 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeValue-Based Pre-Training with Downstream Feedback
Jan 29, 2026Can a small amount of verified goal information steer the expensive self-supervised pretraining of foundation models? Standard pretraining optimizes a fixed proxy objective (e.g., next-token prediction), which can misallocate compute away from downstream capabilities of interest. We introduce V-Pretraining: a value-based, modality-agnostic method for controlled continued pretraining in which a lightweight task designer reshapes the pretraining task to maximize the value of each gradient step. For example, consider self-supervised learning (SSL) with sample augmentation. The V-Pretraining task designer selects pretraining tasks (e.g., augmentations) for which the pretraining loss gradient is aligned with a gradient computed over a downstream task (e.g., image segmentation). This helps steer pretraining towards relevant downstream capabilities. Notably, the pretrained model is never updated on downstream task labels; they are used only to shape the pretraining task. Under matched learner update budgets, V-Pretraining of 0.5B--7B language models improves reasoning (GSM8K test Pass@1) by up to 18% relative over standard next-token prediction using only 12% of GSM8K training examples as feedback. In vision SSL, we improve the state-of-the-art results on ADE20K by up to 1.07 mIoU and reduce NYUv2 RMSE while improving ImageNet linear accuracy, and we provide pilot evidence of improved token efficiency in continued pretraining.
On the Convergence of Differentially-Private Fine-tuning: To Linearly Probe or to Fully Fine-tune?
Feb 29, 2024


Differentially private (DP) machine learning pipelines typically involve a two-phase process: non-private pre-training on a public dataset, followed by fine-tuning on private data using DP optimization techniques. In the DP setting, it has been observed that full fine-tuning may not always yield the best test accuracy, even for in-distribution data. This paper (1) analyzes the training dynamics of DP linear probing (LP) and full fine-tuning (FT), and (2) explores the phenomenon of sequential fine-tuning, starting with linear probing and transitioning to full fine-tuning (LP-FT), and its impact on test loss. We provide theoretical insights into the convergence of DP fine-tuning within an overparameterized neural network and establish a utility curve that determines the allocation of privacy budget between linear probing and full fine-tuning. The theoretical results are supported by empirical evaluations on various benchmarks and models. The findings reveal the complex nature of DP fine-tuning methods. These results contribute to a deeper understanding of DP machine learning and highlight the importance of considering the allocation of privacy budget in the fine-tuning process.
How Can LLM Guide RL? A Value-Based Approach
Feb 25, 2024
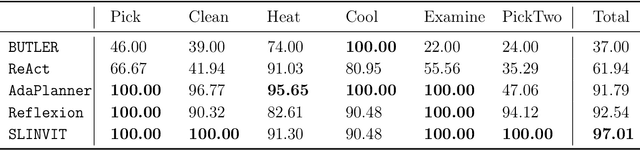

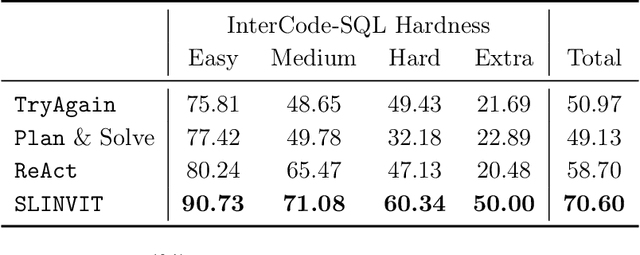
Reinforcement learning (RL) has become the de facto standard practice for sequential decision-making problems by improving future acting policies with feedback. However, RL algorithms may require extensive trial-and-error interactions to collect useful feedback for improvement. On the other hand, recent developments in large language models (LLMs) have showcased impressive capabilities in language understanding and generation, yet they fall short in exploration and self-improvement capabilities for planning tasks, lacking the ability to autonomously refine their responses based on feedback. Therefore, in this paper, we study how the policy prior provided by the LLM can enhance the sample efficiency of RL algorithms. Specifically, we develop an algorithm named LINVIT that incorporates LLM guidance as a regularization factor in value-based RL, leading to significant reductions in the amount of data needed for learning, particularly when the difference between the ideal policy and the LLM-informed policy is small, which suggests that the initial policy is close to optimal, reducing the need for further exploration. Additionally, we present a practical algorithm SLINVIT that simplifies the construction of the value function and employs subgoals to reduce the search complexity. Our experiments across three interactive environments ALFWorld, InterCode, and BlocksWorld demonstrate that our method achieves state-of-the-art success rates and also surpasses previous RL and LLM approaches in terms of sample efficiency. Our code is available at https://github.com/agentification/Language-Integrated-VI.
Reason for Future, Act for Now: A Principled Framework for Autonomous LLM Agents with Provable Sample Efficiency
Oct 11, 2023



Large language models (LLMs) demonstrate impressive reasoning abilities, but translating reasoning into actions in the real world remains challenging. In particular, it remains unclear how to complete a given task provably within a minimum number of interactions with the external environment, e.g., through an internal mechanism of reasoning. To this end, we propose a principled framework with provable regret guarantees to orchestrate reasoning and acting, which we call "reason for future, act for now" (\texttt{RAFA}). Specifically, we design a prompt template for reasoning that learns from the memory buffer and plans a future trajectory over a long horizon ("reason for future"). At each step, the LLM agent takes the initial action of the planned trajectory ("act for now"), stores the collected feedback in the memory buffer, and reinvokes the reasoning routine to replan the future trajectory from the new state. The key idea is to cast reasoning in LLMs as learning and planning in Bayesian adaptive Markov decision processes (MDPs). Correspondingly, we prompt LLMs to form an updated posterior of the unknown environment from the memory buffer (learning) and generate an optimal trajectory for multiple future steps that maximizes a value function (planning). The learning and planning subroutines are performed in an "in-context" manner to emulate the actor-critic update for MDPs. Our theoretical analysis proves that the novel combination of long-term reasoning and short-term acting achieves a $\sqrt{T}$ regret. In particular, the regret bound highlights an intriguing interplay between the prior knowledge obtained through pretraining and the uncertainty reduction achieved by reasoning and acting. Our empirical validation shows that it outperforms various existing frameworks and achieves nearly perfect scores on a few benchmarks.
Quantifying the Impact of Label Noise on Federated Learning
Nov 15, 2022



Federated Learning (FL) is a distributed machine learning paradigm where clients collaboratively train a model using their local (human-generated) datasets while preserving privacy. While existing studies focus on FL algorithm development to tackle data heterogeneity across clients, the important issue of data quality (e.g., label noise) in FL is overlooked. This paper aims to fill this gap by providing a quantitative study on the impact of label noise on FL. Theoretically speaking, we derive an upper bound for the generalization error that is linear in the clients' label noise level. Empirically speaking, we conduct experiments on MNIST and CIFAR-10 datasets using various FL algorithms. We show that the global model accuracy linearly decreases as the noise level increases, which is consistent with our theoretical analysis. We further find that label noise slows down the convergence of FL training, and the global model tends to overfit when the noise level is high.