 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClinical Priors Guided Lung Disease Detection in 3D CT Scans
Mar 17, 2026Accurate classification of lung diseases from chest CT scans plays an important role in computer-aided diagnosis systems. However, medical imaging datasets often suffer from severe class imbalance, which may significantly degrade the performance of deep learning models, especially for minority disease categories. To address this issue, we propose a gender-aware two-stage lung disease classification framework. The proposed approach explicitly incorporates gender information into the disease recognition pipeline. In the first stage, a gender classifier is trained to predict the patient's gender from CT scans. In the second stage, the input CT image is routed to a corresponding gender-specific disease classifier to perform final disease prediction. This design enables the model to better capture gender-related imaging characteristics and alleviate the influence of imbalanced data distribution. Experimental results demonstrate that the proposed method improves the recognition performance for minority disease categories, particularly squamous cell carcinoma, while maintaining competitive performance on other classes.
Vision-Language Model Based Multi-Expert Fusion for CT Image Classification
Mar 16, 2026Robust detection of COVID-19 from chest CT remains challenging in multi-institutional settings due to substantial source shift, source imbalance, and hidden test-source identities. In this work, we propose a three-stage source-aware multi-expert framework for multi-source COVID-19 CT classification. First, we build a lung-aware 3D expert by combining original CT volumes and lung-extracted CT volumes for volumetric classification. Second, we develop two MedSigLIP-based experts: a slice-wise representation and probability learning module, and a Transformer-based inter-slice context modeling module for capturing cross-slice dependency. Third, we train a source classifier to predict the latent source identity of each test scan. By leveraging the predicted source information, we perform model fusion and voting based on different experts. On the validation set covering all four sources, the Stage 1 model achieves the best macro-F1 of 0.9711, ACC of 0.9712, and AUC of 0.9791. Stage~2a and Stage~2b achieve the best AUC scores of 0.9864 and 0.9854, respectively. Stage~3 source classifier reaches 0.9107 ACC and 0.9114 F1. These results demonstrate that source-aware expert modeling and hierarchical voting provide an effective solution for robust COVID-19 CT classification under heterogeneous multi-source conditions.
OmniStream: Mastering Perception, Reconstruction and Action in Continuous Streams
Mar 12, 2026Modern visual agents require representations that are general, causal, and physically structured to operate in real-time streaming environments. However, current vision foundation models remain fragmented, specializing narrowly in image semantic perception, offline temporal modeling, or spatial geometry. This paper introduces OmniStream, a unified streaming visual backbone that effectively perceives, reconstructs, and acts from diverse visual inputs. By incorporating causal spatiotemporal attention and 3D rotary positional embeddings (3D-RoPE), our model supports efficient, frame-by-frame online processing of video streams via a persistent KV-cache. We pre-train OmniStream using a synergistic multi-task framework coupling static and temporal representation learning, streaming geometric reconstruction, and vision-language alignment on 29 datasets. Extensive evaluations show that, even with a strictly frozen backbone, OmniStream achieves consistently competitive performance with specialized experts across image and video probing, streaming geometric reconstruction, complex video and spatial reasoning, as well as robotic manipulation (unseen at training). Rather than pursuing benchmark-specific dominance, our work demonstrates the viability of training a single, versatile vision backbone that generalizes across semantic, spatial, and temporal reasoning, i.e., a more meaningful step toward general-purpose visual understanding for interactive and embodied agents.
Advancing Lung Disease Diagnosis in 3D CT Scans
Jul 01, 2025To enable more accurate diagnosis of lung disease in chest CT scans, we propose a straightforward yet effective model. Firstly, we analyze the characteristics of 3D CT scans and remove non-lung regions, which helps the model focus on lesion-related areas and reduces computational cost. We adopt ResNeSt50 as a strong feature extractor, and use a weighted cross-entropy loss to mitigate class imbalance, especially for the underrepresented squamous cell carcinoma category. Our model achieves a Macro F1 Score of 0.80 on the validation set of the Fair Disease Diagnosis Challenge, demonstrating its strong performance in distinguishing between different lung conditions.
Bridging Perspectives: A Survey on Cross-view Collaborative Intelligence with Egocentric-Exocentric Vision
Jun 06, 2025



Perceiving the world from both egocentric (first-person) and exocentric (third-person) perspectives is fundamental to human cognition, enabling rich and complementary understanding of dynamic environments. In recent years, allowing the machines to leverage the synergistic potential of these dual perspectives has emerged as a compelling research direction in video understanding. In this survey, we provide a comprehensive review of video understanding from both exocentric and egocentric viewpoints. We begin by highlighting the practical applications of integrating egocentric and exocentric techniques, envisioning their potential collaboration across domains. We then identify key research tasks to realize these applications. Next, we systematically organize and review recent advancements into three main research directions: (1) leveraging egocentric data to enhance exocentric understanding, (2) utilizing exocentric data to improve egocentric analysis, and (3) joint learning frameworks that unify both perspectives. For each direction, we analyze a diverse set of tasks and relevant works. Additionally, we discuss benchmark datasets that support research in both perspectives, evaluating their scope, diversity, and applicability. Finally, we discuss limitations in current works and propose promising future research directions. By synthesizing insights from both perspectives, our goal is to inspire advancements in video understanding and artificial intelligence, bringing machines closer to perceiving the world in a human-like manner. A GitHub repo of related works can be found at https://github.com/ayiyayi/Awesome-Egocentric-and-Exocentric-Vision.
AOR: Anatomical Ontology-Guided Reasoning for Medical Large Multimodal Model in Chest X-Ray Interpretation
May 05, 2025Chest X-rays (CXRs) are the most frequently performed imaging examinations in clinical settings. Recent advancements in Large Multimodal Models (LMMs) have enabled automated CXR interpretation, enhancing diagnostic accuracy and efficiency. However, despite their strong visual understanding, current Medical LMMs (MLMMs) still face two major challenges: (1) Insufficient region-level understanding and interaction, and (2) Limited accuracy and interpretability due to single-step reasoning. In this paper, we empower MLMMs with anatomy-centric reasoning capabilities to enhance their interactivity and explainability. Specifically, we first propose an Anatomical Ontology-Guided Reasoning (AOR) framework, which centers on cross-modal region-level information to facilitate multi-step reasoning. Next, under the guidance of expert physicians, we develop AOR-Instruction, a large instruction dataset for MLMMs training. Our experiments demonstrate AOR's superior performance in both VQA and report generation tasks.
Learning Streaming Video Representation via Multitask Training
Apr 28, 2025
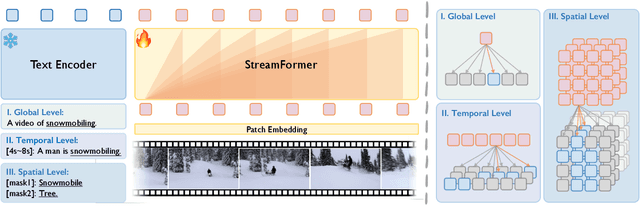
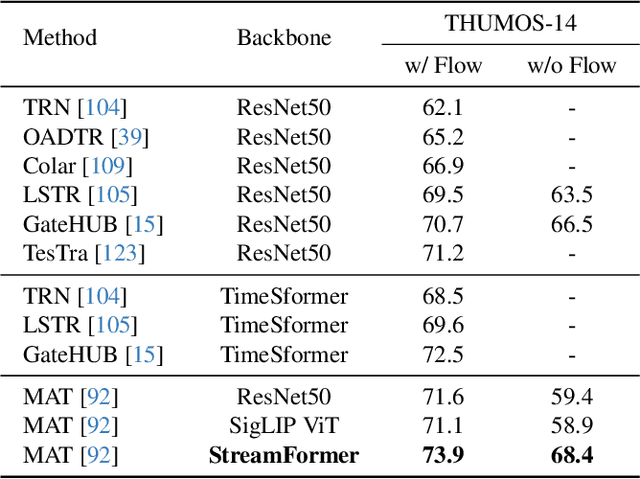
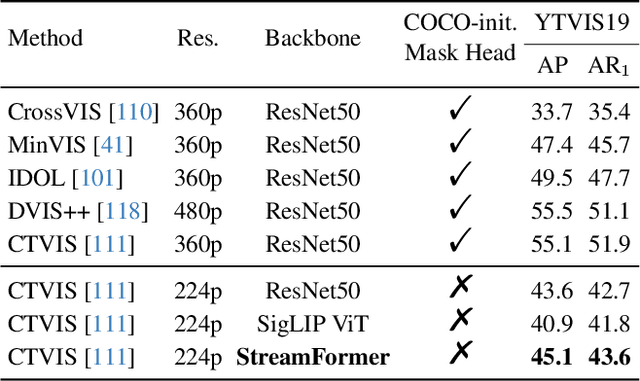
Understanding continuous video streams plays a fundamental role in real-time applications including embodied AI and autonomous driving. Unlike offline video understanding, streaming video understanding requires the ability to process video streams frame by frame, preserve historical information, and make low-latency decisions.To address these challenges, our main contributions are three-fold. (i) We develop a novel streaming video backbone, termed as StreamFormer, by incorporating causal temporal attention into a pre-trained vision transformer. This enables efficient streaming video processing while maintaining image representation capability.(ii) To train StreamFormer, we propose to unify diverse spatial-temporal video understanding tasks within a multitask visual-language alignment framework. Hence, StreamFormer learns global semantics, temporal dynamics, and fine-grained spatial relationships simultaneously. (iii) We conduct extensive experiments on online action detection, online video instance segmentation, and video question answering. StreamFormer achieves competitive results while maintaining efficiency, demonstrating its potential for real-time applications.
EgoExo-Gen: Ego-centric Video Prediction by Watching Exo-centric Videos
Apr 16, 2025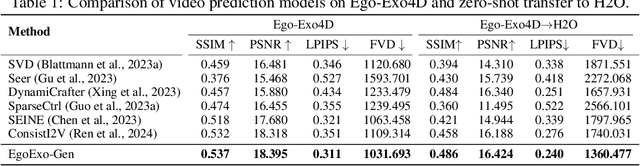
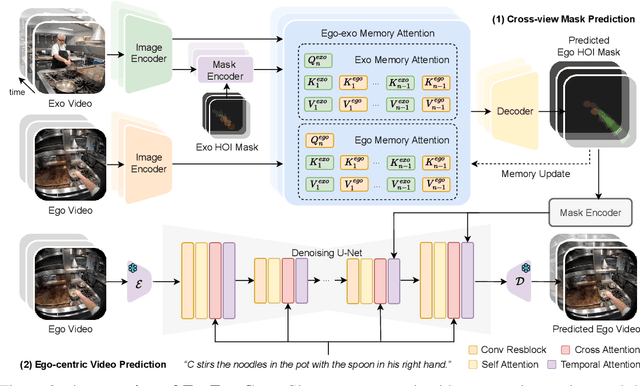

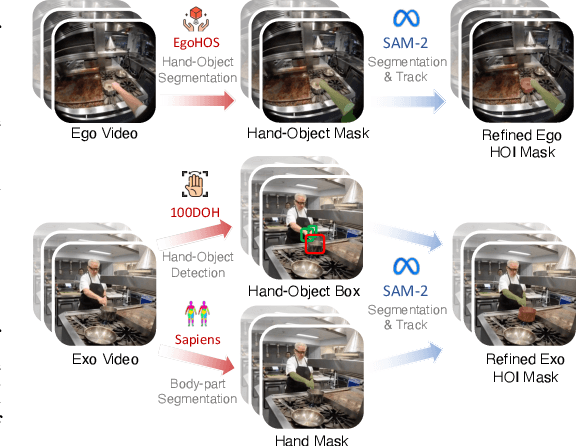
Generating videos in the first-person perspective has broad application prospects in the field of augmented reality and embodied intelligence. In this work, we explore the cross-view video prediction task, where given an exo-centric video, the first frame of the corresponding ego-centric video, and textual instructions, the goal is to generate futur frames of the ego-centric video. Inspired by the notion that hand-object interactions (HOI) in ego-centric videos represent the primary intentions and actions of the current actor, we present EgoExo-Gen that explicitly models the hand-object dynamics for cross-view video prediction. EgoExo-Gen consists of two stages. First, we design a cross-view HOI mask prediction model that anticipates the HOI masks in future ego-frames by modeling the spatio-temporal ego-exo correspondence. Next, we employ a video diffusion model to predict future ego-frames using the first ego-frame and textual instructions, while incorporating the HOI masks as structural guidance to enhance prediction quality. To facilitate training, we develop an automated pipeline to generate pseudo HOI masks for both ego- and exo-videos by exploiting vision foundation models. Extensive experiments demonstrate that our proposed EgoExo-Gen achieves better prediction performance compared to previous video prediction models on the Ego-Exo4D and H2O benchmark datasets, with the HOI masks significantly improving the generation of hands and interactive objects in the ego-centric videos.
An Egocentric Vision-Language Model based Portable Real-time Smart Assistant
Mar 06, 2025We present Vinci, a vision-language system designed to provide real-time, comprehensive AI assistance on portable devices. At its core, Vinci leverages EgoVideo-VL, a novel model that integrates an egocentric vision foundation model with a large language model (LLM), enabling advanced functionalities such as scene understanding, temporal grounding, video summarization, and future planning. To enhance its utility, Vinci incorporates a memory module for processing long video streams in real time while retaining contextual history, a generation module for producing visual action demonstrations, and a retrieval module that bridges egocentric and third-person perspectives to provide relevant how-to videos for skill acquisition. Unlike existing systems that often depend on specialized hardware, Vinci is hardware-agnostic, supporting deployment across a wide range of devices, including smartphones and wearable cameras. In our experiments, we first demonstrate the superior performance of EgoVideo-VL on multiple public benchmarks, showcasing its vision-language reasoning and contextual understanding capabilities. We then conduct a series of user studies to evaluate the real-world effectiveness of Vinci, highlighting its adaptability and usability in diverse scenarios. We hope Vinci can establish a new framework for portable, real-time egocentric AI systems, empowering users with contextual and actionable insights. Including the frontend, backend, and models, all codes of Vinci are available at https://github.com/OpenGVLab/vinci.
Modeling Fine-Grained Hand-Object Dynamics for Egocentric Video Representation Learning
Mar 02, 2025



In egocentric video understanding, the motion of hands and objects as well as their interactions play a significant role by nature. However, existing egocentric video representation learning methods mainly focus on aligning video representation with high-level narrations, overlooking the intricate dynamics between hands and objects. In this work, we aim to integrate the modeling of fine-grained hand-object dynamics into the video representation learning process. Since no suitable data is available, we introduce HOD, a novel pipeline employing a hand-object detector and a large language model to generate high-quality narrations with detailed descriptions of hand-object dynamics. To learn these fine-grained dynamics, we propose EgoVideo, a model with a new lightweight motion adapter to capture fine-grained hand-object motion information. Through our co-training strategy, EgoVideo effectively and efficiently leverages the fine-grained hand-object dynamics in the HOD data. Extensive experiments demonstrate that our method achieves state-of-the-art performance across multiple egocentric downstream tasks, including improvements of 6.3% in EK-100 multi-instance retrieval, 5.7% in EK-100 classification, and 16.3% in EGTEA classification in zero-shot settings. Furthermore, our model exhibits robust generalization capabilities in hand-object interaction and robot manipulation tasks. Code and data are available at https://github.com/OpenRobotLab/EgoHOD/.