 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBRiTE: Bootstrapping Reinforced Thinking Process to Enhance Language Model Reasoning
Jan 31, 2025



Large Language Models (LLMs) have demonstrated remarkable capabilities in complex reasoning tasks, yet generating reliable reasoning processes remains a significant challenge. We present a unified probabilistic framework that formalizes LLM reasoning through a novel graphical model incorporating latent thinking processes and evaluation signals. Within this framework, we introduce the Bootstrapping Reinforced Thinking Process (BRiTE) algorithm, which works in two steps. First, it generates high-quality rationales by approximating the optimal thinking process through reinforcement learning, using a novel reward shaping mechanism. Second, it enhances the base LLM by maximizing the joint probability of rationale generation with respect to the model's parameters. Theoretically, we demonstrate BRiTE's convergence at a rate of $1/T$ with $T$ representing the number of iterations. Empirical evaluations on math and coding benchmarks demonstrate that our approach consistently improves performance across different base models without requiring human-annotated thinking processes. In addition, BRiTE demonstrates superior performance compared to existing algorithms that bootstrap thinking processes use alternative methods such as rejection sampling, and can even match or exceed the results achieved through supervised fine-tuning with human-annotated data.
Toward Optimal LLM Alignments Using Two-Player Games
Jun 16, 2024



The standard Reinforcement Learning from Human Feedback (RLHF) framework primarily focuses on optimizing the performance of large language models using pre-collected prompts. However, collecting prompts that provide comprehensive coverage is both tedious and challenging, and often fails to include scenarios that LLMs need to improve on the most. In this paper, we investigate alignment through the lens of two-agent games, involving iterative interactions between an adversarial and a defensive agent. The adversarial agent's task at each step is to generate prompts that expose the weakness of the defensive agent. In return, the defensive agent seeks to improve its responses to these newly identified prompts it struggled with, based on feedback from the reward model. We theoretically demonstrate that this iterative reinforcement learning optimization converges to a Nash Equilibrium for the game induced by the agents. Experimental results in safety scenarios demonstrate that learning in such a competitive environment not only fully trains agents but also leads to policies with enhanced generalization capabilities for both adversarial and defensive agents.
Provably Mitigating Overoptimization in RLHF: Your SFT Loss is Implicitly an Adversarial Regularizer
May 26, 2024



Aligning generative models with human preference via RLHF typically suffers from overoptimization, where an imperfectly learned reward model can misguide the generative model to output undesired responses. We investigate this problem in a principled manner by identifying the source of the misalignment as a form of distributional shift and uncertainty in learning human preferences. To mitigate overoptimization, we first propose a theoretical algorithm that chooses the best policy for an adversarially chosen reward model; one that simultaneously minimizes the maximum likelihood estimation of the loss and a reward penalty term. Here, the reward penalty term is introduced to prevent the policy from choosing actions with spurious high proxy rewards, resulting in provable sample efficiency of the algorithm under a partial coverage style condition. Moving from theory to practice, the proposed algorithm further enjoys an equivalent but surprisingly easy-to-implement reformulation. Using the equivalence between reward models and the corresponding optimal policy, the algorithm features a simple objective that combines: (i) a preference optimization loss that directly aligns the policy with human preference, and (ii) a supervised learning loss that explicitly imitates the policy with a (suitable) baseline distribution. In the context of aligning large language models (LLM), this objective fuses the direct preference optimization (DPO) loss with the supervised fune-tuning (SFT) loss to help mitigate the overoptimization towards undesired responses, for which we name the algorithm Regularized Preference Optimization (RPO). Experiments of aligning LLMs demonstrate the improved performance of RPO compared with DPO baselines. Our work sheds light on the interplay between preference optimization and SFT in tuning LLMs with both theoretical guarantees and empirical evidence.
Diverse Randomized Value Functions: A Provably Pessimistic Approach for Offline Reinforcement Learning
Apr 09, 2024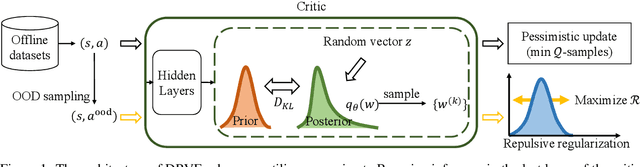
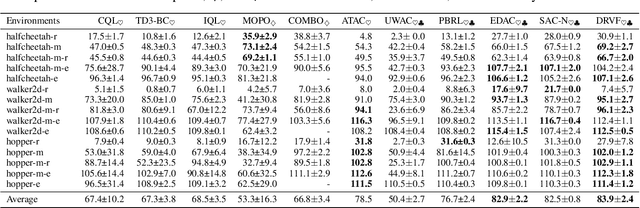

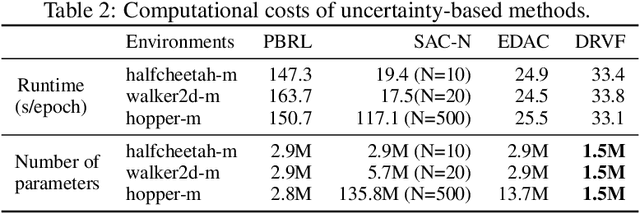
Offline Reinforcement Learning (RL) faces distributional shift and unreliable value estimation, especially for out-of-distribution (OOD) actions. To address this, existing uncertainty-based methods penalize the value function with uncertainty quantification and demand numerous ensemble networks, posing computational challenges and suboptimal outcomes. In this paper, we introduce a novel strategy employing diverse randomized value functions to estimate the posterior distribution of $Q$-values. It provides robust uncertainty quantification and estimates lower confidence bounds (LCB) of $Q$-values. By applying moderate value penalties for OOD actions, our method fosters a provably pessimistic approach. We also emphasize on diversity within randomized value functions and enhance efficiency by introducing a diversity regularization method, reducing the requisite number of networks. These modules lead to reliable value estimation and efficient policy learning from offline data. Theoretical analysis shows that our method recovers the provably efficient LCB-penalty under linear MDP assumptions. Extensive empirical results also demonstrate that our proposed method significantly outperforms baseline methods in terms of performance and parametric efficiency.
Improving Reinforcement Learning from Human Feedback Using Contrastive Rewards
Mar 14, 2024



Reinforcement learning from human feedback (RLHF) is the mainstream paradigm used to align large language models (LLMs) with human preferences. Yet existing RLHF heavily relies on accurate and informative reward models, which are vulnerable and sensitive to noise from various sources, e.g. human labeling errors, making the pipeline fragile. In this work, we improve the effectiveness of the reward model by introducing a penalty term on the reward, named as \textit{contrastive rewards}. %Contrastive rewards Our approach involves two steps: (1) an offline sampling step to obtain responses to prompts that serve as baseline calculation and (2) a contrastive reward calculated using the baseline responses and used in the Proximal Policy Optimization (PPO) step. We show that contrastive rewards enable the LLM to penalize reward uncertainty, improve robustness, encourage improvement over baselines, calibrate according to task difficulty, and reduce variance in PPO. We show empirically contrastive rewards can improve RLHF substantially, evaluated by both GPTs and humans, and our method consistently outperforms strong baselines.
Can Large Language Models Play Games? A Case Study of A Self-Play Approach
Mar 08, 2024



Large Language Models (LLMs) harness extensive data from the Internet, storing a broad spectrum of prior knowledge. While LLMs have proven beneficial as decision-making aids, their reliability is hampered by limitations in reasoning, hallucination phenomenon, and so on. On the other hand, Monte-Carlo Tree Search (MCTS) is a heuristic search algorithm that provides reliable decision-making solutions, achieved through recursive rollouts and self-play. However, the effectiveness of MCTS relies heavily on heuristic pruning and external value functions, particularly in complex decision scenarios. This work introduces an innovative approach that bolsters LLMs with MCTS self-play to efficiently resolve deterministic turn-based zero-sum games (DTZG), such as chess and go, without the need for additional training. Specifically, we utilize LLMs as both action pruners and proxies for value functions without the need for additional training. We theoretically prove that the suboptimality of the estimated value in our proposed method scales with $\tilde{\mathcal O}\Bigl(\frac{|\tilde {\mathcal A}|}{\sqrt{N}} + \epsilon_\mathrm{pruner} + \epsilon_\mathrm{critic}\Bigr)$, where \(N\) is the number of simulations, $|\tilde {\mathcal A}|$ is the cardinality of the pruned action space by LLM, and $\epsilon_\mathrm{pruner}$ and $\epsilon_\mathrm{critic}$ quantify the errors incurred by adopting LLMs as action space pruner and value function proxy, respectively. Our experiments in chess and go demonstrate the capability of our method to address challenges beyond the scope of MCTS and improve the performance of the directly application of LLMs.
Measuring and Reducing LLM Hallucination without Gold-Standard Answers via Expertise-Weighting
Feb 16, 2024LLM hallucination, i.e. generating factually incorrect yet seemingly convincing answers, is currently a major threat to the trustworthiness and reliability of LLMs. The first step towards solving this complicated problem is to measure it. However, existing hallucination metrics require to have a benchmark dataset with gold-standard answers, i.e. "best" or "correct" answers written by humans. Such requirement makes hallucination measurement costly and prone to human errors. In this work, we propose Factualness Evaluations via Weighting LLMs (FEWL), the first hallucination metric that is specifically designed for the scenario when gold-standard answers are absent. FEWL leverages the answers from off-the-shelf LLMs that serve as a proxy of gold-standard answers. The key challenge is how to quantify the expertise of reference LLMs resourcefully. We show FEWL has certain theoretical guarantees and demonstrate empirically it gives more accurate hallucination measures than naively using reference LLMs. We also show how to leverage FEWL to reduce hallucination through both in-context learning and supervised finetuning. Last, we build a large-scale benchmark dataset to facilitate LLM hallucination research.
Human-Instruction-Free LLM Self-Alignment with Limited Samples
Jan 06, 2024Aligning large language models (LLMs) with human values is a vital task for LLM practitioners. Current alignment techniques have several limitations: (1) requiring a large amount of annotated data; (2) demanding heavy human involvement; (3) lacking a systematic mechanism to continuously improve. In this work, we study aligning LLMs to a new domain with limited samples (e.g. < 100). We propose an algorithm that can self-align LLMs iteratively without active human involvement. Unlike existing works, our algorithm relies on neither human-crafted instructions nor labeled rewards, significantly reducing human involvement. In addition, our algorithm can self-improve the alignment continuously. The key idea is to first retrieve high-quality samples related to the target domain and use them as In-context Learning examples to generate more samples. Then we use the self-generated samples to finetune the LLM iteratively. We show that our method can unlock the LLMs' self-generalization ability to perform alignment with near-zero human supervision. We test our algorithm on three benchmarks in safety, truthfulness, and instruction-following, and show good performance in alignment, domain adaptability, and scalability.
Reason for Future, Act for Now: A Principled Framework for Autonomous LLM Agents with Provable Sample Efficiency
Oct 11, 2023



Large language models (LLMs) demonstrate impressive reasoning abilities, but translating reasoning into actions in the real world remains challenging. In particular, it remains unclear how to complete a given task provably within a minimum number of interactions with the external environment, e.g., through an internal mechanism of reasoning. To this end, we propose a principled framework with provable regret guarantees to orchestrate reasoning and acting, which we call "reason for future, act for now" (\texttt{RAFA}). Specifically, we design a prompt template for reasoning that learns from the memory buffer and plans a future trajectory over a long horizon ("reason for future"). At each step, the LLM agent takes the initial action of the planned trajectory ("act for now"), stores the collected feedback in the memory buffer, and reinvokes the reasoning routine to replan the future trajectory from the new state. The key idea is to cast reasoning in LLMs as learning and planning in Bayesian adaptive Markov decision processes (MDPs). Correspondingly, we prompt LLMs to form an updated posterior of the unknown environment from the memory buffer (learning) and generate an optimal trajectory for multiple future steps that maximizes a value function (planning). The learning and planning subroutines are performed in an "in-context" manner to emulate the actor-critic update for MDPs. Our theoretical analysis proves that the novel combination of long-term reasoning and short-term acting achieves a $\sqrt{T}$ regret. In particular, the regret bound highlights an intriguing interplay between the prior knowledge obtained through pretraining and the uncertainty reduction achieved by reasoning and acting. Our empirical validation shows that it outperforms various existing frameworks and achieves nearly perfect scores on a few benchmarks.
Behavior Contrastive Learning for Unsupervised Skill Discovery
May 08, 2023



In reinforcement learning, unsupervised skill discovery aims to learn diverse skills without extrinsic rewards. Previous methods discover skills by maximizing the mutual information (MI) between states and skills. However, such an MI objective tends to learn simple and static skills and may hinder exploration. In this paper, we propose a novel unsupervised skill discovery method through contrastive learning among behaviors, which makes the agent produce similar behaviors for the same skill and diverse behaviors for different skills. Under mild assumptions, our objective maximizes the MI between different behaviors based on the same skill, which serves as an upper bound of the previous MI objective. Meanwhile, our method implicitly increases the state entropy to obtain better state coverage. We evaluate our method on challenging mazes and continuous control tasks. The results show that our method generates diverse and far-reaching skills, and also obtains competitive performance in downstream tasks compared to the state-of-the-art methods.