 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideoChat: Chat-Centric Video Understanding
May 10, 2023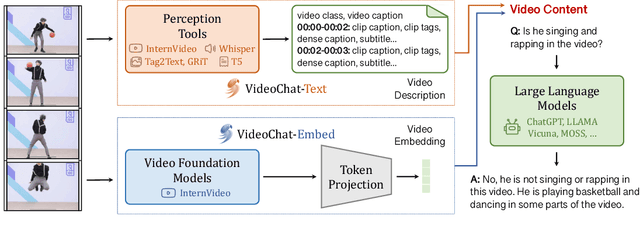



In this study, we initiate an exploration into video understanding by introducing VideoChat, an end-to-end chat-centric video understanding system. It integrates video foundation models and large language models via a learnable neural interface, excelling in spatiotemporal reasoning, event localization, and causal relationship inference. To instructively tune this system, we propose a video-centric instruction dataset, composed of thousands of videos matched with detailed descriptions and conversations. This dataset emphasizes spatiotemporal reasoning and causal relationships, providing a valuable asset for training chat-centric video understanding systems. Preliminary qualitative experiments reveal our system's potential across a broad spectrum of video applications and set the standard for future research. Access our code and data at https://github.com/OpenGVLab/Ask-Anything