 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniStream: Mastering Perception, Reconstruction and Action in Continuous Streams
Mar 12, 2026Modern visual agents require representations that are general, causal, and physically structured to operate in real-time streaming environments. However, current vision foundation models remain fragmented, specializing narrowly in image semantic perception, offline temporal modeling, or spatial geometry. This paper introduces OmniStream, a unified streaming visual backbone that effectively perceives, reconstructs, and acts from diverse visual inputs. By incorporating causal spatiotemporal attention and 3D rotary positional embeddings (3D-RoPE), our model supports efficient, frame-by-frame online processing of video streams via a persistent KV-cache. We pre-train OmniStream using a synergistic multi-task framework coupling static and temporal representation learning, streaming geometric reconstruction, and vision-language alignment on 29 datasets. Extensive evaluations show that, even with a strictly frozen backbone, OmniStream achieves consistently competitive performance with specialized experts across image and video probing, streaming geometric reconstruction, complex video and spatial reasoning, as well as robotic manipulation (unseen at training). Rather than pursuing benchmark-specific dominance, our work demonstrates the viability of training a single, versatile vision backbone that generalizes across semantic, spatial, and temporal reasoning, i.e., a more meaningful step toward general-purpose visual understanding for interactive and embodied agents.
VersaViT: Enhancing MLLM Vision Backbones via Task-Guided Optimization
Feb 10, 2026Multimodal Large Language Models (MLLMs) have recently achieved remarkable success in visual-language understanding, demonstrating superior high-level semantic alignment within their vision encoders. An important question thus arises: Can these encoders serve as versatile vision backbones, capable of reliably performing classic vision-centric tasks as well? To address the question, we make the following contributions: (i) we identify that the vision encoders within MLLMs exhibit deficiencies in their dense feature representations, as evidenced by their suboptimal performance on dense prediction tasks (e.g., semantic segmentation, depth estimation); (ii) we propose VersaViT, a well-rounded vision transformer that instantiates a novel multi-task framework for collaborative post-training. This framework facilitates the optimization of the vision backbone via lightweight task heads with multi-granularity supervision; (iii) extensive experiments across various downstream tasks demonstrate the effectiveness of our method, yielding a versatile vision backbone suited for both language-mediated reasoning and pixel-level understanding.
Weaver: End-to-End Agentic System Training for Video Interleaved Reasoning
Feb 05, 2026Video reasoning constitutes a comprehensive assessment of a model's capabilities, as it demands robust perceptual and interpretive skills, thereby serving as a means to explore the boundaries of model performance. While recent research has leveraged text-centric Chain-of-Thought reasoning to augment these capabilities, such approaches frequently suffer from representational mismatch and restricted by limited perceptual acuity. To address these limitations, we propose Weaver, a novel, end-to-end trainable multimodal reasoning agentic system. Weaver empowers its policy model to dynamically invoke diverse tools throughout the reasoning process, enabling progressive acquisition of crucial visual cues and construction of authentic multimodal reasoning trajectories. Furthermore, we integrate a reinforcement learning algorithm to allow the system to freely explore strategies for employing and combining these tools with trajectory-free data. Extensive experiments demonstrate that our system, Weaver, enhances performance on several complex video reasoning benchmarks, particularly those involving long videos.
Revisiting Multi-Task Visual Representation Learning
Jan 20, 2026Current visual representation learning remains bifurcated: vision-language models (e.g., CLIP) excel at global semantic alignment but lack spatial precision, while self-supervised methods (e.g., MAE, DINO) capture intricate local structures yet struggle with high-level semantic context. We argue that these paradigms are fundamentally complementary and can be integrated into a principled multi-task framework, further enhanced by dense spatial supervision. We introduce MTV, a multi-task visual pretraining framework that jointly optimizes a shared backbone across vision-language contrastive, self-supervised, and dense spatial objectives. To mitigate the need for manual annotations, we leverage high-capacity "expert" models -- such as Depth Anything V2 and OWLv2 -- to synthesize dense, structured pseudo-labels at scale. Beyond the framework, we provide a systematic investigation into the mechanics of multi-task visual learning, analyzing: (i) the marginal gain of each objective, (ii) task synergies versus interference, and (iii) scaling behavior across varying data and model scales. Our results demonstrate that MTV achieves "best-of-both-worlds" performance, significantly enhancing fine-grained spatial reasoning without compromising global semantic understanding. Our findings suggest that multi-task learning, fueled by high-quality pseudo-supervision, is a scalable path toward more general visual encoders.
Universal Video Temporal Grounding with Generative Multi-modal Large Language Models
Jun 23, 2025This paper presents a computational model for universal video temporal grounding, which accurately localizes temporal moments in videos based on natural language queries (e.g., questions or descriptions). Unlike existing methods that are often limited to specific video domains or durations, we propose UniTime, a robust and universal video grounding model leveraging the strong vision-language understanding capabilities of generative Multi-modal Large Language Models (MLLMs). Our model effectively handles videos of diverse views, genres, and lengths while comprehending complex language queries. The key contributions include: (i) We consider steering strong MLLMs for temporal grounding in videos. To enable precise timestamp outputs, we incorporate temporal information by interleaving timestamp tokens with video tokens. (ii) By training the model to handle videos with different input granularities through adaptive frame scaling, our approach achieves robust temporal grounding for both short and long videos. (iii) Comprehensive experiments show that UniTime outperforms state-of-the-art approaches in both zero-shot and dataset-specific finetuned settings across five public temporal grounding benchmarks. (iv) When employed as a preliminary moment retriever for long-form video question-answering (VideoQA), UniTime significantly improves VideoQA accuracy, highlighting its value for complex video understanding tasks.
Learning Streaming Video Representation via Multitask Training
Apr 28, 2025
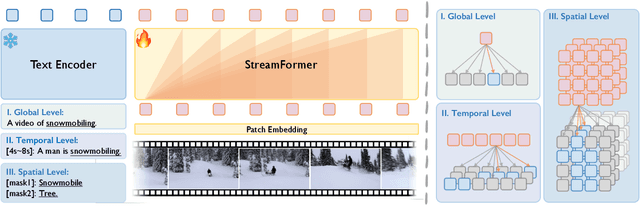
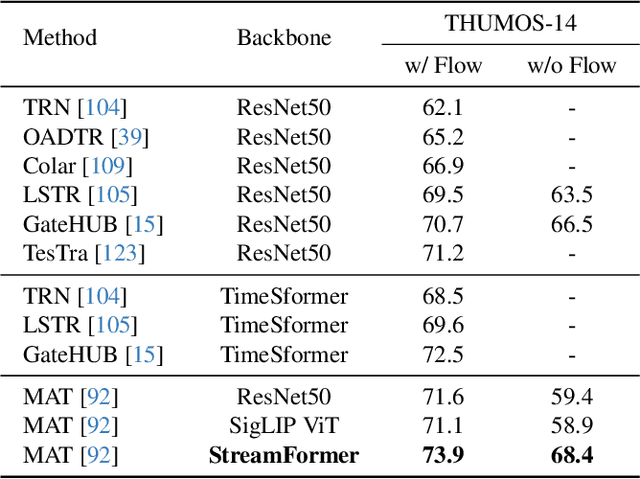
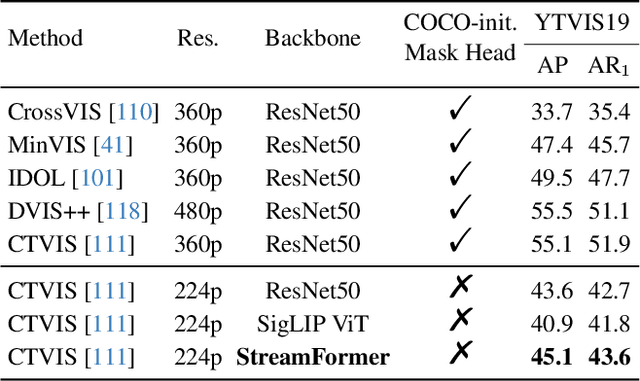
Understanding continuous video streams plays a fundamental role in real-time applications including embodied AI and autonomous driving. Unlike offline video understanding, streaming video understanding requires the ability to process video streams frame by frame, preserve historical information, and make low-latency decisions.To address these challenges, our main contributions are three-fold. (i) We develop a novel streaming video backbone, termed as StreamFormer, by incorporating causal temporal attention into a pre-trained vision transformer. This enables efficient streaming video processing while maintaining image representation capability.(ii) To train StreamFormer, we propose to unify diverse spatial-temporal video understanding tasks within a multitask visual-language alignment framework. Hence, StreamFormer learns global semantics, temporal dynamics, and fine-grained spatial relationships simultaneously. (iii) We conduct extensive experiments on online action detection, online video instance segmentation, and video question answering. StreamFormer achieves competitive results while maintaining efficiency, demonstrating its potential for real-time applications.
Unlocking Video-LLM via Agent-of-Thoughts Distillation
Dec 02, 2024



This paper tackles the problem of video question answering (VideoQA), a task that often requires multi-step reasoning and a profound understanding of spatial-temporal dynamics. While large video-language models perform well on benchmarks, they often lack explainability and spatial-temporal grounding. In this paper, we propose Agent-of-Thoughts Distillation (AoTD), a method that enhances models by incorporating automatically generated Chain-of-Thoughts (CoTs) into the instruction-tuning process. Specifically, we leverage an agent-based system to decompose complex questions into sub-tasks, and address them with specialized vision models, the intermediate results are then treated as reasoning chains. We also introduce a verification mechanism using a large language model (LLM) to ensure the reliability of generated CoTs. Extensive experiments demonstrate that AoTD improves the performance on multiple-choice and open-ended benchmarks.
Grounded Multi-Hop VideoQA in Long-Form Egocentric Videos
Aug 26, 2024



This paper considers the problem of Multi-Hop Video Question Answering (MH-VidQA) in long-form egocentric videos. This task not only requires to answer visual questions, but also to localize multiple relevant time intervals within the video as visual evidences. We develop an automated pipeline to create multi-hop question-answering pairs with associated temporal evidence, enabling to construct a large-scale dataset for instruction-tuning. To monitor the progress of this new task, we further curate a high-quality benchmark, MultiHop-EgoQA, with careful manual verification and refinement. Experimental results reveal that existing multi-modal systems exhibit inadequate multi-hop grounding and reasoning abilities, resulting in unsatisfactory performance. We then propose a novel architecture, termed as Grounding Scattered Evidence with Large Language Model (GeLM), that enhances multi-modal large language models (MLLMs) by incorporating a grounding module to retrieve temporal evidence from videos using flexible grounding tokens. Trained on our visual instruction data, GeLM demonstrates improved multi-hop grounding and reasoning capabilities, setting a new baseline for this challenging task. Furthermore, when trained on third-person view videos, the same architecture also achieves state-of-the-art performance on the single-hop VidQA benchmark, ActivityNet-RTL, demonstrating its effectiveness.
Grounded Question-Answering in Long Egocentric Videos
Dec 11, 2023



Existing approaches to video understanding, mainly designed for short videos from a third-person perspective, are limited in their applicability in certain fields, such as robotics. In this paper, we delve into open-ended question-answering (QA) in long, egocentric videos, which allows individuals or robots to inquire about their own past visual experiences. This task presents unique challenges, including the complexity of temporally grounding queries within extensive video content, the high resource demands for precise data annotation, and the inherent difficulty of evaluating open-ended answers due to their ambiguous nature. Our proposed approach tackles these challenges by (i) integrating query grounding and answering within a unified model to reduce error propagation; (ii) employing large language models for efficient and scalable data synthesis; and (iii) introducing a close-ended QA task for evaluation, to manage answer ambiguity. Extensive experiments demonstrate the effectiveness of our method, which also achieves state-of-the-art performance on the QAEgo4D and Ego4D-NLQ benchmarks. We plan to publicly release the codes, model, and constructed datasets for future research.
Sparse Dense Fusion for 3D Object Detection
Apr 09, 2023



With the prevalence of multimodal learning, camera-LiDAR fusion has gained popularity in 3D object detection. Although multiple fusion approaches have been proposed, they can be classified into either sparse-only or dense-only fashion based on the feature representation in the fusion module. In this paper, we analyze them in a common taxonomy and thereafter observe two challenges: 1) sparse-only solutions preserve 3D geometric prior and yet lose rich semantic information from the camera, and 2) dense-only alternatives retain the semantic continuity but miss the accurate geometric information from LiDAR. By analyzing these two formulations, we conclude that the information loss is inevitable due to their design scheme. To compensate for the information loss in either manner, we propose Sparse Dense Fusion (SDF), a complementary framework that incorporates both sparse-fusion and dense-fusion modules via the Transformer architecture. Such a simple yet effective sparse-dense fusion structure enriches semantic texture and exploits spatial structure information simultaneously. Through our SDF strategy, we assemble two popular methods with moderate performance and outperform baseline by 4.3% in mAP and 2.5% in NDS, ranking first on the nuScenes benchmark. Extensive ablations demonstrate the effectiveness of our method and empirically align our analysis.