 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeINFUSER: Influence-Guided Self-Evolution Improves Reasoning
Jun 08, 2026Self-evolution offers a scalable path to stronger reasoning: a pretrained language model improves itself with only minimal external supervision. Yet existing methods either depend on extensively curated or teacher-generated training data, or, when the generator runs unsupervised, reward it by a difficulty heuristic that need not improve the solver. We introduce INFUSER, an iterative co-training framework with two co-evolving roles: a Generator that drafts questions and reference golden answers from a pool of unstructured, automatically collected documents, and a Solver that improves by training on them. The solver is trained with standard correctness rewards against the generator-provided answers, while the generator is rewarded by an optimizer-aware influence score that measures whether each proposed question would actually improve the solver on the target distribution. Because this continuous, noisy influence score is poorly served by standard GRPO, we propose DuGRPO, a dual-normalized variant of GRPO, for generator training. Together, these turn the document pool into an adaptive curriculum that favors questions useful to the current solver, not just hard ones. On Qwen3-8B-Base, INFUSER outperforms strong self-evolution baselines with over 20% relative improvement on Olympiad and SuperGPQA benchmarks, and an 8B INFUSER co-evolving generator outperforms a frozen 32B thinking generator on math and coding. Ablations confirm each design choice is necessary, and two extensions, applying INFUSER to an instruction-finetuned anchor and augmenting it with rule-verifiable RLVR data, further demonstrate the flexibility and generalizability of the framework. Code is available at https://github.com/FFishy-git/INFUSER.
Robust Assortment Optimization from Observational Data
Feb 11, 2026Assortment optimization is a fundamental challenge in modern retail and recommendation systems, where the goal is to select a subset of products that maximizes expected revenue under complex customer choice behaviors. While recent advances in data-driven methods have leveraged historical data to learn and optimize assortments, these approaches typically rely on strong assumptions -- namely, the stability of customer preferences and the correctness of the underlying choice models. However, such assumptions frequently break in real-world scenarios due to preference shifts and model misspecification, leading to poor generalization and revenue loss. Motivated by this limitation, we propose a robust framework for data-driven assortment optimization that accounts for potential distributional shifts in customer choice behavior. Our approach models potential preference shift from a nominal choice model that generates data and seeks to maximize worst-case expected revenue. We first establish the computational tractability of robust assortment planning when the nominal model is known, then advance to the data-driven setting, where we design statistically optimal algorithms that minimize the data requirements while maintaining robustness. Our theoretical analysis provides both upper bounds and matching lower bounds on the sample complexity, offering theoretical guarantees for robust generalization. Notably, we uncover and identify the notion of ``robust item-wise coverage'' as the minimal data requirement to enable sample-efficient robust assortment learning. Our work bridges the gap between robustness and statistical efficiency in assortment learning, contributing new insights and tools for reliable assortment optimization under uncertainty.
Towards Theoretical Understanding of Transformer Test-Time Computing: Investigation on In-Context Linear Regression
Aug 11, 2025Using more test-time computation during language model inference, such as generating more intermediate thoughts or sampling multiple candidate answers, has proven effective in significantly improving model performance. This paper takes an initial step toward bridging the gap between practical language model inference and theoretical transformer analysis by incorporating randomness and sampling. We focus on in-context linear regression with continuous/binary coefficients, where our framework simulates language model decoding through noise injection and binary coefficient sampling. Through this framework, we provide detailed analyses of widely adopted inference techniques. Supported by empirical results, our theoretical framework and analysis demonstrate the potential for offering new insights into understanding inference behaviors in real-world language models.
Learning an Optimal Assortment Policy under Observational Data
Feb 10, 2025We study the fundamental problem of offline assortment optimization under the Multinomial Logit (MNL) model, where sellers must determine the optimal subset of the products to offer based solely on historical customer choice data. While most existing approaches to learning-based assortment optimization focus on the online learning of the optimal assortment through repeated interactions with customers, such exploration can be costly or even impractical in many real-world settings. In this paper, we consider the offline learning paradigm and investigate the minimal data requirements for efficient offline assortment optimization. To this end, we introduce Pessimistic Rank-Breaking (PRB), an algorithm that combines rank-breaking with pessimistic estimation. We prove that PRB is nearly minimax optimal by establishing the tight suboptimality upper bound and a nearly matching lower bound. This further shows that "optimal item coverage" - where each item in the optimal assortment appears sufficiently often in the historical data - is both sufficient and necessary for efficient offline learning. This significantly relaxes the previous requirement of observing the complete optimal assortment in the data. Our results provide fundamental insights into the data requirements for offline assortment optimization under the MNL model.
Provably Mitigating Overoptimization in RLHF: Your SFT Loss is Implicitly an Adversarial Regularizer
May 26, 2024



Aligning generative models with human preference via RLHF typically suffers from overoptimization, where an imperfectly learned reward model can misguide the generative model to output undesired responses. We investigate this problem in a principled manner by identifying the source of the misalignment as a form of distributional shift and uncertainty in learning human preferences. To mitigate overoptimization, we first propose a theoretical algorithm that chooses the best policy for an adversarially chosen reward model; one that simultaneously minimizes the maximum likelihood estimation of the loss and a reward penalty term. Here, the reward penalty term is introduced to prevent the policy from choosing actions with spurious high proxy rewards, resulting in provable sample efficiency of the algorithm under a partial coverage style condition. Moving from theory to practice, the proposed algorithm further enjoys an equivalent but surprisingly easy-to-implement reformulation. Using the equivalence between reward models and the corresponding optimal policy, the algorithm features a simple objective that combines: (i) a preference optimization loss that directly aligns the policy with human preference, and (ii) a supervised learning loss that explicitly imitates the policy with a (suitable) baseline distribution. In the context of aligning large language models (LLM), this objective fuses the direct preference optimization (DPO) loss with the supervised fune-tuning (SFT) loss to help mitigate the overoptimization towards undesired responses, for which we name the algorithm Regularized Preference Optimization (RPO). Experiments of aligning LLMs demonstrate the improved performance of RPO compared with DPO baselines. Our work sheds light on the interplay between preference optimization and SFT in tuning LLMs with both theoretical guarantees and empirical evidence.
Distributionally Robust Reinforcement Learning with Interactive Data Collection: Fundamental Hardness and Near-Optimal Algorithm
Apr 04, 2024The sim-to-real gap, which represents the disparity between training and testing environments, poses a significant challenge in reinforcement learning (RL). A promising approach to addressing this challenge is distributionally robust RL, often framed as a robust Markov decision process (RMDP). In this framework, the objective is to find a robust policy that achieves good performance under the worst-case scenario among all environments within a pre-specified uncertainty set centered around the training environment. Unlike previous work, which relies on a generative model or a pre-collected offline dataset enjoying good coverage of the deployment environment, we tackle robust RL via interactive data collection, where the learner interacts with the training environment only and refines the policy through trial and error. In this robust RL paradigm, two main challenges emerge: managing distributional robustness while striking a balance between exploration and exploitation during data collection. Initially, we establish that sample-efficient learning without additional assumptions is unattainable owing to the curse of support shift; i.e., the potential disjointedness of the distributional supports between the training and testing environments. To circumvent such a hardness result, we introduce the vanishing minimal value assumption to RMDPs with a total-variation (TV) distance robust set, postulating that the minimal value of the optimal robust value function is zero. We prove that such an assumption effectively eliminates the support shift issue for RMDPs with a TV distance robust set, and present an algorithm with a provable sample complexity guarantee. Our work makes the initial step to uncovering the inherent difficulty of robust RL via interactive data collection and sufficient conditions for designing a sample-efficient algorithm accompanied by sharp sample complexity analysis.
Benign Oscillation of Stochastic Gradient Descent with Large Learning Rates
Oct 26, 2023In this work, we theoretically investigate the generalization properties of neural networks (NN) trained by stochastic gradient descent (SGD) algorithm with large learning rates. Under such a training regime, our finding is that, the oscillation of the NN weights caused by the large learning rate SGD training turns out to be beneficial to the generalization of the NN, which potentially improves over the same NN trained by SGD with small learning rates that converges more smoothly. In view of this finding, we call such a phenomenon "benign oscillation". Our theory towards demystifying such a phenomenon builds upon the feature learning perspective of deep learning. Specifically, we consider a feature-noise data generation model that consists of (i) weak features which have a small $\ell_2$-norm and appear in each data point; (ii) strong features which have a larger $\ell_2$-norm but only appear in a certain fraction of all data points; and (iii) noise. We prove that NNs trained by oscillating SGD with a large learning rate can effectively learn the weak features in the presence of those strong features. In contrast, NNs trained by SGD with a small learning rate can only learn the strong features but makes little progress in learning the weak features. Consequently, when it comes to the new testing data which consist of only weak features, the NN trained by oscillating SGD with a large learning rate could still make correct predictions consistently, while the NN trained by small learning rate SGD fails. Our theory sheds light on how large learning rate training benefits the generalization of NNs. Experimental results demonstrate our finding on "benign oscillation".
One Objective to Rule Them All: A Maximization Objective Fusing Estimation and Planning for Exploration
May 29, 2023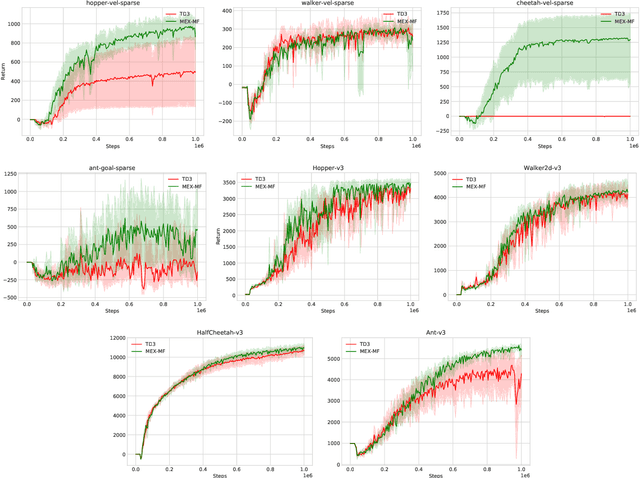
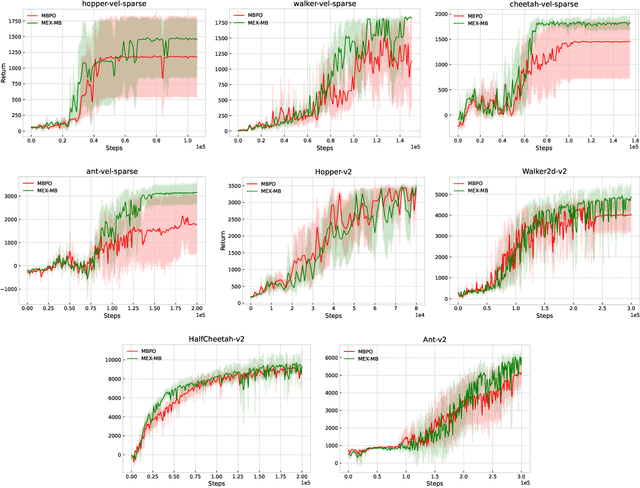

In online reinforcement learning (online RL), balancing exploration and exploitation is crucial for finding an optimal policy in a sample-efficient way. To achieve this, existing sample-efficient online RL algorithms typically consist of three components: estimation, planning, and exploration. However, in order to cope with general function approximators, most of them involve impractical algorithmic components to incentivize exploration, such as optimization within data-dependent level-sets or complicated sampling procedures. To address this challenge, we propose an easy-to-implement RL framework called \textit{Maximize to Explore} (\texttt{MEX}), which only needs to optimize \emph{unconstrainedly} a single objective that integrates the estimation and planning components while balancing exploration and exploitation automatically. Theoretically, we prove that \texttt{MEX} achieves a sublinear regret with general function approximations for Markov decision processes (MDP) and is further extendable to two-player zero-sum Markov games (MG). Meanwhile, we adapt deep RL baselines to design practical versions of \texttt{MEX}, in both model-free and model-based manners, which can outperform baselines by a stable margin in various MuJoCo environments with sparse rewards. Compared with existing sample-efficient online RL algorithms with general function approximations, \texttt{MEX} achieves similar sample efficiency while enjoying a lower computational cost and is more compatible with modern deep RL methods.
Double Pessimism is Provably Efficient for Distributionally Robust Offline Reinforcement Learning: Generic Algorithm and Robust Partial Coverage
May 16, 2023We study distributionally robust offline reinforcement learning (robust offline RL), which seeks to find an optimal robust policy purely from an offline dataset that can perform well in perturbed environments. We propose a generic algorithm framework \underline{D}oubly \underline{P}essimistic \underline{M}odel-based \underline{P}olicy \underline{O}ptimization ($\texttt{P}^2\texttt{MPO}$) for robust offline RL, which features a novel combination of a flexible model estimation subroutine and a doubly pessimistic policy optimization step. The \emph{double pessimism} principle is crucial to overcome the distributional shift incurred by i) the mismatch between behavior policy and the family of target policies; and ii) the perturbation of the nominal model. Under certain accuracy assumptions on the model estimation subroutine, we show that $\texttt{P}^2\texttt{MPO}$ is provably efficient with \emph{robust partial coverage data}, which means that the offline dataset has good coverage of the distributions induced by the optimal robust policy and perturbed models around the nominal model. By tailoring specific model estimation subroutines for concrete examples including tabular Robust Markov Decision Process (RMDP), factored RMDP, and RMDP with kernel and neural function approximations, we show that $\texttt{P}^2\texttt{MPO}$ enjoys a $\tilde{\mathcal{O}}(n^{-1/2})$ convergence rate, where $n$ is the number of trajectories in the offline dataset. Notably, these models, except for the tabular case, are first identified and proven tractable by this paper. To the best of our knowledge, we first propose a general learning principle -- double pessimism -- for robust offline RL and show that it is provably efficient in the context of general function approximations.
Robust Consensus Clustering and its Applications for Advertising Forecasting
Dec 27, 2022Consensus clustering aggregates partitions in order to find a better fit by reconciling clustering results from different sources/executions. In practice, there exist noise and outliers in clustering task, which, however, may significantly degrade the performance. To address this issue, we propose a novel algorithm -- robust consensus clustering that can find common ground truth among experts' opinions, which tends to be minimally affected by the bias caused by the outliers. In particular, we formalize the robust consensus clustering problem as a constraint optimization problem, and then derive an effective algorithm upon alternating direction method of multipliers (ADMM) with rigorous convergence guarantee. Our method outperforms the baselines on benchmarks. We apply the proposed method to the real-world advertising campaign segmentation and forecasting tasks using the proposed consensus clustering results based on the similarity computed via Kolmogorov-Smirnov Statistics. The accurate clustering result is helpful for building the advertiser profiles so as to perform the forecasting.