 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniversal Video Temporal Grounding with Generative Multi-modal Large Language Models
Jun 23, 2025This paper presents a computational model for universal video temporal grounding, which accurately localizes temporal moments in videos based on natural language queries (e.g., questions or descriptions). Unlike existing methods that are often limited to specific video domains or durations, we propose UniTime, a robust and universal video grounding model leveraging the strong vision-language understanding capabilities of generative Multi-modal Large Language Models (MLLMs). Our model effectively handles videos of diverse views, genres, and lengths while comprehending complex language queries. The key contributions include: (i) We consider steering strong MLLMs for temporal grounding in videos. To enable precise timestamp outputs, we incorporate temporal information by interleaving timestamp tokens with video tokens. (ii) By training the model to handle videos with different input granularities through adaptive frame scaling, our approach achieves robust temporal grounding for both short and long videos. (iii) Comprehensive experiments show that UniTime outperforms state-of-the-art approaches in both zero-shot and dataset-specific finetuned settings across five public temporal grounding benchmarks. (iv) When employed as a preliminary moment retriever for long-form video question-answering (VideoQA), UniTime significantly improves VideoQA accuracy, highlighting its value for complex video understanding tasks.
Learning Streaming Video Representation via Multitask Training
Apr 28, 2025
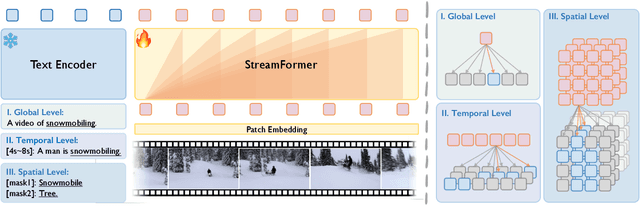
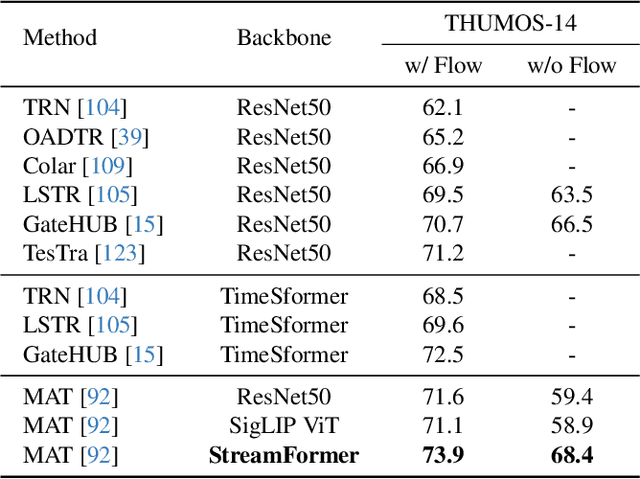
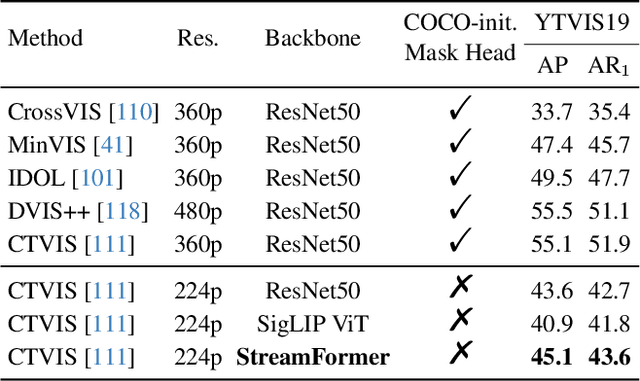
Understanding continuous video streams plays a fundamental role in real-time applications including embodied AI and autonomous driving. Unlike offline video understanding, streaming video understanding requires the ability to process video streams frame by frame, preserve historical information, and make low-latency decisions.To address these challenges, our main contributions are three-fold. (i) We develop a novel streaming video backbone, termed as StreamFormer, by incorporating causal temporal attention into a pre-trained vision transformer. This enables efficient streaming video processing while maintaining image representation capability.(ii) To train StreamFormer, we propose to unify diverse spatial-temporal video understanding tasks within a multitask visual-language alignment framework. Hence, StreamFormer learns global semantics, temporal dynamics, and fine-grained spatial relationships simultaneously. (iii) We conduct extensive experiments on online action detection, online video instance segmentation, and video question answering. StreamFormer achieves competitive results while maintaining efficiency, demonstrating its potential for real-time applications.
A Strong Baseline for Temporal Video-Text Alignment
Dec 21, 2023In this paper, we consider the problem of temporally aligning the video and texts from instructional videos, specifically, given a long-term video, and associated text sentences, our goal is to determine their corresponding timestamps in the video. To this end, we establish a simple, yet strong model that adopts a Transformer-based architecture with all texts as queries, iteratively attending to the visual features, to infer the optimal timestamp. We conduct thorough experiments to investigate: (i) the effect of upgrading ASR systems to reduce errors from speech recognition, (ii) the effect of various visual-textual backbones, ranging from CLIP to S3D, to the more recent InternVideo, (iii) the effect of transforming noisy ASR transcripts into descriptive steps by prompting a large language model (LLM), to summarize the core activities within the ASR transcript as a new training dataset. As a result, our proposed simple model demonstrates superior performance on both narration alignment and procedural step grounding tasks, surpassing existing state-of-the-art methods by a significant margin on three public benchmarks, namely, 9.3% on HT-Step, 3.4% on HTM-Align and 4.7% on CrossTask. We believe the proposed model and dataset with descriptive steps can be treated as a strong baseline for future research in temporal video-text alignment. All codes, models, and the resulting dataset will be publicly released to the research community.
Turbo: Informativity-Driven Acceleration Plug-In for Vision-Language Models
Dec 12, 2023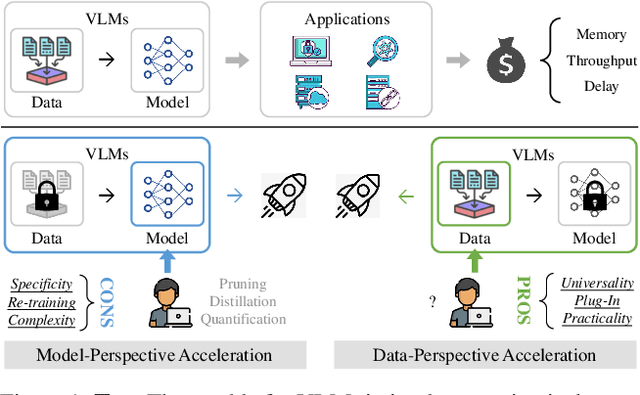
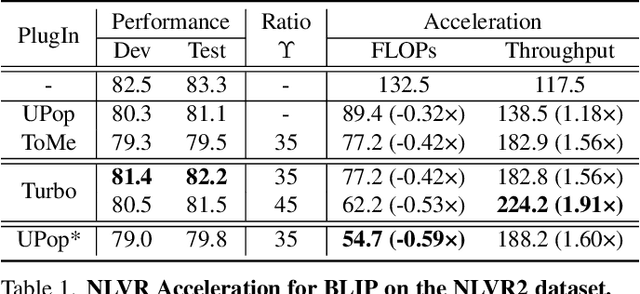
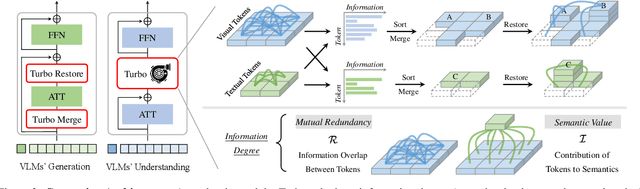
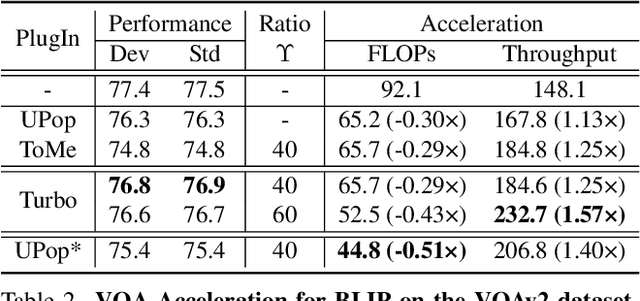
Vision-Language Large Models (VLMs) have become primary backbone of AI, due to the impressive performance. However, their expensive computation costs, i.e., throughput and delay, impede potentials in real-world scenarios. To achieve acceleration for VLMs, most existing methods focus on the model perspective: pruning, distillation, quantification, but completely overlook the data-perspective redundancy. To fill the overlook, this paper pioneers the severity of data redundancy, and designs one plug-and-play Turbo module guided by information degree to prune inefficient tokens from visual or textual data. In pursuit of efficiency-performance trade-offs, information degree takes two key factors into consideration: mutual redundancy and semantic value. Concretely, the former evaluates the data duplication between sequential tokens; while the latter evaluates each token by its contribution to the overall semantics. As a result, tokens with high information degree carry less redundancy and stronger semantics. For VLMs' calculation, Turbo works as a user-friendly plug-in that sorts data referring to information degree, utilizing only top-level ones to save costs. Its advantages are multifaceted, e.g., being generally compatible to various VLMs across understanding and generation, simple use without retraining and trivial engineering efforts. On multiple public VLMs benchmarks, we conduct extensive experiments to reveal the gratifying acceleration of Turbo, under negligible performance drop.
Multi-modal Prompting for Low-Shot Temporal Action Localization
Mar 21, 2023
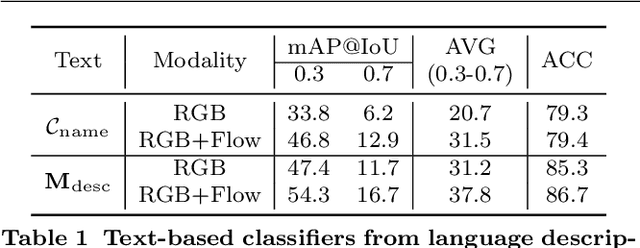
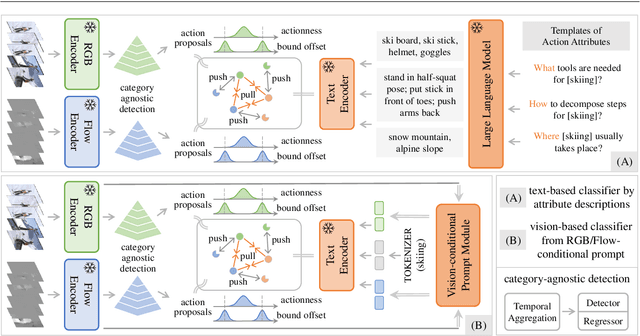
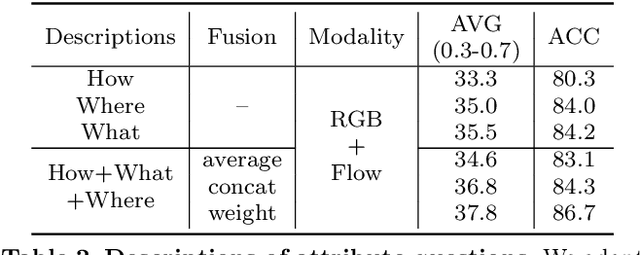
In this paper, we consider the problem of temporal action localization under low-shot (zero-shot & few-shot) scenario, with the goal of detecting and classifying the action instances from arbitrary categories within some untrimmed videos, even not seen at training time. We adopt a Transformer-based two-stage action localization architecture with class-agnostic action proposal, followed by open-vocabulary classification. We make the following contributions. First, to compensate image-text foundation models with temporal motions, we improve category-agnostic action proposal by explicitly aligning embeddings of optical flows, RGB and texts, which has largely been ignored in existing low-shot methods. Second, to improve open-vocabulary action classification, we construct classifiers with strong discriminative power, i.e., avoid lexical ambiguities. To be specific, we propose to prompt the pre-trained CLIP text encoder either with detailed action descriptions (acquired from large-scale language models), or visually-conditioned instance-specific prompt vectors. Third, we conduct thorough experiments and ablation studies on THUMOS14 and ActivityNet1.3, demonstrating the superior performance of our proposed model, outperforming existing state-of-the-art approaches by one significant margin.
Channel Pruned YOLOv5-based Deep Learning Approach for Rapid and Accurate Outdoor Obstacles Detection
Apr 27, 2022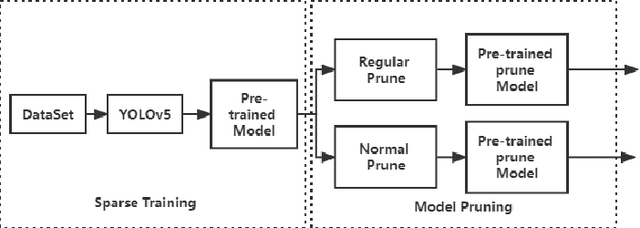

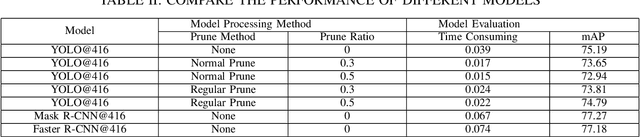
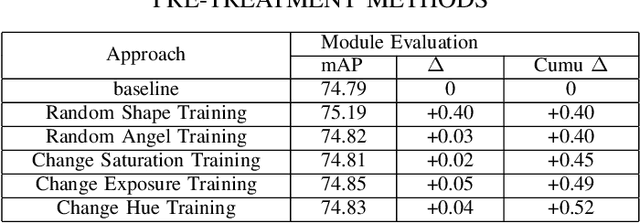
One-stage algorithm have been widely used in target detection systems that need to be trained with massive data. Most of them perform well both in real-time and accuracy. However, due to their convolutional structure, they need more computing power and greater memory consumption. Hence, we applied pruning strategy to target detection networks to reduce the number of parameters and the size of model. To demonstrate the practicality of the pruning method, we select the YOLOv5 model for experiments and provide a data set of outdoor obstacles to show the effect of model. In this specific data set, in the best circumstances, the volume of the network model is reduced by 49.7% compared with the original model, and the reasoning time is reduced by 52.5%. Meanwhile, it also uses data processing methods to compensate for the drop in accuracy caused by pruning.
Compositional Affinity Propagation: When Clusters Have Compositional Structure
Sep 09, 2021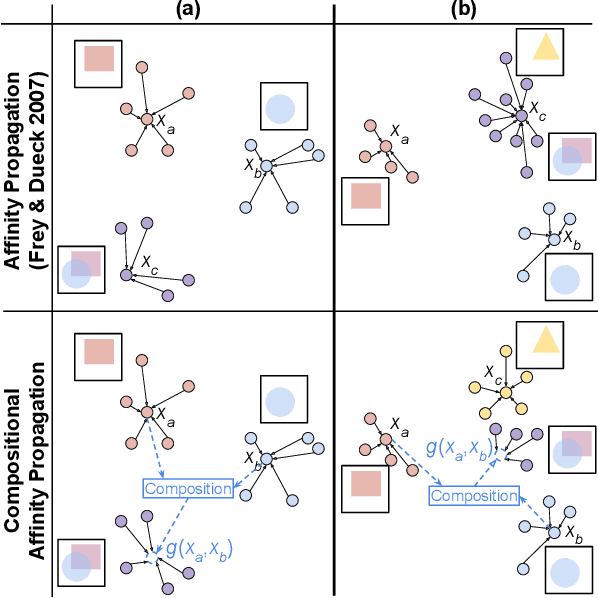
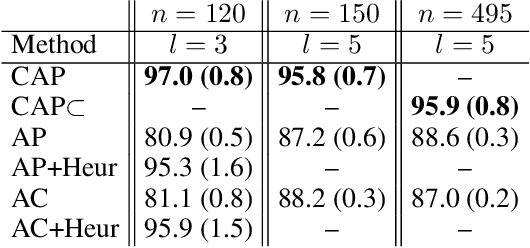
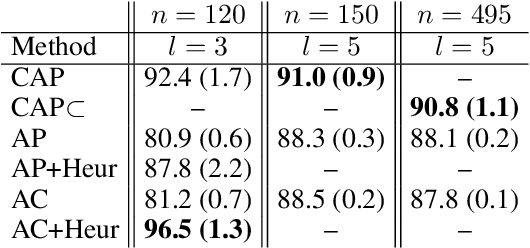
We consider a new kind of clustering problem in which clusters need not be independent of each other, but rather can have compositional relationships with other clusters (e.g., an image set consists of rectangles, circles, as well as combinations of rectangles and circles). This task is motivated by recent work in few-shot learning on compositional embedding models that structure the embedding space to distinguish the label sets, not just the individual labels, assigned to the examples. To tackle this clustering problem, we propose a new algorithm called Compositional Affinity Propagation (CAP). In contrast to standard Affinity Propagation as well as other algorithms for multi-view and hierarchical clustering, CAP can deduce compositionality among clusters automatically. We show promising results, compared to several existing clustering algorithms, on the MultiMNIST, OmniGlot, and LibriSpeech datasets. Our work has applications to multi-object image recognition and speaker diarization with simultaneous speech from multiple speakers.
Compositional embedding models for speaker identification and diarization with simultaneous speech from 2+ speakers
Oct 22, 2020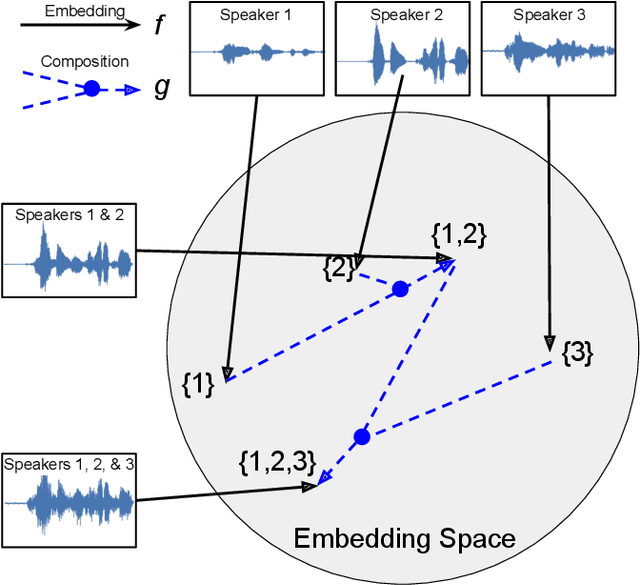
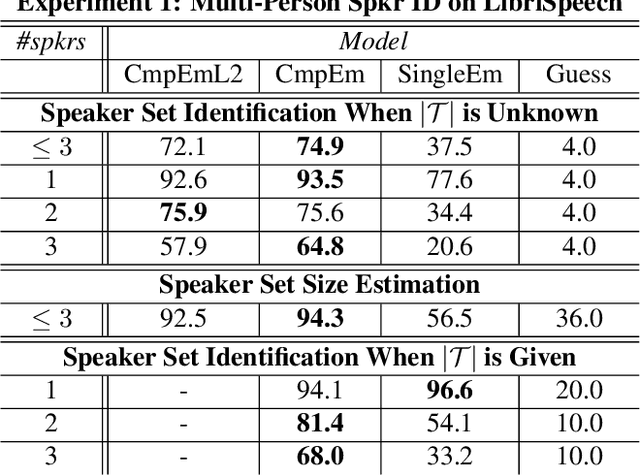

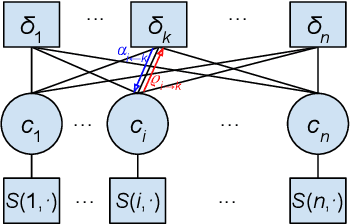
We propose a new method for speaker diarization that can handle overlapping speech with 2+ people. Our method is based on compositional embeddings [1]: Like standard speaker embedding methods such as x-vector [2], compositional embedding models contain a function f that separates speech from different speakers. In addition, they include a composition function g to compute set-union operations in the embedding space so as to infer the set of speakers within the input audio. In an experiment on multi-person speaker identification using synthesized LibriSpeech data, the proposed method outperforms traditional embedding methods that are only trained to separate single speakers (not speaker sets). In a speaker diarization experiment on the AMI Headset Mix corpus, we achieve state-of-the-art accuracy (DER=22.93%), slightly higher than the previous best result (23.82% from [3]).
Compositional Embeddings for Multi-Label One-Shot Learning
Feb 12, 2020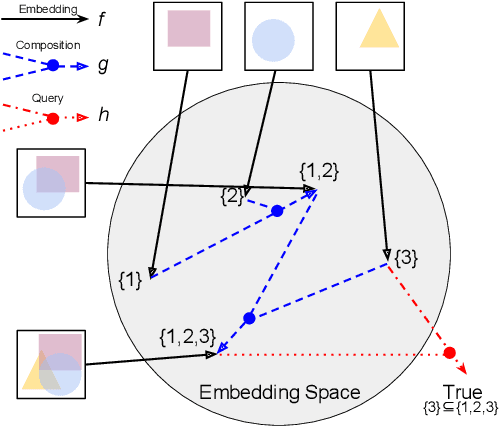
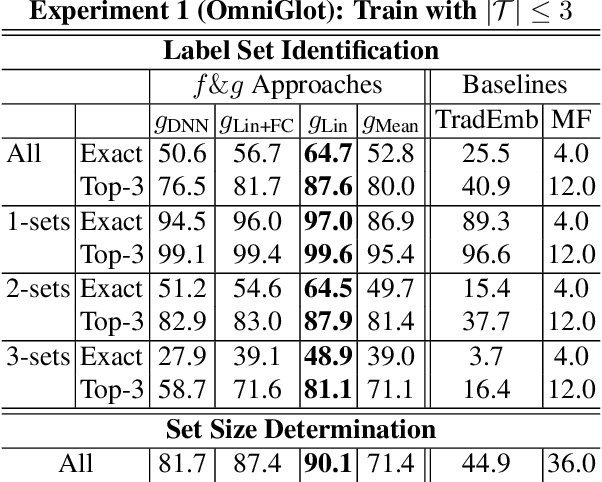
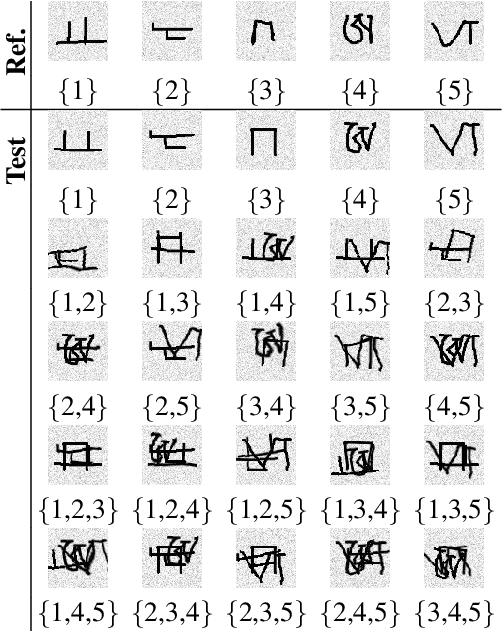
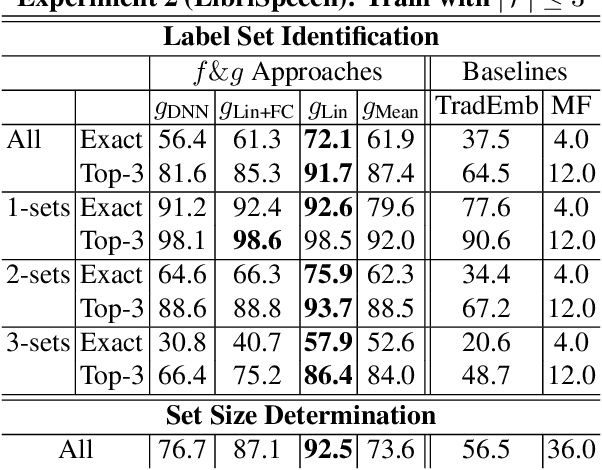
We explore the idea of compositional set embeddings that can be used to infer not just a single class per input (e.g., image, video, audio signal), but a collection of classes, in the setting of one-shot learning. Class compositionality is useful in tasks such as multi-object detection in images and multi-speaker diarization in audio. Specifically, we devise and implement two novel models consisting of (1) an embedding function f trained jointly with a "composite" function g that computes set union operations between the classes encoded in two embedding vectors; and (2) embedding f trained jointly with a "query" function h that computes whether the classes encoded in one embedding subsume the classes encoded in another embedding. In contrast to previously developed methods, these models must both determine the classes associated with the input examples and encode the relationships between different class label sets. In experiments conducted on simulated data, OmniGlot, LibriSpeech and Open Images datasets, the proposed composite embedding models outperform baselines based on traditional embedding methods.