 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unified Knowledge Embedded Reinforcement Learning-based Framework for Generalized Capacitated Vehicle Routing Problems
May 14, 2026The Capacitated Vehicle Routing Problem (CVRP) is a fundamental NP-hard problem with broad applications in logistics and transportation. Real-world CVRPs often involve diverse objectives and complex constraints, such as time windows or backhaul requirements, motivating the development of a unified solution framework. Recent reinforcement learning (RL) approaches have shown promise in combinatorial optimization, yet they rely on end-to-end learning and lack explicit problem-solving knowledge, limiting solution quality. In this paper, we propose a knowledge-embedded framework inspired by the Route-First Cluster-Second heuristics. It incorporates knowledge at two levels: (1) decomposing CVRPs into the route-first and cluster-second subproblems, and (2) leveraging dynamic programming to solve the second subproblem, whose results guide the RL-based constructive solver to solve the first problem. To mitigate partial observability caused by problem decomposition, we introduce a unified history-enhanced context processing module. Extensive experiments show that this framework achieves superior solution quality compared with state-of-the-art learning-based methods, with a smaller gap to classical heuristics, demonstrating strong generalization across diverse CVRP variants.
ObjView-Bench: Rethinking Difficulty and Deployment for Object-Centric View Planning
May 11, 2026Object-centric view planning is a core component of active geometric 3D reconstruction in robotics, yet existing evaluations often conflate object complexity, planning difficulty, budget assumptions, and physical reachability constraints. As a result, conclusions drawn from idealized view-planning evaluations may not reliably predict performance under realistic reconstruction settings. We introduce ObjView-Bench, an evaluation framework for rethinking difficulty and deployment in object-centric view planning. First, we disentangle three quantities underlying view-planning evaluation: omnidirectional self-occlusion as an object-side attribute, observation saturation difficulty, and protocol-dependent planning difficulty defined through a set-cover formulation. This separation supports controlled dataset construction, analysis of slow-saturation objects, and a case study showing that planning difficulty-aware sampling can improve learned view planners. Second, we design deployment-oriented evaluation protocols that reveal how budget regimes and reachable-view constraints alter method behavior. Across classical, learned, and hybrid planners, ObjView-Bench shows that difficulty, budget, and reachability constraints substantially change method rankings and failure modes.
Beyond Accuracy: Evaluating Strategy Diversity in LLM Mathematical Reasoning
May 10, 2026Large language models now achieve high final-answer accuracy on mathematical reasoning benchmarks, but accuracy alone does not capture reasoning flexibility. We introduce a strategy-level evaluation framework instantiated on 80 AMC 10/12 and AIME problems with 217 AoPS-derived reference strategy families. Model outputs are annotated for strategy identity, validity, and correctness using dual-AI coding with human adjudication. Across four frontier models, we find a pronounced decoupling between answer accuracy and strategy diversity. Under a single-solution prompt, all models achieve high accuracy (95%-100%), but under a multiple-strategy prompt they recover substantially fewer strategies than the human reference set. Gemini, DeepSeek, GPT, and Claude generate 184, 152, 151, and 110 distinct valid strategies, respectively, with the largest gaps in Geometry and Number Theory. The models collectively produce 50 benchmark-novel valid strategies, indicating both incomplete coverage of human strategies and some capacity for alternative reasoning. A repeated-run robustness check on 20 problems shows diminishing gains in discovered strategies, with the strongest model recovering only 39 of 55 AoPS-reference strategies (71%) after three runs. These findings position strategy diversity as a complementary dimension for evaluating mathematical reasoning beyond answer correctness.
Towards Secure Retrieval-Augmented Generation: A Comprehensive Review of Threats, Defenses and Benchmarks
Mar 23, 2026Retrieval-Augmented Generation (RAG) significantly mitigates the hallucinations and domain knowledge deficiency in large language models by incorporating external knowledge bases. However, the multi-module architecture of RAG introduces complex system-level security vulnerabilities. Guided by the RAG workflow, this paper analyzes the underlying vulnerability mechanisms and systematically categorizes core threat vectors such as data poisoning, adversarial attacks, and membership inference attacks. Based on this threat assessment, we construct a taxonomy of RAG defense technologies from a dual perspective encompassing both input and output stages. The input-side analysis reviews data protection mechanisms including dynamic access control, homomorphic encryption retrieval, and adversarial pre-filtering. The output-side examination summarizes advanced leakage prevention techniques such as federated learning isolation, differential privacy perturbation, and lightweight data sanitization. To establish a unified benchmark for future experimental design, we consolidate authoritative test datasets, security standards, and evaluation frameworks. To the best of our knowledge, this paper presents the first end-to-end survey dedicated to the security of RAG systems. Distinct from existing literature that isolates specific vulnerabilities, we systematically map the entire pipeline-providing a unified analysis of threat models, defense mechanisms, and evaluation benchmarks. By enabling deep insights into potential risks, this work seeks to foster the development of highly robust and trustworthy next-generation RAG systems.
Ego-1K -- A Large-Scale Multiview Video Dataset for Egocentric Vision
Mar 14, 2026We present Ego-1K, a large-scale collection of time-synchronized egocentric multiview videos designed to advance neural 3D video synthesis and dynamic scene understanding. The dataset contains nearly 1,000 short egocentric videos captured with a custom rig with 12 synchronized cameras surrounding a 4-camera VR headset worn by the user. Scene content focuses on hand motions and hand-object interactions in different settings. We describe rig design, data processing, and calibration. Our dataset enables new ways to benchmark egocentric scene reconstruction methods, an important research area as smart glasses with multiple cameras become omnipresent. Our experiments demonstrate that our dataset presents unique challenges for existing 3D and 4D novel view synthesis methods due to large disparities and image motion caused by close dynamic objects and rig egomotion. Our dataset supports future research in this challenging domain. It is available at https://huggingface.co/datasets/facebook/ego-1k.
GlobeDiff: State Diffusion Process for Partial Observability in Multi-Agent Systems
Feb 17, 2026In the realm of multi-agent systems, the challenge of \emph{partial observability} is a critical barrier to effective coordination and decision-making. Existing approaches, such as belief state estimation and inter-agent communication, often fall short. Belief-based methods are limited by their focus on past experiences without fully leveraging global information, while communication methods often lack a robust model to effectively utilize the auxiliary information they provide. To solve this issue, we propose Global State Diffusion Algorithm~(GlobeDiff) to infer the global state based on the local observations. By formulating the state inference process as a multi-modal diffusion process, GlobeDiff overcomes ambiguities in state estimation while simultaneously inferring the global state with high fidelity. We prove that the estimation error of GlobeDiff under both unimodal and multi-modal distributions can be bounded. Extensive experimental results demonstrate that GlobeDiff achieves superior performance and is capable of accurately inferring the global state.
IGMiRAG: Intuition-Guided Retrieval-Augmented Generation with Adaptive Mining of In-Depth Memory
Feb 07, 2026Retrieval-augmented generation (RAG) equips large language models (LLMs) with reliable knowledge memory. To strengthen cross-text associations, recent research integrates graphs and hypergraphs into RAG to capture pairwise and multi-entity relations as structured links. However, their misaligned memory organization necessitates costly, disjointed retrieval. To address these limitations, we propose IGMiRAG, a framework inspired by human intuition-guided reasoning. It constructs a hierarchical heterogeneous hypergraph to align multi-granular knowledge, incorporating deductive pathways to simulate realistic memory structures. During querying, IGMiRAG distills intuitive strategies via a question parser to control mining depth and memory window, and activates instantaneous memories as anchors using dual-focus retrieval. Mirroring human intuition, the framework guides retrieval resource allocation dynamically. Furthermore, we design a bidirectional diffusion algorithm that navigates deductive paths to mine in-depth memories, emulating human reasoning processes. Extensive evaluations indicate IGMiRAG outperforms the state-of-the-art baseline by 4.8% EM and 5.0% F1 overall, with token costs adapting to task complexity (average 6.3k+, minimum 3.0k+). This work presents a cost-effective RAG paradigm that improves both efficiency and effectiveness.
Kimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
Enhancing Cloud Network Resilience via a Robust LLM-Empowered Multi-Agent Reinforcement Learning Framework
Jan 12, 2026While virtualization and resource pooling empower cloud networks with structural flexibility and elastic scalability, they inevitably expand the attack surface and challenge cyber resilience. Reinforcement Learning (RL)-based defense strategies have been developed to optimize resource deployment and isolation policies under adversarial conditions, aiming to enhance system resilience by maintaining and restoring network availability. However, existing approaches lack robustness as they require retraining to adapt to dynamic changes in network structure, node scale, attack strategies, and attack intensity. Furthermore, the lack of Human-in-the-Loop (HITL) support limits interpretability and flexibility. To address these limitations, we propose CyberOps-Bots, a hierarchical multi-agent reinforcement learning framework empowered by Large Language Models (LLMs). Inspired by MITRE ATT&CK's Tactics-Techniques model, CyberOps-Bots features a two-layer architecture: (1) An upper-level LLM agent with four modules--ReAct planning, IPDRR-based perception, long-short term memory, and action/tool integration--performs global awareness, human intent recognition, and tactical planning; (2) Lower-level RL agents, developed via heterogeneous separated pre-training, execute atomic defense actions within localized network regions. This synergy preserves LLM adaptability and interpretability while ensuring reliable RL execution. Experiments on real cloud datasets show that, compared to state-of-the-art algorithms, CyberOps-Bots maintains network availability 68.5% higher and achieves a 34.7% jumpstart performance gain when shifting the scenarios without retraining. To our knowledge, this is the first study to establish a robust LLM-RL framework with HITL support for cloud defense. We will release our framework to the community, facilitating the advancement of robust and autonomous defense in cloud networks.
ORPR: An OR-Guided Pretrain-then-Reinforce Learning Model for Inventory Management
Dec 22, 2025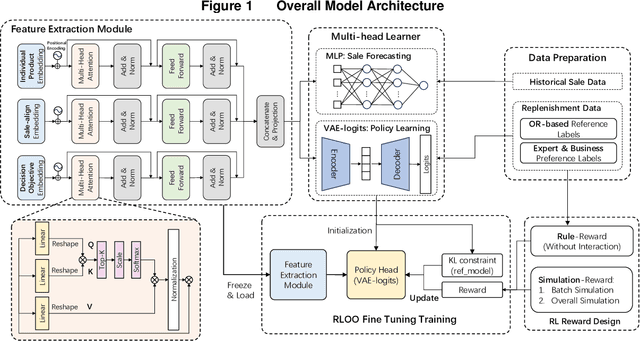
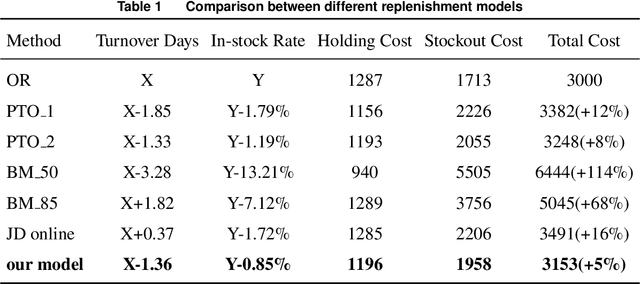
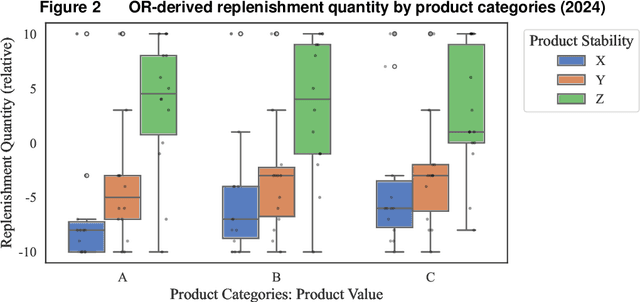
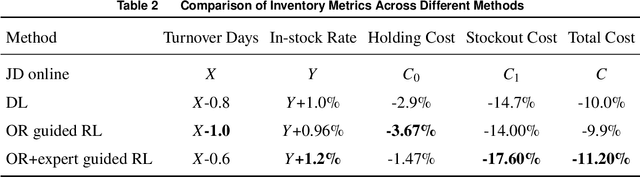
As the pursuit of synergy between Artificial Intelligence (AI) and Operations Research (OR) gains momentum in handling complex inventory systems, a critical challenge persists: how to effectively reconcile AI's adaptive perception with OR's structural rigor. To bridge this gap, we propose a novel OR-Guided "Pretrain-then-Reinforce" framework. To provide structured guidance, we propose a simulation-augmented OR model that generates high-quality reference decisions, implicitly capturing complex business constraints and managerial preferences. Leveraging these OR-derived decisions as foundational training labels, we design a domain-informed deep learning foundation model to establish foundational decision-making capabilities, followed by a reinforcement learning (RL) fine-tuning stage. Uniquely, we position RL as a deep alignment mechanism that enables the AI agent to internalize the optimality principles of OR, while simultaneously leveraging exploration for general policy refinement and allowing expert guidance for scenario-specific adaptation (e.g., promotional events). Validated through extensive numerical experiments and a field deployment at JD.com augmented by a Difference-in-Differences (DiD) analysis, our model significantly outperforms incumbent industrial practices, delivering real-world gains of a 5.27-day reduction in turnover and a 2.29% increase in in-stock rates, alongside a 29.95% decrease in holding costs. Contrary to the prevailing trend of brute-force model scaling, our study demonstrates that a lightweight, domain-informed model can deliver state-of-the-art performance and robust transferability when guided by structured OR logic. This approach offers a scalable and cost-effective paradigm for intelligent supply chain management, highlighting the value of deeply aligning AI with OR.