 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVGGT-Segmentor: Geometry-Enhanced Cross-View Segmentation
Apr 16, 2026Instance-level object segmentation across disparate egocentric and exocentric views is a fundamental challenge in visual understanding, critical for applications in embodied AI and remote collaboration. This task is exceptionally difficult due to severe changes in scale, perspective, and occlusion, which destabilize direct pixel-level matching. While recent geometry-aware models like VGGT provide a strong foundation for feature alignment, we find they often fail at dense prediction tasks due to significant pixel-level projection drift, even when their internal object-level attention remains consistent. To bridge this gap, we introduce VGGT-Segmentor (VGGT-S), a framework that unifies robust geometric modeling with pixel-accurate semantic segmentation. VGGT-S leverages VGGT's powerful cross-view feature representation and introduces a novel Union Segmentation Head. This head operates in three stages: mask prompt fusion, point-guided prediction, and iterative mask refinement, effectively translating high-level feature alignment into a precise segmentation mask. Furthermore, we propose a single-image self-supervised training strategy that eliminates the need for paired annotations and enables strong generalization. On the Ego-Exo4D benchmark, VGGT-S sets a new state-of-the-art, achieving 67.7% and 68.0% average IoU for Ego to Exo and Exo to Ego tasks, respectively, significantly outperforming prior methods. Notably, our correspondence-free pretrained model surpasses most fully-supervised baselines, demonstrating the effectiveness and scalability of our approach.
DOMR: Establishing Cross-View Segmentation via Dense Object Matching
Aug 06, 2025Cross-view object correspondence involves matching objects between egocentric (first-person) and exocentric (third-person) views. It is a critical yet challenging task for visual understanding. In this work, we propose the Dense Object Matching and Refinement (DOMR) framework to establish dense object correspondences across views. The framework centers around the Dense Object Matcher (DOM) module, which jointly models multiple objects. Unlike methods that directly match individual object masks to image features, DOM leverages both positional and semantic relationships among objects to find correspondences. DOM integrates a proposal generation module with a dense matching module that jointly encodes visual, spatial, and semantic cues, explicitly constructing inter-object relationships to achieve dense matching among objects. Furthermore, we combine DOM with a mask refinement head designed to improve the completeness and accuracy of the predicted masks, forming the complete DOMR framework. Extensive evaluations on the Ego-Exo4D benchmark demonstrate that our approach achieves state-of-the-art performance with a mean IoU of 49.7% on Ego$\to$Exo and 55.2% on Exo$\to$Ego. These results outperform those of previous methods by 5.8% and 4.3%, respectively, validating the effectiveness of our integrated approach for cross-view understanding.
CoST: Efficient Collaborative Perception From Unified Spatiotemporal Perspective
Aug 01, 2025Collaborative perception shares information among different agents and helps solving problems that individual agents may face, e.g., occlusions and small sensing range. Prior methods usually separate the multi-agent fusion and multi-time fusion into two consecutive steps. In contrast, this paper proposes an efficient collaborative perception that aggregates the observations from different agents (space) and different times into a unified spatio-temporal space simultanesouly. The unified spatio-temporal space brings two benefits, i.e., efficient feature transmission and superior feature fusion. 1) Efficient feature transmission: each static object yields a single observation in the spatial temporal space, and thus only requires transmission only once (whereas prior methods re-transmit all the object features multiple times). 2) superior feature fusion: merging the multi-agent and multi-time fusion into a unified spatial-temporal aggregation enables a more holistic perspective, thereby enhancing perception performance in challenging scenarios. Consequently, our Collaborative perception with Spatio-temporal Transformer (CoST) gains improvement in both efficiency and accuracy. Notably, CoST is not tied to any specific method and is compatible with a majority of previous methods, enhancing their accuracy while reducing the transmission bandwidth.
MV2DFusion: Leveraging Modality-Specific Object Semantics for Multi-Modal 3D Detection
Aug 12, 2024The rise of autonomous vehicles has significantly increased the demand for robust 3D object detection systems. While cameras and LiDAR sensors each offer unique advantages--cameras provide rich texture information and LiDAR offers precise 3D spatial data--relying on a single modality often leads to performance limitations. This paper introduces MV2DFusion, a multi-modal detection framework that integrates the strengths of both worlds through an advanced query-based fusion mechanism. By introducing an image query generator to align with image-specific attributes and a point cloud query generator, MV2DFusion effectively combines modality-specific object semantics without biasing toward one single modality. Then the sparse fusion process can be accomplished based on the valuable object semantics, ensuring efficient and accurate object detection across various scenarios. Our framework's flexibility allows it to integrate with any image and point cloud-based detectors, showcasing its adaptability and potential for future advancements. Extensive evaluations on the nuScenes and Argoverse2 datasets demonstrate that MV2DFusion achieves state-of-the-art performance, particularly excelling in long-range detection scenarios.
Transferring CLIP's Knowledge into Zero-Shot Point Cloud Semantic Segmentation
Dec 12, 2023



Traditional 3D segmentation methods can only recognize a fixed range of classes that appear in the training set, which limits their application in real-world scenarios due to the lack of generalization ability. Large-scale visual-language pre-trained models, such as CLIP, have shown their generalization ability in the zero-shot 2D vision tasks, but are still unable to be applied to 3D semantic segmentation directly. In this work, we focus on zero-shot point cloud semantic segmentation and propose a simple yet effective baseline to transfer the visual-linguistic knowledge implied in CLIP to point cloud encoder at both feature and output levels. Both feature-level and output-level alignments are conducted between 2D and 3D encoders for effective knowledge transfer. Concretely, a Multi-granularity Cross-modal Feature Alignment (MCFA) module is proposed to align 2D and 3D features from global semantic and local position perspectives for feature-level alignment. For the output level, per-pixel pseudo labels of unseen classes are extracted using the pre-trained CLIP model as supervision for the 3D segmentation model to mimic the behavior of the CLIP image encoder. Extensive experiments are conducted on two popular benchmarks of point cloud segmentation. Our method outperforms significantly previous state-of-the-art methods under zero-shot setting (+29.2% mIoU on SemanticKITTI and 31.8% mIoU on nuScenes), and further achieves promising results in the annotation-free point cloud semantic segmentation setting, showing its great potential for label-efficient learning.
DriveAdapter: Breaking the Coupling Barrier of Perception and Planning in End-to-End Autonomous Driving
Aug 01, 2023

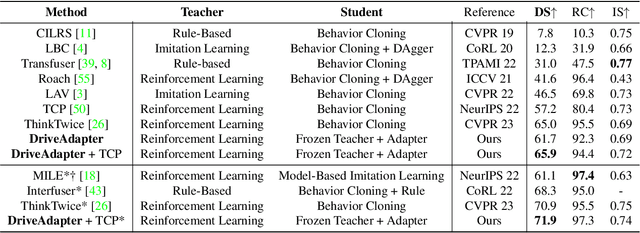

End-to-end autonomous driving aims to build a fully differentiable system that takes raw sensor data as inputs and directly outputs the planned trajectory or control signals of the ego vehicle. State-of-the-art methods usually follow the `Teacher-Student' paradigm. The Teacher model uses privileged information (ground-truth states of surrounding agents and map elements) to learn the driving strategy. The student model only has access to raw sensor data and conducts behavior cloning on the data collected by the teacher model. By eliminating the noise of the perception part during planning learning, state-of-the-art works could achieve better performance with significantly less data compared to those coupled ones. However, under the current Teacher-Student paradigm, the student model still needs to learn a planning head from scratch, which could be challenging due to the redundant and noisy nature of raw sensor inputs and the casual confusion issue of behavior cloning. In this work, we aim to explore the possibility of directly adopting the strong teacher model to conduct planning while letting the student model focus more on the perception part. We find that even equipped with a SOTA perception model, directly letting the student model learn the required inputs of the teacher model leads to poor driving performance, which comes from the large distribution gap between predicted privileged inputs and the ground-truth. To this end, we propose DriveAdapter, which employs adapters with the feature alignment objective function between the student (perception) and teacher (planning) modules. Additionally, since the pure learning-based teacher model itself is imperfect and occasionally breaks safety rules, we propose a method of action-guided feature learning with a mask for those imperfect teacher features to further inject the priors of hand-crafted rules into the learning process.
Sparse Dense Fusion for 3D Object Detection
Apr 09, 2023



With the prevalence of multimodal learning, camera-LiDAR fusion has gained popularity in 3D object detection. Although multiple fusion approaches have been proposed, they can be classified into either sparse-only or dense-only fashion based on the feature representation in the fusion module. In this paper, we analyze them in a common taxonomy and thereafter observe two challenges: 1) sparse-only solutions preserve 3D geometric prior and yet lose rich semantic information from the camera, and 2) dense-only alternatives retain the semantic continuity but miss the accurate geometric information from LiDAR. By analyzing these two formulations, we conclude that the information loss is inevitable due to their design scheme. To compensate for the information loss in either manner, we propose Sparse Dense Fusion (SDF), a complementary framework that incorporates both sparse-fusion and dense-fusion modules via the Transformer architecture. Such a simple yet effective sparse-dense fusion structure enriches semantic texture and exploits spatial structure information simultaneously. Through our SDF strategy, we assemble two popular methods with moderate performance and outperform baseline by 4.3% in mAP and 2.5% in NDS, ranking first on the nuScenes benchmark. Extensive ablations demonstrate the effectiveness of our method and empirically align our analysis.
Delving into the Devils of Bird's-eye-view Perception: A Review, Evaluation and Recipe
Sep 12, 2022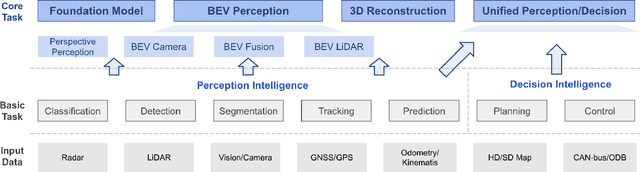
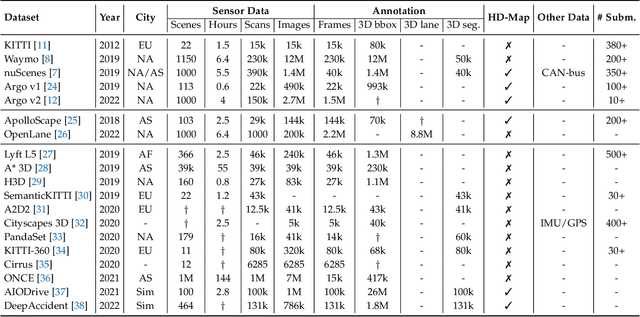
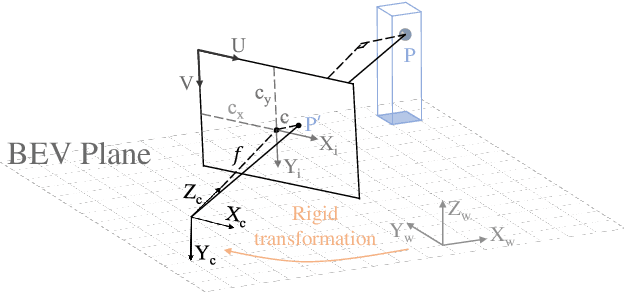
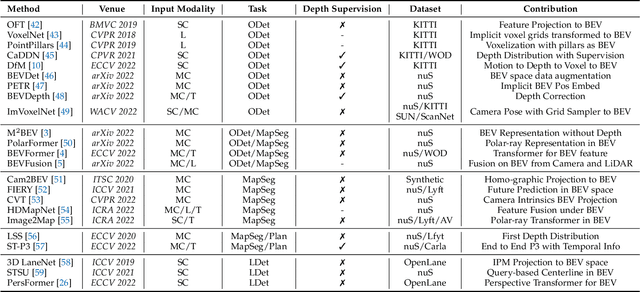
Learning powerful representations in bird's-eye-view (BEV) for perception tasks is trending and drawing extensive attention both from industry and academia. Conventional approaches for most autonomous driving algorithms perform detection, segmentation, tracking, etc., in a front or perspective view. As sensor configurations get more complex, integrating multi-source information from different sensors and representing features in a unified view come of vital importance. BEV perception inherits several advantages, as representing surrounding scenes in BEV is intuitive and fusion-friendly; and representing objects in BEV is most desirable for subsequent modules as in planning and/or control. The core problems for BEV perception lie in (a) how to reconstruct the lost 3D information via view transformation from perspective view to BEV; (b) how to acquire ground truth annotations in BEV grid; (c) how to formulate the pipeline to incorporate features from different sources and views; and (d) how to adapt and generalize algorithms as sensor configurations vary across different scenarios. In this survey, we review the most recent work on BEV perception and provide an in-depth analysis of different solutions. Moreover, several systematic designs of BEV approach from the industry are depicted as well. Furthermore, we introduce a full suite of practical guidebook to improve the performance of BEV perception tasks, including camera, LiDAR and fusion inputs. At last, we point out the future research directions in this area. We hope this report would shed some light on the community and encourage more research effort on BEV perception. We keep an active repository to collect the most recent work and provide a toolbox for bag of tricks at https://github.com/OpenPerceptionX/BEVPerception-Survey-Recipe.
Human-centric Relation Segmentation: Dataset and Solution
May 25, 2021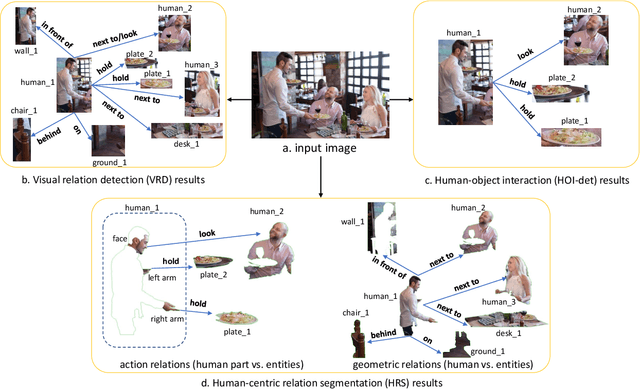

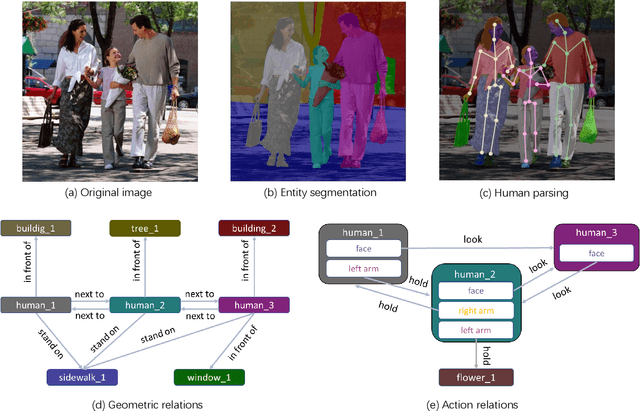
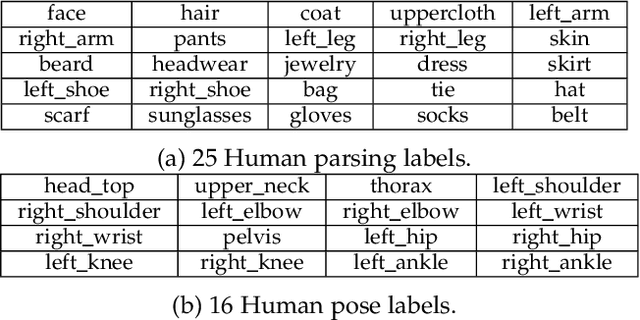
Vision and language understanding techniques have achieved remarkable progress, but currently it is still difficult to well handle problems involving very fine-grained details. For example, when the robot is told to "bring me the book in the girl's left hand", most existing methods would fail if the girl holds one book respectively in her left and right hand. In this work, we introduce a new task named human-centric relation segmentation (HRS), as a fine-grained case of HOI-det. HRS aims to predict the relations between the human and surrounding entities and identify the relation-correlated human parts, which are represented as pixel-level masks. For the above exemplar case, our HRS task produces results in the form of relation triplets <girl [left hand], hold, book> and exacts segmentation masks of the book, with which the robot can easily accomplish the grabbing task. Correspondingly, we collect a new Person In Context (PIC) dataset for this new task, which contains 17,122 high-resolution images and densely annotated entity segmentation and relations, including 141 object categories, 23 relation categories and 25 semantic human parts. We also propose a Simultaneous Matching and Segmentation (SMS) framework as a solution to the HRS task. I Outputs of the three branches are fused to produce the final HRS results. Extensive experiments on PIC and V-COCO datasets show that the proposed SMS method outperforms baselines with the 36 FPS inference speed.