 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBRiTE: Bootstrapping Reinforced Thinking Process to Enhance Language Model Reasoning
Jan 31, 2025



Large Language Models (LLMs) have demonstrated remarkable capabilities in complex reasoning tasks, yet generating reliable reasoning processes remains a significant challenge. We present a unified probabilistic framework that formalizes LLM reasoning through a novel graphical model incorporating latent thinking processes and evaluation signals. Within this framework, we introduce the Bootstrapping Reinforced Thinking Process (BRiTE) algorithm, which works in two steps. First, it generates high-quality rationales by approximating the optimal thinking process through reinforcement learning, using a novel reward shaping mechanism. Second, it enhances the base LLM by maximizing the joint probability of rationale generation with respect to the model's parameters. Theoretically, we demonstrate BRiTE's convergence at a rate of $1/T$ with $T$ representing the number of iterations. Empirical evaluations on math and coding benchmarks demonstrate that our approach consistently improves performance across different base models without requiring human-annotated thinking processes. In addition, BRiTE demonstrates superior performance compared to existing algorithms that bootstrap thinking processes use alternative methods such as rejection sampling, and can even match or exceed the results achieved through supervised fine-tuning with human-annotated data.
BabelBench: An Omni Benchmark for Code-Driven Analysis of Multimodal and Multistructured Data
Oct 01, 2024



Large language models (LLMs) have become increasingly pivotal across various domains, especially in handling complex data types. This includes structured data processing, as exemplified by ChartQA and ChatGPT-Ada, and multimodal unstructured data processing as seen in Visual Question Answering (VQA). These areas have attracted significant attention from both industry and academia. Despite this, there remains a lack of unified evaluation methodologies for these diverse data handling scenarios. In response, we introduce BabelBench, an innovative benchmark framework that evaluates the proficiency of LLMs in managing multimodal multistructured data with code execution. BabelBench incorporates a dataset comprising 247 meticulously curated problems that challenge the models with tasks in perception, commonsense reasoning, logical reasoning, and so on. Besides the basic capabilities of multimodal understanding, structured data processing as well as code generation, these tasks demand advanced capabilities in exploration, planning, reasoning and debugging. Our experimental findings on BabelBench indicate that even cutting-edge models like ChatGPT 4 exhibit substantial room for improvement. The insights derived from our comprehensive analysis offer valuable guidance for future research within the community. The benchmark data can be found at https://github.com/FFD8FFE/babelbench.
How Can LLM Guide RL? A Value-Based Approach
Feb 25, 2024
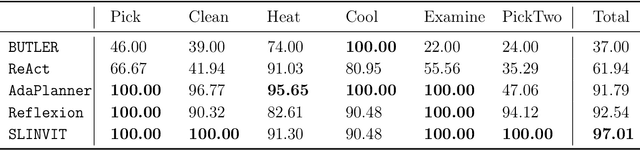

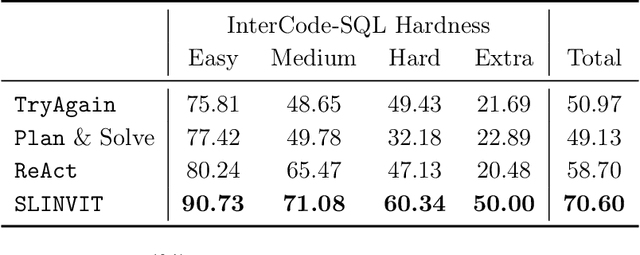
Reinforcement learning (RL) has become the de facto standard practice for sequential decision-making problems by improving future acting policies with feedback. However, RL algorithms may require extensive trial-and-error interactions to collect useful feedback for improvement. On the other hand, recent developments in large language models (LLMs) have showcased impressive capabilities in language understanding and generation, yet they fall short in exploration and self-improvement capabilities for planning tasks, lacking the ability to autonomously refine their responses based on feedback. Therefore, in this paper, we study how the policy prior provided by the LLM can enhance the sample efficiency of RL algorithms. Specifically, we develop an algorithm named LINVIT that incorporates LLM guidance as a regularization factor in value-based RL, leading to significant reductions in the amount of data needed for learning, particularly when the difference between the ideal policy and the LLM-informed policy is small, which suggests that the initial policy is close to optimal, reducing the need for further exploration. Additionally, we present a practical algorithm SLINVIT that simplifies the construction of the value function and employs subgoals to reduce the search complexity. Our experiments across three interactive environments ALFWorld, InterCode, and BlocksWorld demonstrate that our method achieves state-of-the-art success rates and also surpasses previous RL and LLM approaches in terms of sample efficiency. Our code is available at https://github.com/agentification/Language-Integrated-VI.
One Objective to Rule Them All: A Maximization Objective Fusing Estimation and Planning for Exploration
May 29, 2023In online reinforcement learning (online RL), balancing exploration and exploitation is crucial for finding an optimal policy in a sample-efficient way. To achieve this, existing sample-efficient online RL algorithms typically consist of three components: estimation, planning, and exploration. However, in order to cope with general function approximators, most of them involve impractical algorithmic components to incentivize exploration, such as optimization within data-dependent level-sets or complicated sampling procedures. To address this challenge, we propose an easy-to-implement RL framework called \textit{Maximize to Explore} (\texttt{MEX}), which only needs to optimize \emph{unconstrainedly} a single objective that integrates the estimation and planning components while balancing exploration and exploitation automatically. Theoretically, we prove that \texttt{MEX} achieves a sublinear regret with general function approximations for Markov decision processes (MDP) and is further extendable to two-player zero-sum Markov games (MG). Meanwhile, we adapt deep RL baselines to design practical versions of \texttt{MEX}, in both model-free and model-based manners, which can outperform baselines by a stable margin in various MuJoCo environments with sparse rewards. Compared with existing sample-efficient online RL algorithms with general function approximations, \texttt{MEX} achieves similar sample efficiency while enjoying a lower computational cost and is more compatible with modern deep RL methods.
A Posterior Sampling Framework for Interactive Decision Making
Nov 03, 2022We study sample efficient reinforcement learning (RL) under the general framework of interactive decision making, which includes Markov decision process (MDP), partially observable Markov decision process (POMDP), and predictive state representation (PSR) as special cases. Toward finding the minimum assumption that empowers sample efficient learning, we propose a novel complexity measure, generalized eluder coefficient (GEC), which characterizes the fundamental tradeoff between exploration and exploitation in online interactive decision making. In specific, GEC captures the hardness of exploration by comparing the error of predicting the performance of the updated policy with the in-sample training error evaluated on the historical data. We show that RL problems with low GEC form a remarkably rich class, which subsumes low Bellman eluder dimension problems, bilinear class, low witness rank problems, PO-bilinear class, and generalized regular PSR, where generalized regular PSR, a new tractable PSR class identified by us, includes nearly all known tractable POMDPs. Furthermore, in terms of algorithm design, we propose a generic posterior sampling algorithm, which can be implemented in both model-free and model-based fashion, under both fully observable and partially observable settings. The proposed algorithm modifies the standard posterior sampling algorithm in two aspects: (i) we use an optimistic prior distribution that biases towards hypotheses with higher values and (ii) a loglikelihood function is set to be the empirical loss evaluated on the historical data, where the choice of loss function supports both model-free and model-based learning. We prove that the proposed algorithm is sample efficient by establishing a sublinear regret upper bound in terms of GEC. In summary, we provide a new and unified understanding of both fully observable and partially observable RL.