 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoomVideo: Unifying Multimodal Inputs into Video Generation and Editing
Jun 04, 2026Developing unified video generation and editing models capable of interpreting interleaved multimodal inputs is a promising yet challenging frontier field. Existing unified frameworks predominantly rely on massive models (typically 13B parameters or more) and incorporate source video conditions for editing by concatenating sequence tokens. This concatenation inevitably doubles the sequence length, quadrupling the computational complexity of the self-attention mechanism and introducing prohibitive overhead. To address these bottlenecks, we present LoomVideo, a highly efficient 5B-parameter unified architecture for both video generation and editing. LoomVideo replaces the standard text encoder with a Multimodal Large Language Model (MLLM) and employs Deepstack injection mechanism to align multi-layer MLLM features with the Diffusion Transformer (DiT). Crucially, we introduce a zero-overhead Scale-and-Add conditioning approach for video editing. By scaling and directly adding the clean source video latent to the noised target latent, this elegant design eliminates the need for token concatenation, drastically reducing computational cost while maintaining robust capabilities for complex, non-rigid edits. Furthermore, a Negative Temporal RoPE strategy is seamlessly integrated to handle multiple reference images. Extensive experiments demonstrate that our compact 5B model achieves state-of-the-art or highly competitive performance across comprehensive benchmarks, exhibiting exceptional superiority in e-commerce and fashion generation scenarios. Benefiting from the zero-overhead conditioning mechanism, LoomVideo achieves at least a 5.41x acceleration in inference speed compared to models of similar capabilities, paving the way for highly practical and efficient video foundation models.
Denoising as Path Planning: Training-Free Acceleration of Diffusion Models with DPCache
Feb 26, 2026Diffusion models have demonstrated remarkable success in image and video generation, yet their practical deployment remains hindered by the substantial computational overhead of multi-step iterative sampling. Among acceleration strategies, caching-based methods offer a training-free and effective solution by reusing or predicting features across timesteps. However, existing approaches rely on fixed or locally adaptive schedules without considering the global structure of the denoising trajectory, often leading to error accumulation and visual artifacts. To overcome this limitation, we propose DPCache, a novel training-free acceleration framework that formulates diffusion sampling acceleration as a global path planning problem. DPCache constructs a Path-Aware Cost Tensor from a small calibration set to quantify the path-dependent error of skipping timesteps conditioned on the preceding key timestep. Leveraging this tensor, DPCache employs dynamic programming to select an optimal sequence of key timesteps that minimizes the total path cost while preserving trajectory fidelity. During inference, the model performs full computations only at these key timesteps, while intermediate outputs are efficiently predicted using cached features. Extensive experiments on DiT, FLUX, and HunyuanVideo demonstrate that DPCache achieves strong acceleration with minimal quality loss, outperforming prior acceleration methods by $+$0.031 ImageReward at 4.87$\times$ speedup and even surpassing the full-step baseline by $+$0.028 ImageReward at 3.54$\times$ speedup on FLUX, validating the effectiveness of our path-aware global scheduling framework. Code will be released at https://github.com/argsss/DPCache.
ProFashion: Prototype-guided Fashion Video Generation with Multiple Reference Images
May 10, 2025



Fashion video generation aims to synthesize temporally consistent videos from reference images of a designated character. Despite significant progress, existing diffusion-based methods only support a single reference image as input, severely limiting their capability to generate view-consistent fashion videos, especially when there are different patterns on the clothes from different perspectives. Moreover, the widely adopted motion module does not sufficiently model human body movement, leading to sub-optimal spatiotemporal consistency. To address these issues, we propose ProFashion, a fashion video generation framework leveraging multiple reference images to achieve improved view consistency and temporal coherency. To effectively leverage features from multiple reference images while maintaining a reasonable computational cost, we devise a Pose-aware Prototype Aggregator, which selects and aggregates global and fine-grained reference features according to pose information to form frame-wise prototypes, which serve as guidance in the denoising process. To further enhance motion consistency, we introduce a Flow-enhanced Prototype Instantiator, which exploits the human keypoint motion flow to guide an extra spatiotemporal attention process in the denoiser. To demonstrate the effectiveness of ProFashion, we extensively evaluate our method on the MRFashion-7K dataset we collected from the Internet. ProFashion also outperforms previous methods on the UBC Fashion dataset.
FuseAnyPart: Diffusion-Driven Facial Parts Swapping via Multiple Reference Images
Oct 30, 2024Facial parts swapping aims to selectively transfer regions of interest from the source image onto the target image while maintaining the rest of the target image unchanged. Most studies on face swapping designed specifically for full-face swapping, are either unable or significantly limited when it comes to swapping individual facial parts, which hinders fine-grained and customized character designs. However, designing such an approach specifically for facial parts swapping is challenged by a reasonable multiple reference feature fusion, which needs to be both efficient and effective. To overcome this challenge, FuseAnyPart is proposed to facilitate the seamless "fuse-any-part" customization of the face. In FuseAnyPart, facial parts from different people are assembled into a complete face in latent space within the Mask-based Fusion Module. Subsequently, the consolidated feature is dispatched to the Addition-based Injection Module for fusion within the UNet of the diffusion model to create novel characters. Extensive experiments qualitatively and quantitatively validate the superiority and robustness of FuseAnyPart. Source codes are available at https://github.com/Thomas-wyh/FuseAnyPart.
RealisDance: Equip controllable character animation with realistic hands
Sep 10, 2024Controllable character animation is an emerging task that generates character videos controlled by pose sequences from given character images. Although character consistency has made significant progress via reference UNet, another crucial factor, pose control, has not been well studied by existing methods yet, resulting in several issues: 1) The generation may fail when the input pose sequence is corrupted. 2) The hands generated using the DWPose sequence are blurry and unrealistic. 3) The generated video will be shaky if the pose sequence is not smooth enough. In this paper, we present RealisDance to handle all the above issues. RealisDance adaptively leverages three types of poses, avoiding failed generation caused by corrupted pose sequences. Among these pose types, HaMeR provides accurate 3D and depth information of hands, enabling RealisDance to generate realistic hands even for complex gestures. Besides using temporal attention in the main UNet, RealisDance also inserts temporal attention into the pose guidance network, smoothing the video from the pose condition aspect. Moreover, we introduce pose shuffle augmentation during training to further improve generation robustness and video smoothness. Qualitative experiments demonstrate the superiority of RealisDance over other existing methods, especially in hand quality.
DiffDance: Cascaded Human Motion Diffusion Model for Dance Generation
Aug 05, 2023When hearing music, it is natural for people to dance to its rhythm. Automatic dance generation, however, is a challenging task due to the physical constraints of human motion and rhythmic alignment with target music. Conventional autoregressive methods introduce compounding errors during sampling and struggle to capture the long-term structure of dance sequences. To address these limitations, we present a novel cascaded motion diffusion model, DiffDance, designed for high-resolution, long-form dance generation. This model comprises a music-to-dance diffusion model and a sequence super-resolution diffusion model. To bridge the gap between music and motion for conditional generation, DiffDance employs a pretrained audio representation learning model to extract music embeddings and further align its embedding space to motion via contrastive loss. During training our cascaded diffusion model, we also incorporate multiple geometric losses to constrain the model outputs to be physically plausible and add a dynamic loss weight that adaptively changes over diffusion timesteps to facilitate sample diversity. Through comprehensive experiments performed on the benchmark dataset AIST++, we demonstrate that DiffDance is capable of generating realistic dance sequences that align effectively with the input music. These results are comparable to those achieved by state-of-the-art autoregressive methods.
GEN-VLKT: Simplify Association and Enhance Interaction Understanding for HOI Detection
Apr 14, 2022
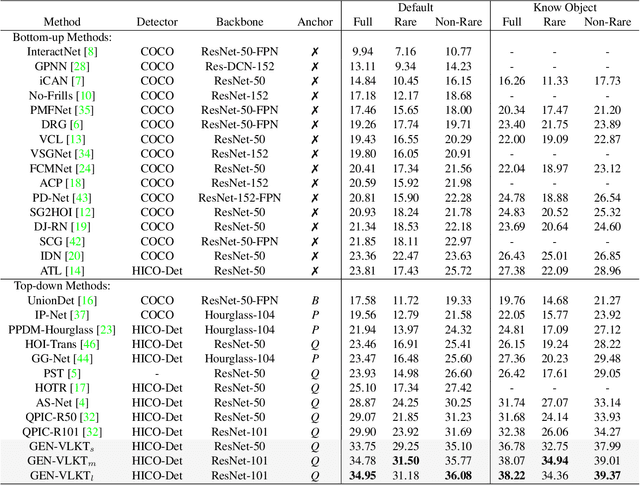
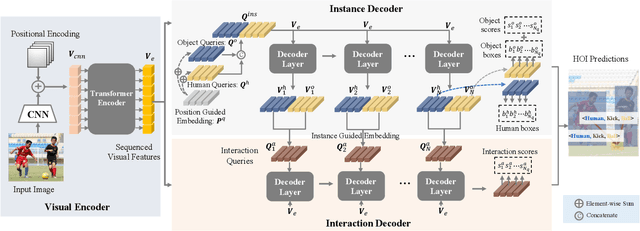
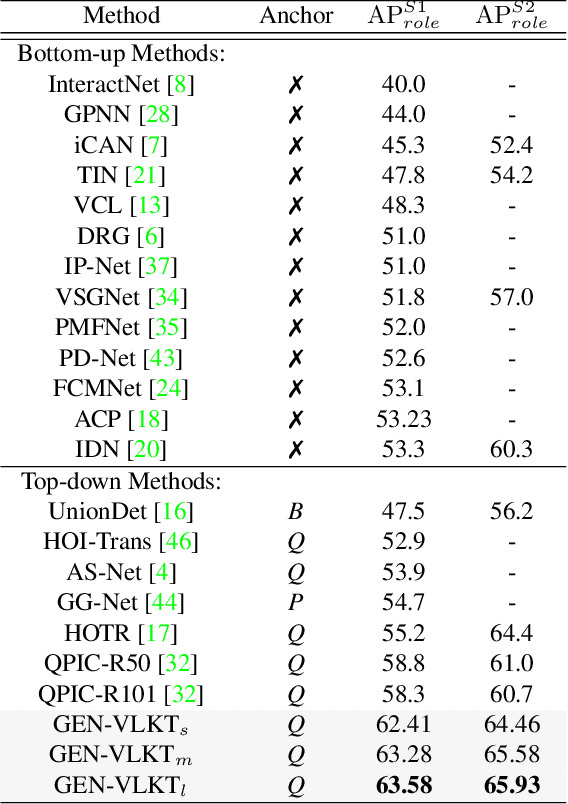
The task of Human-Object Interaction~(HOI) detection could be divided into two core problems, i.e., human-object association and interaction understanding. In this paper, we reveal and address the disadvantages of the conventional query-driven HOI detectors from the two aspects. For the association, previous two-branch methods suffer from complex and costly post-matching, while single-branch methods ignore the features distinction in different tasks. We propose Guided-Embedding Network~(GEN) to attain a two-branch pipeline without post-matching. In GEN, we design an instance decoder to detect humans and objects with two independent query sets and a position Guided Embedding~(p-GE) to mark the human and object in the same position as a pair. Besides, we design an interaction decoder to classify interactions, where the interaction queries are made of instance Guided Embeddings (i-GE) generated from the outputs of each instance decoder layer. For the interaction understanding, previous methods suffer from long-tailed distribution and zero-shot discovery. This paper proposes a Visual-Linguistic Knowledge Transfer (VLKT) training strategy to enhance interaction understanding by transferring knowledge from a visual-linguistic pre-trained model CLIP. In specific, we extract text embeddings for all labels with CLIP to initialize the classifier and adopt a mimic loss to minimize the visual feature distance between GEN and CLIP. As a result, GEN-VLKT outperforms the state of the art by large margins on multiple datasets, e.g., +5.05 mAP on HICO-Det. The source codes are available at https://github.com/YueLiao/gen-vlkt.
TransRefer3D: Entity-and-Relation Aware Transformer for Fine-Grained 3D Visual Grounding
Aug 11, 2021
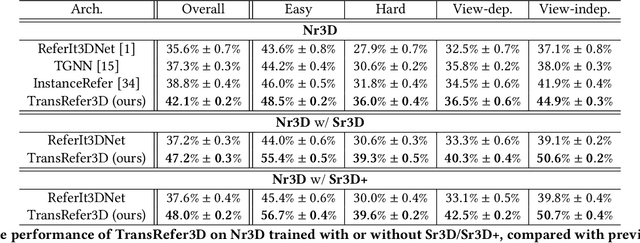
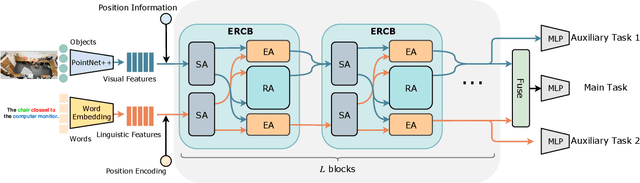

Recently proposed fine-grained 3D visual grounding is an essential and challenging task, whose goal is to identify the 3D object referred by a natural language sentence from other distractive objects of the same category. Existing works usually adopt dynamic graph networks to indirectly model the intra/inter-modal interactions, making the model difficult to distinguish the referred object from distractors due to the monolithic representations of visual and linguistic contents. In this work, we exploit Transformer for its natural suitability on permutation-invariant 3D point clouds data and propose a TransRefer3D network to extract entity-and-relation aware multimodal context among objects for more discriminative feature learning. Concretely, we devise an Entity-aware Attention (EA) module and a Relation-aware Attention (RA) module to conduct fine-grained cross-modal feature matching. Facilitated by co-attention operation, our EA module matches visual entity features with linguistic entity features while RA module matches pair-wise visual relation features with linguistic relation features, respectively. We further integrate EA and RA modules into an Entity-and-Relation aware Contextual Block (ERCB) and stack several ERCBs to form our TransRefer3D for hierarchical multimodal context modeling. Extensive experiments on both Nr3D and Sr3D datasets demonstrate that our proposed model significantly outperforms existing approaches by up to 10.6% and claims the new state-of-the-art. To the best of our knowledge, this is the first work investigating Transformer architecture for fine-grained 3D visual grounding task.
Mining the Benefits of Two-stage and One-stage HOI Detection
Aug 11, 2021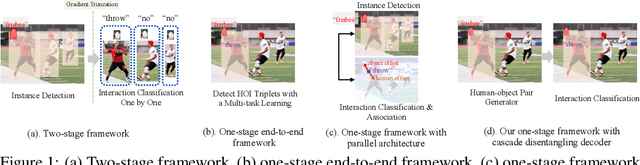
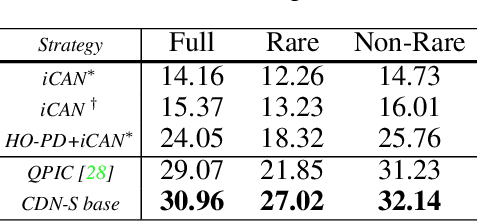
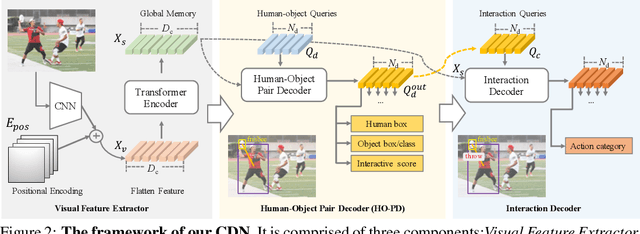
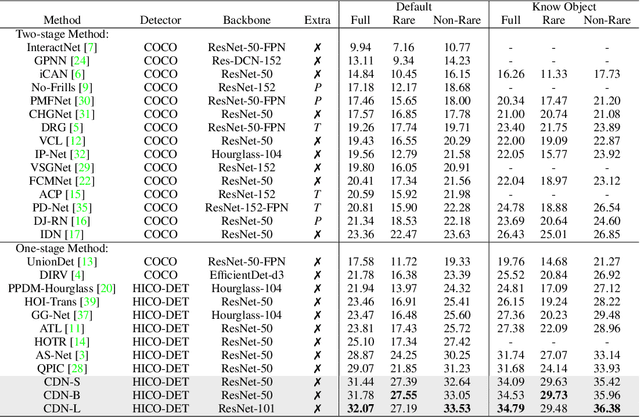
Two-stage methods have dominated Human-Object Interaction (HOI) detection for several years. Recently, one-stage HOI detection methods have become popular. In this paper, we aim to explore the essential pros and cons of two-stage and one-stage methods. With this as the goal, we find that conventional two-stage methods mainly suffer from positioning positive interactive human-object pairs, while one-stage methods are challenging to make an appropriate trade-off on multi-task learning, i.e., object detection, and interaction classification. Therefore, a core problem is how to take the essence and discard the dregs from the conventional two types of methods. To this end, we propose a novel one-stage framework with disentangling human-object detection and interaction classification in a cascade manner. In detail, we first design a human-object pair generator based on a state-of-the-art one-stage HOI detector by removing the interaction classification module or head and then design a relatively isolated interaction classifier to classify each human-object pair. Two cascade decoders in our proposed framework can focus on one specific task, detection or interaction classification. In terms of the specific implementation, we adopt a transformer-based HOI detector as our base model. The newly introduced disentangling paradigm outperforms existing methods by a large margin, with a significant relative mAP gain of 9.32% on HICO-Det.