 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unified Complementarity-based Approach for Rigid-Body Manipulation and Motion Prediction
Feb 04, 2026Robotic manipulation in unstructured environments requires planners to reason jointly about free-space motion and sustained, frictional contact with the environment. Existing (local) planning and simulation frameworks typically separate these regimes or rely on simplified contact representations, particularly when modeling non-convex or distributed contact patches. Such approximations limit the fidelity of contact-mode transitions and hinder the robust execution of contact-rich behaviors in real time. This paper presents a unified discrete-time modeling framework for robotic manipulation that consistently captures both free motion and frictional contact within a single mathematical formalism (Unicomp). Building on complementarity-based rigid-body dynamics, we formulate free-space motion and contact interactions as coupled linear and nonlinear complementarity problems, enabling principled transitions between contact modes without enforcing fixed-contact assumptions. For planar patch contact, we derive a frictional contact model from the maximum power dissipation principle in which the set of admissible contact wrenches is represented by an ellipsoidal limit surface. This representation captures coupled force-moment effects, including torsional friction, while remaining agnostic to the underlying pressure distribution across the contact patch. The resulting formulation yields a discrete-time predictive model that relates generalized velocities and contact wrenches through quadratic constraints and is suitable for real-time optimization-based planning. Experimental results show that the proposed approach enables stable, physically consistent behavior at interactive speeds across tasks, from planar pushing to contact-rich whole-body maneuvers.
Contact-Safe Reinforcement Learning with ProMP Reparameterization and Energy Awareness
Nov 17, 2025Reinforcement learning (RL) approaches based on Markov Decision Processes (MDPs) are predominantly applied in the robot joint space, often relying on limited task-specific information and partial awareness of the 3D environment. In contrast, episodic RL has demonstrated advantages over traditional MDP-based methods in terms of trajectory consistency, task awareness, and overall performance in complex robotic tasks. Moreover, traditional step-wise and episodic RL methods often neglect the contact-rich information inherent in task-space manipulation, especially considering the contact-safety and robustness. In this work, contact-rich manipulation tasks are tackled using a task-space, energy-safe framework, where reliable and safe task-space trajectories are generated through the combination of Proximal Policy Optimization (PPO) and movement primitives. Furthermore, an energy-aware Cartesian Impedance Controller objective is incorporated within the proposed framework to ensure safe interactions between the robot and the environment. Our experimental results demonstrate that the proposed framework outperforms existing methods in handling tasks on various types of surfaces in 3D environments, achieving high success rates as well as smooth trajectories and energy-safe interactions.
Prompt2Auto: From Motion Prompt to Automated Control via Geometry-Invariant One-Shot Gaussian Process Learning
Sep 17, 2025Learning from demonstration allows robots to acquire complex skills from human demonstrations, but conventional approaches often require large datasets and fail to generalize across coordinate transformations. In this paper, we propose Prompt2Auto, a geometry-invariant one-shot Gaussian process (GeoGP) learning framework that enables robots to perform human-guided automated control from a single motion prompt. A dataset-construction strategy based on coordinate transformations is introduced that enforces invariance to translation, rotation, and scaling, while supporting multi-step predictions. Moreover, GeoGP is robust to variations in the user's motion prompt and supports multi-skill autonomy. We validate the proposed approach through numerical simulations with the designed user graphical interface and two real-world robotic experiments, which demonstrate that the proposed method is effective, generalizes across tasks, and significantly reduces the demonstration burden. Project page is available at: https://prompt2auto.github.io
Manipulator for people with limited abilities
Aug 09, 2025The topic of this final qualification work was chosen due to the importance of developing robotic systems designed to assist people with disabilities. Advances in robotics and automation technologies have opened up new prospects for creating devices that can significantly improve the quality of life for these people. In this context, designing a robotic hand with a control system adapted to the needs of people with disabilities is a major scientific and practical challenge. This work addresses the problem of developing and manufacturing a four-degree-of-freedom robotic hand suitable for practical manipulation. Addressing this issue requires a comprehensive approach, encompassing the design of the hand's mechanical structure, the development of its control system, and its integration with a technical vision system and software based on the Robot Operating System (ROS).
Asymmetric Masked Distillation for Pre-Training Small Foundation Models
Nov 06, 2023
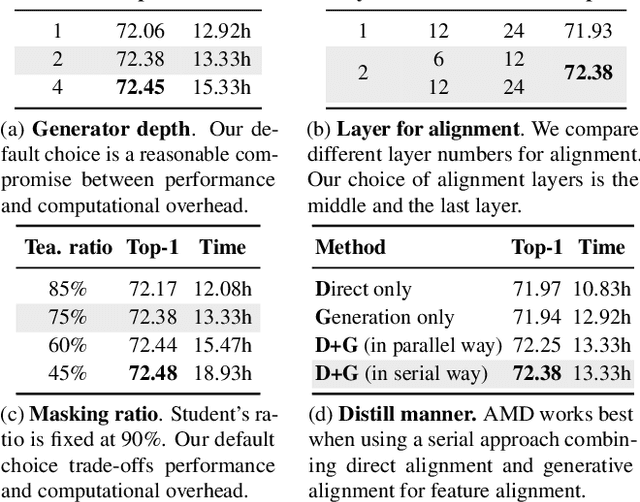


Self-supervised foundation models have shown great potential in computer vision thanks to the pre-training paradigm of masked autoencoding. Scale is a primary factor influencing the performance of these foundation models. However, these large foundation models often result in high computational cost that might limit their deployment. This paper focuses on pre-training relatively small vision transformer models that could be efficiently adapted to downstream tasks. Specifically, taking inspiration from knowledge distillation in model compression, we propose a new asymmetric masked distillation(AMD) framework for pre-training relatively small models with autoencoding. The core of AMD is to devise an asymmetric masking strategy, where the teacher model is enabled to see more context information with a lower masking ratio, while the student model still with high masking ratio to the original masked pre-training. We design customized multi-layer feature alignment between the teacher encoder and student encoder to regularize the pre-training of student MAE. To demonstrate the effectiveness and versatility of AMD, we apply it to both ImageMAE and VideoMAE for pre-training relatively small ViT models. AMD achieved 84.6% classification accuracy on IN1K using the ViT-B model. And AMD achieves 73.3% classification accuracy using the ViT-B model on the Something-in-Something V2 dataset, a 3.7% improvement over the original ViT-B model from VideoMAE. We also transfer AMD pre-trained models to downstream tasks and obtain consistent performance improvement over the standard pre-training.
MGMAE: Motion Guided Masking for Video Masked Autoencoding
Aug 21, 2023Masked autoencoding has shown excellent performance on self-supervised video representation learning. Temporal redundancy has led to a high masking ratio and customized masking strategy in VideoMAE. In this paper, we aim to further improve the performance of video masked autoencoding by introducing a motion guided masking strategy. Our key insight is that motion is a general and unique prior in video, which should be taken into account during masked pre-training. Our motion guided masking explicitly incorporates motion information to build temporal consistent masking volume. Based on this masking volume, we can track the unmasked tokens in time and sample a set of temporal consistent cubes from videos. These temporal aligned unmasked tokens will further relieve the information leakage issue in time and encourage the MGMAE to learn more useful structure information. We implement our MGMAE with an online efficient optical flow estimator and backward masking map warping strategy. We perform experiments on the datasets of Something-Something V2 and Kinetics-400, demonstrating the superior performance of our MGMAE to the original VideoMAE. In addition, we provide the visualization analysis to illustrate that our MGMAE can sample temporal consistent cubes in a motion-adaptive manner for more effective video pre-training.
VideoMAE V2: Scaling Video Masked Autoencoders with Dual Masking
Apr 18, 2023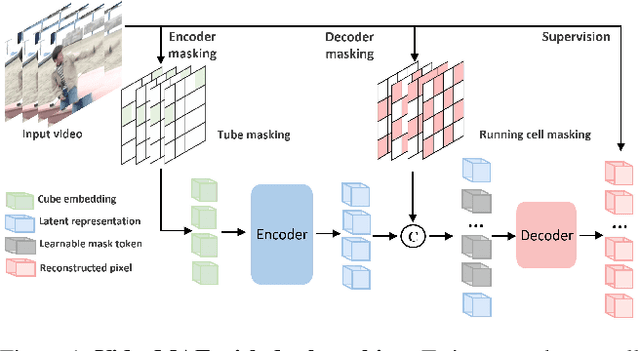



Scale is the primary factor for building a powerful foundation model that could well generalize to a variety of downstream tasks. However, it is still challenging to train video foundation models with billions of parameters. This paper shows that video masked autoencoder (VideoMAE) is a scalable and general self-supervised pre-trainer for building video foundation models. We scale the VideoMAE in both model and data with a core design. Specifically, we present a dual masking strategy for efficient pre-training, with an encoder operating on a subset of video tokens and a decoder processing another subset of video tokens. Although VideoMAE is very efficient due to high masking ratio in encoder, masking decoder can still further reduce the overall computational cost. This enables the efficient pre-training of billion-level models in video. We also use a progressive training paradigm that involves an initial pre-training on a diverse multi-sourced unlabeled dataset, followed by a post-pre-training on a mixed labeled dataset. Finally, we successfully train a video ViT model with a billion parameters, which achieves a new state-of-the-art performance on the datasets of Kinetics (90.0% on K400 and 89.9% on K600) and Something-Something (68.7% on V1 and 77.0% on V2). In addition, we extensively verify the pre-trained video ViT models on a variety of downstream tasks, demonstrating its effectiveness as a general video representation learner. The code and model is available at \url{https://github.com/OpenGVLab/VideoMAEv2}.
InternVideo: General Video Foundation Models via Generative and Discriminative Learning
Dec 07, 2022The foundation models have recently shown excellent performance on a variety of downstream tasks in computer vision. However, most existing vision foundation models simply focus on image-level pretraining and adpation, which are limited for dynamic and complex video-level understanding tasks. To fill the gap, we present general video foundation models, InternVideo, by taking advantage of both generative and discriminative self-supervised video learning. Specifically, InternVideo efficiently explores masked video modeling and video-language contrastive learning as the pretraining objectives, and selectively coordinates video representations of these two complementary frameworks in a learnable manner to boost various video applications. Without bells and whistles, InternVideo achieves state-of-the-art performance on 39 video datasets from extensive tasks including video action recognition/detection, video-language alignment, and open-world video applications. Especially, our methods can obtain 91.1% and 77.2% top-1 accuracy on the challenging Kinetics-400 and Something-Something V2 benchmarks, respectively. All of these results effectively show the generality of our InternVideo for video understanding. The code will be released at https://github.com/OpenGVLab/InternVideo .
InternVideo-Ego4D: A Pack of Champion Solutions to Ego4D Challenges
Nov 17, 2022



In this report, we present our champion solutions to five tracks at Ego4D challenge. We leverage our developed InternVideo, a video foundation model, for five Ego4D tasks, including Moment Queries, Natural Language Queries, Future Hand Prediction, State Change Object Detection, and Short-term Object Interaction Anticipation. InternVideo-Ego4D is an effective paradigm to adapt the strong foundation model to the downstream ego-centric video understanding tasks with simple head designs. In these five tasks, the performance of InternVideo-Ego4D comprehensively surpasses the baseline methods and the champions of CVPR2022, demonstrating the powerful representation ability of InternVideo as a video foundation model. Our code will be released at https://github.com/OpenGVLab/ego4d-eccv2022-solutions