 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeORPR: An OR-Guided Pretrain-then-Reinforce Learning Model for Inventory Management
Dec 22, 2025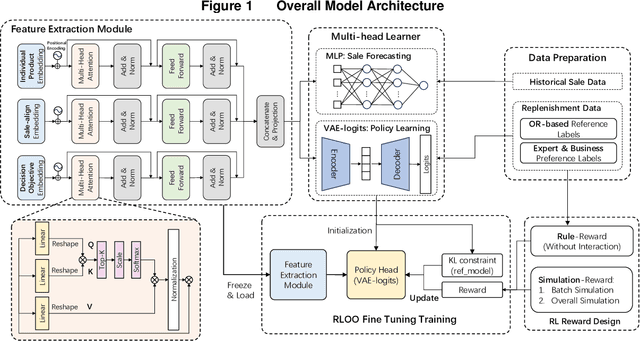
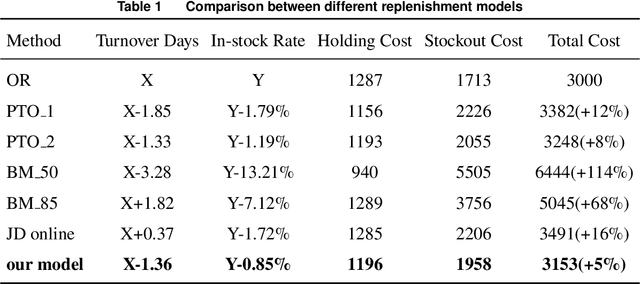
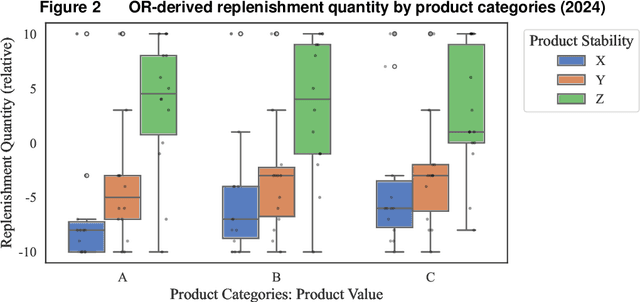
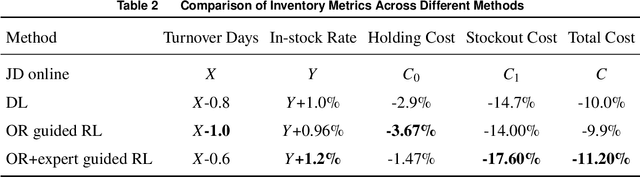
As the pursuit of synergy between Artificial Intelligence (AI) and Operations Research (OR) gains momentum in handling complex inventory systems, a critical challenge persists: how to effectively reconcile AI's adaptive perception with OR's structural rigor. To bridge this gap, we propose a novel OR-Guided "Pretrain-then-Reinforce" framework. To provide structured guidance, we propose a simulation-augmented OR model that generates high-quality reference decisions, implicitly capturing complex business constraints and managerial preferences. Leveraging these OR-derived decisions as foundational training labels, we design a domain-informed deep learning foundation model to establish foundational decision-making capabilities, followed by a reinforcement learning (RL) fine-tuning stage. Uniquely, we position RL as a deep alignment mechanism that enables the AI agent to internalize the optimality principles of OR, while simultaneously leveraging exploration for general policy refinement and allowing expert guidance for scenario-specific adaptation (e.g., promotional events). Validated through extensive numerical experiments and a field deployment at JD.com augmented by a Difference-in-Differences (DiD) analysis, our model significantly outperforms incumbent industrial practices, delivering real-world gains of a 5.27-day reduction in turnover and a 2.29% increase in in-stock rates, alongside a 29.95% decrease in holding costs. Contrary to the prevailing trend of brute-force model scaling, our study demonstrates that a lightweight, domain-informed model can deliver state-of-the-art performance and robust transferability when guided by structured OR logic. This approach offers a scalable and cost-effective paradigm for intelligent supply chain management, highlighting the value of deeply aligning AI with OR.
Leveraging LLM-Based Agents for Intelligent Supply Chain Planning
Sep 04, 2025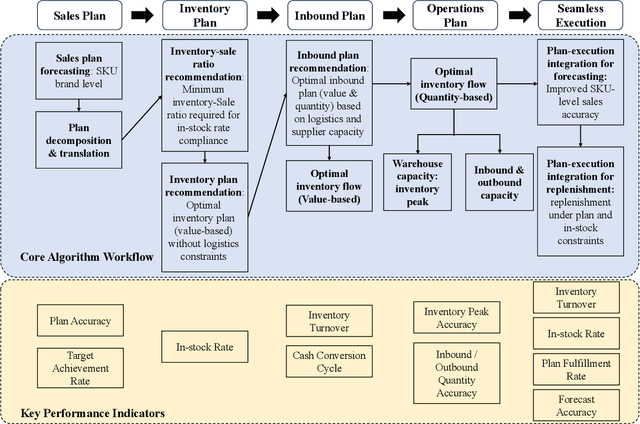
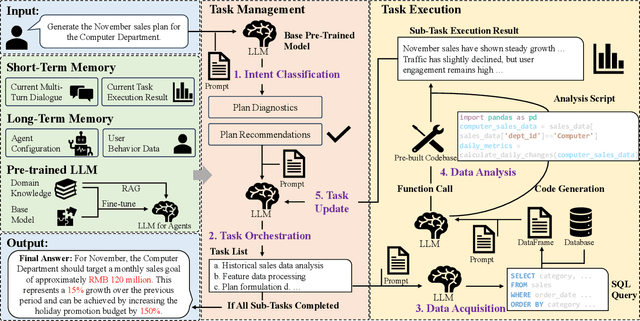
In supply chain management, planning is a critical concept. The movement of physical products across different categories, from suppliers to warehouse management, to sales, and logistics transporting them to customers, entails the involvement of many entities. It covers various aspects such as demand forecasting, inventory management, sales operations, and replenishment. How to collect relevant data from an e-commerce platform's perspective, formulate long-term plans, and dynamically adjust them based on environmental changes, while ensuring interpretability, efficiency, and reliability, is a practical and challenging problem. In recent years, the development of AI technologies, especially the rapid progress of large language models, has provided new tools to address real-world issues. In this work, we construct a Supply Chain Planning Agent (SCPA) framework that can understand domain knowledge, comprehend the operator's needs, decompose tasks, leverage or create new tools, and return evidence-based planning reports. We deploy this framework in JD.com's real-world scenario, demonstrating the feasibility of LLM-agent applications in the supply chain. It effectively reduced labor and improved accuracy, stock availability, and other key metrics.
TimeHF: Billion-Scale Time Series Models Guided by Human Feedback
Jan 27, 2025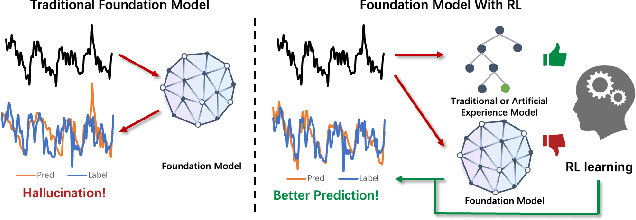
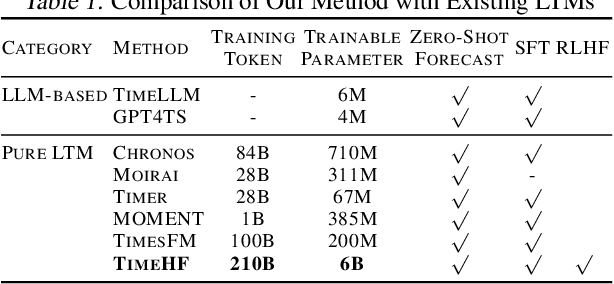

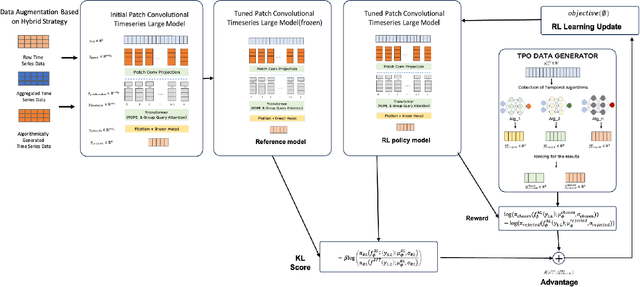
Time series neural networks perform exceptionally well in real-world applications but encounter challenges such as limited scalability, poor generalization, and suboptimal zero-shot performance. Inspired by large language models, there is interest in developing large time series models (LTM) to address these issues. However, current methods struggle with training complexity, adapting human feedback, and achieving high predictive accuracy. We introduce TimeHF, a novel pipeline for creating LTMs with 6 billion parameters, incorporating human feedback. We use patch convolutional embedding to capture long time series information and design a human feedback mechanism called time-series policy optimization. Deployed in JD.com's supply chain, TimeHF handles automated replenishment for over 20,000 products, improving prediction accuracy by 33.21% over existing methods. This work advances LTM technology and shows significant industrial benefits.
sTransformer: A Modular Approach for Extracting Inter-Sequential and Temporal Information for Time-Series Forecasting
Aug 19, 2024In recent years, numerous Transformer-based models have been applied to long-term time-series forecasting (LTSF) tasks. However, recent studies with linear models have questioned their effectiveness, demonstrating that simple linear layers can outperform sophisticated Transformer-based models. In this work, we review and categorize existing Transformer-based models into two main types: (1) modifications to the model structure and (2) modifications to the input data. The former offers scalability but falls short in capturing inter-sequential information, while the latter preprocesses time-series data but is challenging to use as a scalable module. We propose $\textbf{sTransformer}$, which introduces the Sequence and Temporal Convolutional Network (STCN) to fully capture both sequential and temporal information. Additionally, we introduce a Sequence-guided Mask Attention mechanism to capture global feature information. Our approach ensures the capture of inter-sequential information while maintaining module scalability. We compare our model with linear models and existing forecasting models on long-term time-series forecasting, achieving new state-of-the-art results. We also conducted experiments on other time-series tasks, achieving strong performance. These demonstrate that Transformer-based structures remain effective and our model can serve as a viable baseline for time-series tasks.
Improving Accuracy Without Losing Interpretability: A ML Approach for Time Series Forecasting
Dec 13, 2022



In time series forecasting, decomposition-based algorithms break aggregate data into meaningful components and are therefore appreciated for their particular advantages in interpretability. Recent algorithms often combine machine learning (hereafter ML) methodology with decomposition to improve prediction accuracy. However, incorporating ML is generally considered to sacrifice interpretability inevitably. In addition, existing hybrid algorithms usually rely on theoretical models with statistical assumptions and focus only on the accuracy of aggregate predictions, and thus suffer from accuracy problems, especially in component estimates. In response to the above issues, this research explores the possibility of improving accuracy without losing interpretability in time series forecasting. We first quantitatively define interpretability for data-driven forecasts and systematically review the existing forecasting algorithms from the perspective of interpretability. Accordingly, we propose the W-R algorithm, a hybrid algorithm that combines decomposition and ML from a novel perspective. Specifically, the W-R algorithm replaces the standard additive combination function with a weighted variant and uses ML to modify the estimates of all components simultaneously. We mathematically analyze the theoretical basis of the algorithm and validate its performance through extensive numerical experiments. In general, the W-R algorithm outperforms all decomposition-based and ML benchmarks. Based on P50_QL, the algorithm relatively improves by 8.76% in accuracy on the practical sales forecasts of JD.com and 77.99% on a public dataset of electricity loads. This research offers an innovative perspective to combine the statistical and ML algorithms, and JD.com has implemented the W-R algorithm to make accurate sales predictions and guide its marketing activities.