larger models and datasets.
ARC-Hunyuan-Video-7B: Structured Video Comprehension of Real-World Shorts
Jul 28, 2025Real-world user-generated short videos, especially those distributed on platforms such as WeChat Channel and TikTok, dominate the mobile internet. However, current large multimodal models lack essential temporally-structured, detailed, and in-depth video comprehension capabilities, which are the cornerstone of effective video search and recommendation, as well as emerging video applications. Understanding real-world shorts is actually challenging due to their complex visual elements, high information density in both visuals and audio, and fast pacing that focuses on emotional expression and viewpoint delivery. This requires advanced reasoning to effectively integrate multimodal information, including visual, audio, and text. In this work, we introduce ARC-Hunyuan-Video, a multimodal model that processes visual, audio, and textual signals from raw video inputs end-to-end for structured comprehension. The model is capable of multi-granularity timestamped video captioning and summarization, open-ended video question answering, temporal video grounding, and video reasoning. Leveraging high-quality data from an automated annotation pipeline, our compact 7B-parameter model is trained through a comprehensive regimen: pre-training, instruction fine-tuning, cold start, reinforcement learning (RL) post-training, and final instruction fine-tuning. Quantitative evaluations on our introduced benchmark ShortVid-Bench and qualitative comparisons demonstrate its strong performance in real-world video comprehension, and it supports zero-shot or fine-tuning with a few samples for diverse downstream applications. The real-world production deployment of our model has yielded tangible and measurable improvements in user engagement and satisfaction, a success supported by its remarkable efficiency, with stress tests indicating an inference time of just 10 seconds for a one-minute video on H20 GPU.
Aligning Latent Spaces with Flow Priors
Jun 05, 2025This paper presents a novel framework for aligning learnable latent spaces to arbitrary target distributions by leveraging flow-based generative models as priors. Our method first pretrains a flow model on the target features to capture the underlying distribution. This fixed flow model subsequently regularizes the latent space via an alignment loss, which reformulates the flow matching objective to treat the latents as optimization targets. We formally prove that minimizing this alignment loss establishes a computationally tractable surrogate objective for maximizing a variational lower bound on the log-likelihood of latents under the target distribution. Notably, the proposed method eliminates computationally expensive likelihood evaluations and avoids ODE solving during optimization. As a proof of concept, we demonstrate in a controlled setting that the alignment loss landscape closely approximates the negative log-likelihood of the target distribution. We further validate the effectiveness of our approach through large-scale image generation experiments on ImageNet with diverse target distributions, accompanied by detailed discussions and ablation studies. With both theoretical and empirical validation, our framework paves a new way for latent space alignment.
Beamforming Design for Beyond Diagonal RIS-Aided Cell-Free Massive MIMO Systems
Mar 10, 2025

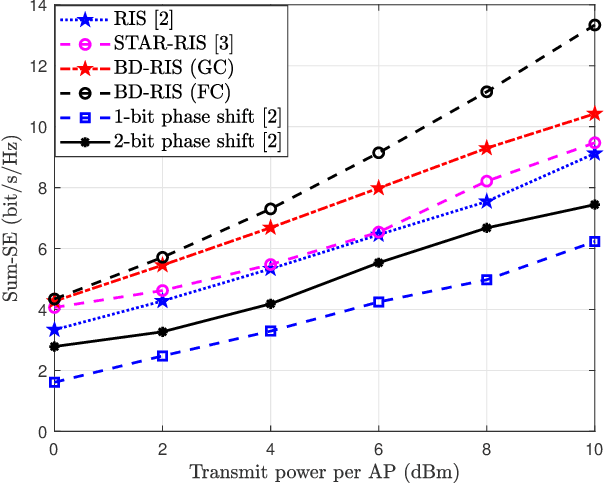

Reconfigurable intelligent surface (RIS)-aided cell-free (CF) massive multiple-input multiple-output (mMIMO) is a promising architecture for further improving spectral efficiency (SE) with low cost and power consumption. However, conventional RIS has inevitable limitations due to its capability of only reflecting signals. In contrast, beyond-diagonal RIS (BD-RIS), with its ability to both reflect and transmit signals, has gained great attention. This correspondence focuses on using BD-RIS to improve the sum SE of CF mMIMO systems. This requires completing the beamforming design under the transmit power constraints and unitary constraints of the BD-RIS, by optimizing active and passive beamformer simultaneously. To tackle this issue, we introduce an alternating optimization algorithm that decomposes it using fractional programming and solves the subproblems alternatively. Moreover, to address the challenge introduced by the unitary constraint on the beamforming matrix of the BD-RIS, a manifold optimization algorithm is proposed to solve the problem optimally. Simulation results show that BD-RISs outperform RISs comprehensively, especially in the case of the full connected architecture which achieves the best performance, enhancing the sum SE by around 40% compared to ideal RISs.
Divot: Diffusion Powers Video Tokenizer for Comprehension and Generation
Dec 05, 2024



In recent years, there has been a significant surge of interest in unifying image comprehension and generation within Large Language Models (LLMs). This growing interest has prompted us to explore extending this unification to videos. The core challenge lies in developing a versatile video tokenizer that captures both the spatial characteristics and temporal dynamics of videos to obtain representations for LLMs, and the representations can be further decoded into realistic video clips to enable video generation. In this work, we introduce Divot, a Diffusion-Powered Video Tokenizer, which leverages the diffusion process for self-supervised video representation learning. We posit that if a video diffusion model can effectively de-noise video clips by taking the features of a video tokenizer as the condition, then the tokenizer has successfully captured robust spatial and temporal information. Additionally, the video diffusion model inherently functions as a de-tokenizer, decoding videos from their representations. Building upon the Divot tokenizer, we present Divot-Vicuna through video-to-text autoregression and text-to-video generation by modeling the distributions of continuous-valued Divot features with a Gaussian Mixture Model. Experimental results demonstrate that our diffusion-based video tokenizer, when integrated with a pre-trained LLM, achieves competitive performance across various video comprehension and generation benchmarks. The instruction tuned Divot-Vicuna also excels in video storytelling, generating interleaved narratives and corresponding videos.
DiCoDe: Diffusion-Compressed Deep Tokens for Autoregressive Video Generation with Language Models
Dec 05, 2024Videos are inherently temporal sequences by their very nature. In this work, we explore the potential of modeling videos in a chronological and scalable manner with autoregressive (AR) language models, inspired by their success in natural language processing. We introduce DiCoDe, a novel approach that leverages Diffusion-Compressed Deep Tokens to generate videos with a language model in an autoregressive manner. Unlike existing methods that employ low-level representations with limited compression rates, DiCoDe utilizes deep tokens with a considerable compression rate (a 1000x reduction in token count). This significant compression is made possible by a tokenizer trained through leveraging the prior knowledge of video diffusion models. Deep tokens enable DiCoDe to employ vanilla AR language models for video generation, akin to translating one visual "language" into another. By treating videos as temporal sequences, DiCoDe fully harnesses the capabilities of language models for autoregressive generation. DiCoDe is scalable using readily available AR architectures, and is capable of generating videos ranging from a few seconds to one minute using only 4 A100 GPUs for training. We evaluate DiCoDe both quantitatively and qualitatively, demonstrating that it performs comparably to existing methods in terms of quality while ensuring efficient training. To showcase its scalability, we release a series of DiCoDe configurations with varying parameter sizes and observe a consistent improvement in performance as the model size increases from 100M to 3B. We believe that DiCoDe's exploration in academia represents a promising initial step toward scalable video modeling with AR language models, paving the way for the development of larger and more powerful video generation models.
Moto: Latent Motion Token as the Bridging Language for Robot Manipulation
Dec 05, 2024



Recent developments in Large Language Models pre-trained on extensive corpora have shown significant success in various natural language processing tasks with minimal fine-tuning. This success offers new promise for robotics, which has long been constrained by the high cost of action-labeled data. We ask: given the abundant video data containing interaction-related knowledge available as a rich "corpus", can a similar generative pre-training approach be effectively applied to enhance robot learning? The key challenge is to identify an effective representation for autoregressive pre-training that benefits robot manipulation tasks. Inspired by the way humans learn new skills through observing dynamic environments, we propose that effective robotic learning should emphasize motion-related knowledge, which is closely tied to low-level actions and is hardware-agnostic, facilitating the transfer of learned motions to actual robot actions. To this end, we introduce Moto, which converts video content into latent Motion Token sequences by a Latent Motion Tokenizer, learning a bridging "language" of motion from videos in an unsupervised manner. We pre-train Moto-GPT through motion token autoregression, enabling it to capture diverse visual motion knowledge. After pre-training, Moto-GPT demonstrates the promising ability to produce semantically interpretable motion tokens, predict plausible motion trajectories, and assess trajectory rationality through output likelihood. To transfer learned motion priors to real robot actions, we implement a co-fine-tuning strategy that seamlessly bridges latent motion token prediction and real robot control. Extensive experiments show that the fine-tuned Moto-GPT exhibits superior robustness and efficiency on robot manipulation benchmarks, underscoring its effectiveness in transferring knowledge from video data to downstream visual manipulation tasks.
MVBench: A Comprehensive Multi-modal Video Understanding Benchmark
Dec 03, 2023



With the rapid development of Multi-modal Large Language Models (MLLMs), a number of diagnostic benchmarks have recently emerged to evaluate the comprehension capabilities of these models. However, most benchmarks predominantly assess spatial understanding in the static image tasks, while overlooking temporal understanding in the dynamic video tasks. To alleviate this issue, we introduce a comprehensive Multi-modal Video understanding Benchmark, namely MVBench, which covers 20 challenging video tasks that cannot be effectively solved with a single frame. Specifically, we first introduce a novel static-to-dynamic method to define these temporal-related tasks. By transforming various static tasks into dynamic ones, we enable the systematic generation of video tasks that require a broad spectrum of temporal skills, ranging from perception to cognition. Then, guided by the task definition, we automatically convert public video annotations into multiple-choice QA to evaluate each task. On one hand, such a distinct paradigm allows us to build MVBench efficiently, without much manual intervention. On the other hand, it guarantees evaluation fairness with ground-truth video annotations, avoiding the biased scoring of LLMs. Moreover, we further develop a robust video MLLM baseline, i.e., VideoChat2, by progressive multi-modal training with diverse instruction-tuning data. The extensive results on our MVBench reveal that, the existing MLLMs are far from satisfactory in temporal understanding, while our VideoChat2 largely surpasses these leading models by over 15% on MVBench. All models and data are available at https://github.com/OpenGVLab/Ask-Anything.