 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBellman-Taylor Score Decoding for Markov Decision Processes with State-Dependent Feasible Action Sets
Jun 09, 2026Many Markov decision processes (MDPs) in operations research have feasible actions that are state dependent and defined implicitly by various operational constraints. These features make it difficult to use standard deep reinforcement learning (DRL) algorithms, whose action interfaces typically assume either a fixed finite action catalog or a simple Euclidean space. Motivated by a Taylor expansion of the optimal action-value function, we propose Bellman--Taylor score decoding, a framework that moves policy learning to a Euclidean score space while enforcing feasibility through an action decoder. The induced latent-score MDP then can be optimized by standard DRL algorithms without differentiating through the decoder. We provide a performance guarantee showing that the optimality gap of this approach decomposes into a structural approximation error and an algorithmic learning error. Lastly, we apply this framework to a queueing network control problem, where the policy essentially learns a state-dependent index-based dispatching rule. Numerical experiments show near-optimal performance in small instances and considerable improvements over benchmarks in larger systems.
ALOE: Action-Level Off-Policy Evaluation for Vision-Language-Action Model Post-Training
Feb 13, 2026We study how to improve large foundation vision-language-action (VLA) systems through online reinforcement learning (RL) in real-world settings. Central to this process is the value function, which provides learning signals to guide VLA learning from experience. In practice, the value function is estimated from trajectory fragments collected from different data sources, including historical policies and intermittent human interventions. Estimating the value function of current behavior quality from the mixture data is inherently an off-policy evaluation problem. However, prior work often adopts conservative on-policy estimation for stability, which avoids direct evaluation of the current high-capacity policy and limits learning effectiveness. In this paper, we propose ALOE, an action-level off-policy evaluation framework for VLA post-training. ALOE applies chunking-based temporal-difference bootstrapping to evaluate individual action sequences instead of predicting final task outcomes. This design improves effective credit assignment to critical action chunks under sparse rewards and supports stable policy improvement. We evaluate our method on three real-world manipulation tasks, including smartphone packing as a high-precision task, laundry folding as a long-horizon deformable-object task, and bimanual pick-and-place involving multi-object perception. Across all tasks, ALOE improves learning efficiency without compromising execution speed, showing that off-policy RL can be reintroduced in a reliable manner for real-world VLA post-training. Videos and additional materials are available at our project website.
How Do VLAs Effectively Inherit from VLMs?
Nov 10, 2025Vision-language-action (VLA) models hold the promise to attain generalizable embodied control. To achieve this, a pervasive paradigm is to leverage the rich vision-semantic priors of large vision-language models (VLMs). However, the fundamental question persists: How do VLAs effectively inherit the prior knowledge from VLMs? To address this critical question, we introduce a diagnostic benchmark, GrinningFace, an emoji tabletop manipulation task where the robot arm is asked to place objects onto printed emojis corresponding to language instructions. This task design is particularly revealing -- knowledge associated with emojis is ubiquitous in Internet-scale datasets used for VLM pre-training, yet emojis themselves are largely absent from standard robotics datasets. Consequently, they provide a clean proxy: successful task completion indicates effective transfer of VLM priors to embodied control. We implement this diagnostic task in both simulated environment and a real robot, and compare various promising techniques for knowledge transfer. Specifically, we investigate the effects of parameter-efficient fine-tuning, VLM freezing, co-training, predicting discretized actions, and predicting latent actions. Through systematic evaluation, our work not only demonstrates the critical importance of preserving VLM priors for the generalization of VLA but also establishes guidelines for future research in developing truly generalizable embodied AI systems.
villa-X: Enhancing Latent Action Modeling in Vision-Language-Action Models
Jul 31, 2025Visual-Language-Action (VLA) models have emerged as a popular paradigm for learning robot manipulation policies that can follow language instructions and generalize to novel scenarios. Recent work has begun to explore the incorporation of latent actions, an abstract representation of visual change between two frames, into VLA pre-training. In this paper, we introduce villa-X, a novel Visual-Language-Latent-Action (ViLLA) framework that advances latent action modeling for learning generalizable robot manipulation policies. Our approach improves both how latent actions are learned and how they are incorporated into VLA pre-training. Together, these contributions enable villa-X to achieve superior performance across simulated environments including SIMPLER and LIBERO, as well as on two real-world robot setups including gripper and dexterous hand manipulation. We believe the ViLLA paradigm holds significant promise, and that our villa-X provides a strong foundation for future research.
PIG-Nav: Key Insights for Pretrained Image Goal Navigation Models
Jul 23, 2025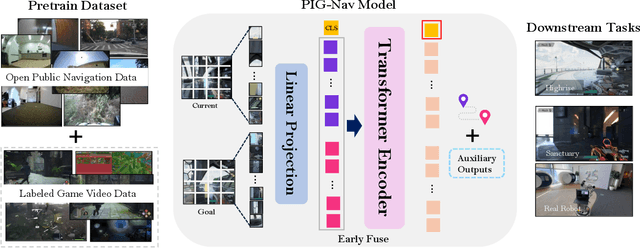
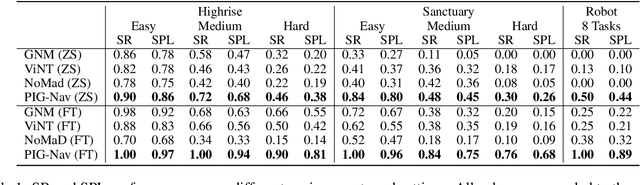
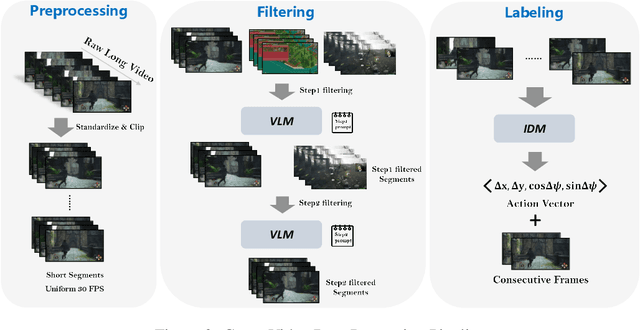
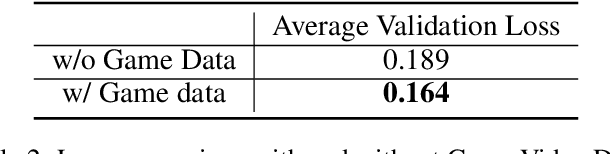
Recent studies have explored pretrained (foundation) models for vision-based robotic navigation, aiming to achieve generalizable navigation and positive transfer across diverse environments while enhancing zero-shot performance in unseen settings. In this work, we introduce PIG-Nav (Pretrained Image-Goal Navigation), a new approach that further investigates pretraining strategies for vision-based navigation models and contributes in two key areas. Model-wise, we identify two critical design choices that consistently improve the performance of pretrained navigation models: (1) integrating an early-fusion network structure to combine visual observations and goal images via appropriately pretrained Vision Transformer (ViT) image encoder, and (2) introducing suitable auxiliary tasks to enhance global navigation representation learning, thus further improving navigation performance. Dataset-wise, we propose a novel data preprocessing pipeline for efficiently labeling large-scale game video datasets for navigation model training. We demonstrate that augmenting existing open navigation datasets with diverse gameplay videos improves model performance. Our model achieves an average improvement of 22.6% in zero-shot settings and a 37.5% improvement in fine-tuning settings over existing visual navigation foundation models in two complex simulated environments and one real-world environment. These results advance the state-of-the-art in pretrained image-goal navigation models. Notably, our model maintains competitive performance while requiring significantly less fine-tuning data, highlighting its potential for real-world deployment with minimal labeled supervision.
Unsupervised Skill Discovery through Skill Regions Differentiation
Jun 17, 2025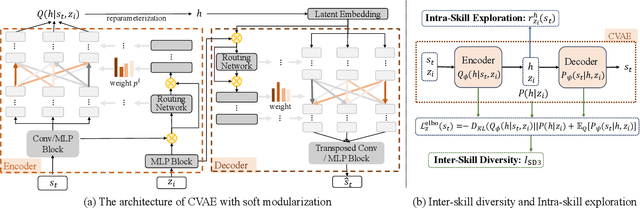
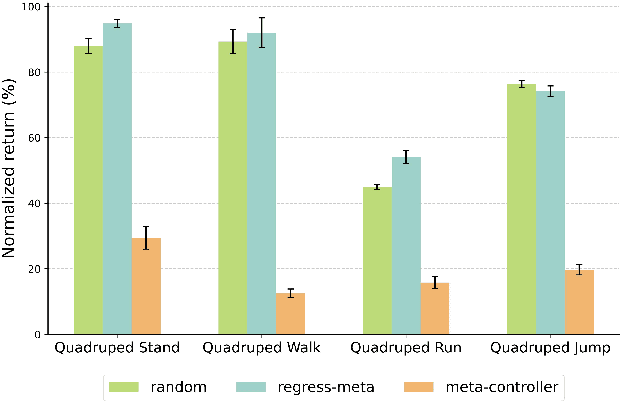
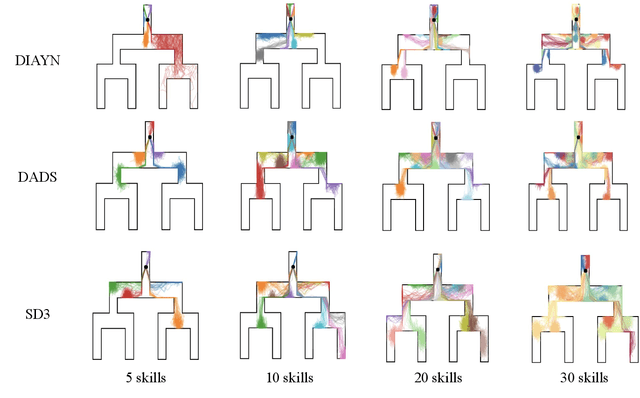

Unsupervised Reinforcement Learning (RL) aims to discover diverse behaviors that can accelerate the learning of downstream tasks. Previous methods typically focus on entropy-based exploration or empowerment-driven skill learning. However, entropy-based exploration struggles in large-scale state spaces (e.g., images), and empowerment-based methods with Mutual Information (MI) estimations have limitations in state exploration. To address these challenges, we propose a novel skill discovery objective that maximizes the deviation of the state density of one skill from the explored regions of other skills, encouraging inter-skill state diversity similar to the initial MI objective. For state-density estimation, we construct a novel conditional autoencoder with soft modularization for different skill policies in high-dimensional space. Meanwhile, to incentivize intra-skill exploration, we formulate an intrinsic reward based on the learned autoencoder that resembles count-based exploration in a compact latent space. Through extensive experiments in challenging state and image-based tasks, we find our method learns meaningful skills and achieves superior performance in various downstream tasks.
Supervised Optimism Correction: Be Confident When LLMs Are Sure
Apr 10, 2025In this work, we establish a novel theoretical connection between supervised fine-tuning and offline reinforcement learning under the token-level Markov decision process, revealing that large language models indeed learn an implicit $Q$-function for inference. Through this theoretical lens, we demonstrate that the widely used beam search method suffers from unacceptable over-optimism, where inference errors are inevitably amplified due to inflated $Q$-value estimations of suboptimal steps. To address this limitation, we propose Supervised Optimism Correction(SOC), which introduces a simple yet effective auxiliary loss for token-level $Q$-value estimations during supervised fine-tuning. Specifically, the auxiliary loss employs implicit value regularization to boost model confidence in expert-demonstrated responses, thereby suppressing over-optimism toward insufficiently supervised responses. Extensive experiments on mathematical reasoning benchmarks, including GSM8K, MATH, and GAOKAO, showcase the superiority of the proposed SOC with beam search across a series of open-source models.
Constrained Ensemble Exploration for Unsupervised Skill Discovery
May 25, 2024Unsupervised Reinforcement Learning (RL) provides a promising paradigm for learning useful behaviors via reward-free per-training. Existing methods for unsupervised RL mainly conduct empowerment-driven skill discovery or entropy-based exploration. However, empowerment often leads to static skills, and pure exploration only maximizes the state coverage rather than learning useful behaviors. In this paper, we propose a novel unsupervised RL framework via an ensemble of skills, where each skill performs partition exploration based on the state prototypes. Thus, each skill can explore the clustered area locally, and the ensemble skills maximize the overall state coverage. We adopt state-distribution constraints for the skill occupancy and the desired cluster for learning distinguishable skills. Theoretical analysis is provided for the state entropy and the resulting skill distributions. Based on extensive experiments on several challenging tasks, we find our method learns well-explored ensemble skills and achieves superior performance in various downstream tasks compared to previous methods.
Behavior Contrastive Learning for Unsupervised Skill Discovery
May 08, 2023



In reinforcement learning, unsupervised skill discovery aims to learn diverse skills without extrinsic rewards. Previous methods discover skills by maximizing the mutual information (MI) between states and skills. However, such an MI objective tends to learn simple and static skills and may hinder exploration. In this paper, we propose a novel unsupervised skill discovery method through contrastive learning among behaviors, which makes the agent produce similar behaviors for the same skill and diverse behaviors for different skills. Under mild assumptions, our objective maximizes the MI between different behaviors based on the same skill, which serves as an upper bound of the previous MI objective. Meanwhile, our method implicitly increases the state entropy to obtain better state coverage. We evaluate our method on challenging mazes and continuous control tasks. The results show that our method generates diverse and far-reaching skills, and also obtains competitive performance in downstream tasks compared to the state-of-the-art methods.