 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeaver: End-to-End Agentic System Training for Video Interleaved Reasoning
Feb 05, 2026Video reasoning constitutes a comprehensive assessment of a model's capabilities, as it demands robust perceptual and interpretive skills, thereby serving as a means to explore the boundaries of model performance. While recent research has leveraged text-centric Chain-of-Thought reasoning to augment these capabilities, such approaches frequently suffer from representational mismatch and restricted by limited perceptual acuity. To address these limitations, we propose Weaver, a novel, end-to-end trainable multimodal reasoning agentic system. Weaver empowers its policy model to dynamically invoke diverse tools throughout the reasoning process, enabling progressive acquisition of crucial visual cues and construction of authentic multimodal reasoning trajectories. Furthermore, we integrate a reinforcement learning algorithm to allow the system to freely explore strategies for employing and combining these tools with trajectory-free data. Extensive experiments demonstrate that our system, Weaver, enhances performance on several complex video reasoning benchmarks, particularly those involving long videos.
Learning Streaming Video Representation via Multitask Training
Apr 28, 2025
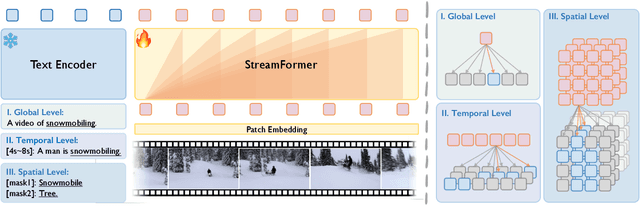
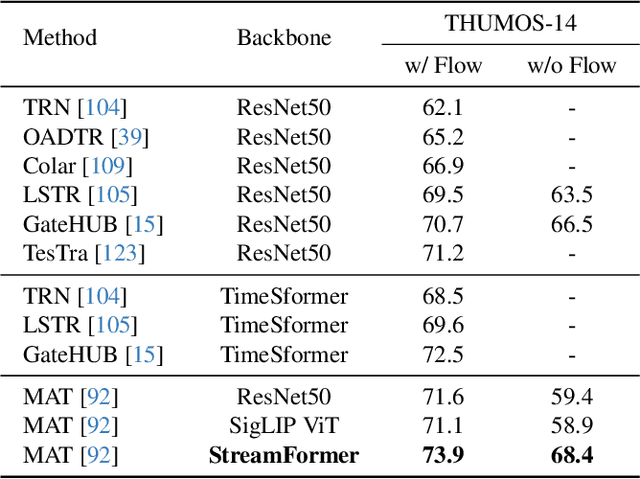
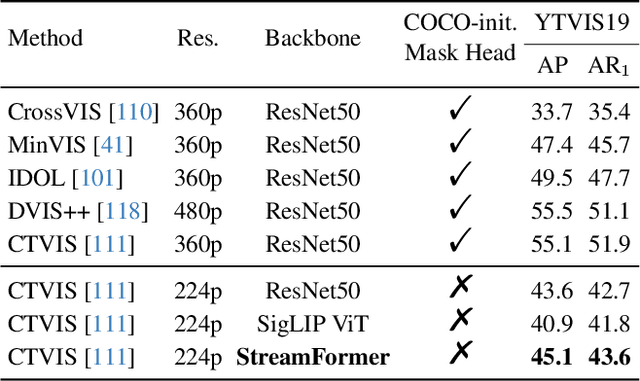
Understanding continuous video streams plays a fundamental role in real-time applications including embodied AI and autonomous driving. Unlike offline video understanding, streaming video understanding requires the ability to process video streams frame by frame, preserve historical information, and make low-latency decisions.To address these challenges, our main contributions are three-fold. (i) We develop a novel streaming video backbone, termed as StreamFormer, by incorporating causal temporal attention into a pre-trained vision transformer. This enables efficient streaming video processing while maintaining image representation capability.(ii) To train StreamFormer, we propose to unify diverse spatial-temporal video understanding tasks within a multitask visual-language alignment framework. Hence, StreamFormer learns global semantics, temporal dynamics, and fine-grained spatial relationships simultaneously. (iii) We conduct extensive experiments on online action detection, online video instance segmentation, and video question answering. StreamFormer achieves competitive results while maintaining efficiency, demonstrating its potential for real-time applications.
Unlocking Video-LLM via Agent-of-Thoughts Distillation
Dec 02, 2024



This paper tackles the problem of video question answering (VideoQA), a task that often requires multi-step reasoning and a profound understanding of spatial-temporal dynamics. While large video-language models perform well on benchmarks, they often lack explainability and spatial-temporal grounding. In this paper, we propose Agent-of-Thoughts Distillation (AoTD), a method that enhances models by incorporating automatically generated Chain-of-Thoughts (CoTs) into the instruction-tuning process. Specifically, we leverage an agent-based system to decompose complex questions into sub-tasks, and address them with specialized vision models, the intermediate results are then treated as reasoning chains. We also introduce a verification mechanism using a large language model (LLM) to ensure the reliability of generated CoTs. Extensive experiments demonstrate that AoTD improves the performance on multiple-choice and open-ended benchmarks.