 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProFashion: Prototype-guided Fashion Video Generation with Multiple Reference Images
May 10, 2025



Fashion video generation aims to synthesize temporally consistent videos from reference images of a designated character. Despite significant progress, existing diffusion-based methods only support a single reference image as input, severely limiting their capability to generate view-consistent fashion videos, especially when there are different patterns on the clothes from different perspectives. Moreover, the widely adopted motion module does not sufficiently model human body movement, leading to sub-optimal spatiotemporal consistency. To address these issues, we propose ProFashion, a fashion video generation framework leveraging multiple reference images to achieve improved view consistency and temporal coherency. To effectively leverage features from multiple reference images while maintaining a reasonable computational cost, we devise a Pose-aware Prototype Aggregator, which selects and aggregates global and fine-grained reference features according to pose information to form frame-wise prototypes, which serve as guidance in the denoising process. To further enhance motion consistency, we introduce a Flow-enhanced Prototype Instantiator, which exploits the human keypoint motion flow to guide an extra spatiotemporal attention process in the denoiser. To demonstrate the effectiveness of ProFashion, we extensively evaluate our method on the MRFashion-7K dataset we collected from the Internet. ProFashion also outperforms previous methods on the UBC Fashion dataset.
Transferring CLIP's Knowledge into Zero-Shot Point Cloud Semantic Segmentation
Dec 12, 2023



Traditional 3D segmentation methods can only recognize a fixed range of classes that appear in the training set, which limits their application in real-world scenarios due to the lack of generalization ability. Large-scale visual-language pre-trained models, such as CLIP, have shown their generalization ability in the zero-shot 2D vision tasks, but are still unable to be applied to 3D semantic segmentation directly. In this work, we focus on zero-shot point cloud semantic segmentation and propose a simple yet effective baseline to transfer the visual-linguistic knowledge implied in CLIP to point cloud encoder at both feature and output levels. Both feature-level and output-level alignments are conducted between 2D and 3D encoders for effective knowledge transfer. Concretely, a Multi-granularity Cross-modal Feature Alignment (MCFA) module is proposed to align 2D and 3D features from global semantic and local position perspectives for feature-level alignment. For the output level, per-pixel pseudo labels of unseen classes are extracted using the pre-trained CLIP model as supervision for the 3D segmentation model to mimic the behavior of the CLIP image encoder. Extensive experiments are conducted on two popular benchmarks of point cloud segmentation. Our method outperforms significantly previous state-of-the-art methods under zero-shot setting (+29.2% mIoU on SemanticKITTI and 31.8% mIoU on nuScenes), and further achieves promising results in the annotation-free point cloud semantic segmentation setting, showing its great potential for label-efficient learning.
Cross-Modality Domain Adaptation for Freespace Detection: A Simple yet Effective Baseline
Oct 06, 2022
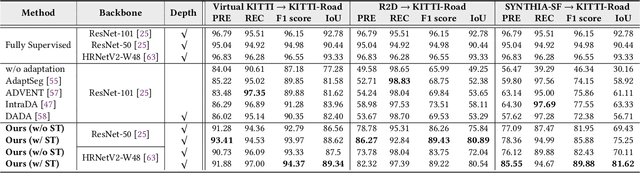
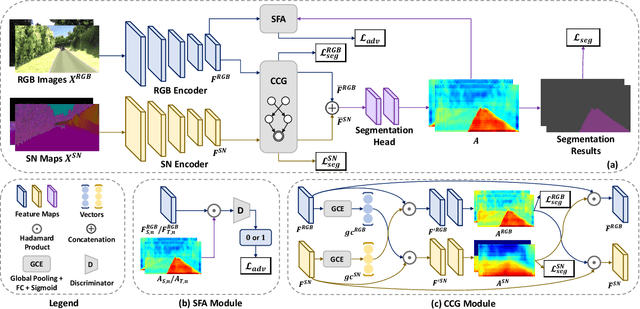
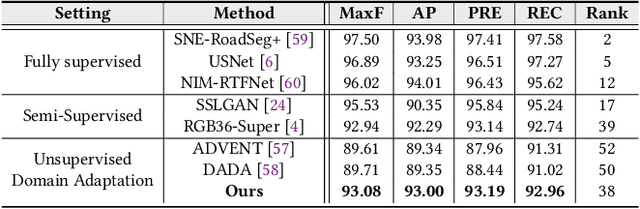
As one of the fundamental functions of autonomous driving system, freespace detection aims at classifying each pixel of the image captured by the camera as drivable or non-drivable. Current works of freespace detection heavily rely on large amount of densely labeled training data for accuracy and robustness, which is time-consuming and laborious to collect and annotate. To the best of our knowledge, we are the first work to explore unsupervised domain adaptation for freespace detection to alleviate the data limitation problem with synthetic data. We develop a cross-modality domain adaptation framework which exploits both RGB images and surface normal maps generated from depth images. A Collaborative Cross Guidance (CCG) module is proposed to leverage the context information of one modality to guide the other modality in a cross manner, thus realizing inter-modality intra-domain complement. To better bridge the domain gap between source domain (synthetic data) and target domain (real-world data), we also propose a Selective Feature Alignment (SFA) module which only aligns the features of consistent foreground area between the two domains, thus realizing inter-domain intra-modality adaptation. Extensive experiments are conducted by adapting three different synthetic datasets to one real-world dataset for freespace detection respectively. Our method performs closely to fully supervised freespace detection methods (93.08 v.s. 97.50 F1 score) and outperforms other general unsupervised domain adaptation methods for semantic segmentation with large margins, which shows the promising potential of domain adaptation for freespace detection.