 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging LLM-Based Agents for Intelligent Supply Chain Planning
Sep 04, 2025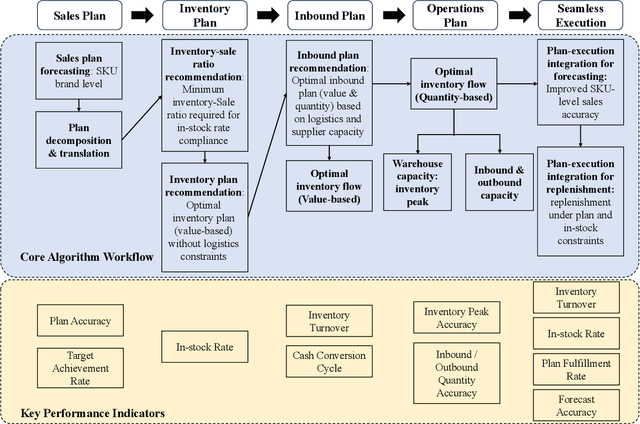
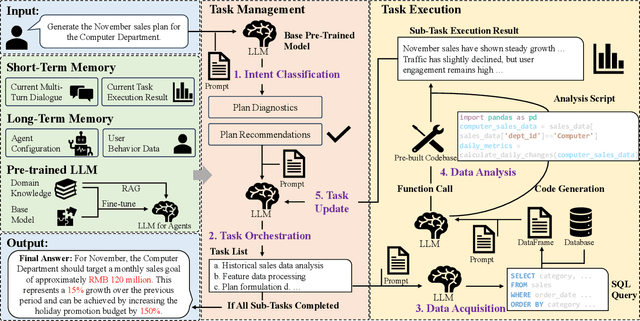
In supply chain management, planning is a critical concept. The movement of physical products across different categories, from suppliers to warehouse management, to sales, and logistics transporting them to customers, entails the involvement of many entities. It covers various aspects such as demand forecasting, inventory management, sales operations, and replenishment. How to collect relevant data from an e-commerce platform's perspective, formulate long-term plans, and dynamically adjust them based on environmental changes, while ensuring interpretability, efficiency, and reliability, is a practical and challenging problem. In recent years, the development of AI technologies, especially the rapid progress of large language models, has provided new tools to address real-world issues. In this work, we construct a Supply Chain Planning Agent (SCPA) framework that can understand domain knowledge, comprehend the operator's needs, decompose tasks, leverage or create new tools, and return evidence-based planning reports. We deploy this framework in JD.com's real-world scenario, demonstrating the feasibility of LLM-agent applications in the supply chain. It effectively reduced labor and improved accuracy, stock availability, and other key metrics.
sTransformer: A Modular Approach for Extracting Inter-Sequential and Temporal Information for Time-Series Forecasting
Aug 19, 2024In recent years, numerous Transformer-based models have been applied to long-term time-series forecasting (LTSF) tasks. However, recent studies with linear models have questioned their effectiveness, demonstrating that simple linear layers can outperform sophisticated Transformer-based models. In this work, we review and categorize existing Transformer-based models into two main types: (1) modifications to the model structure and (2) modifications to the input data. The former offers scalability but falls short in capturing inter-sequential information, while the latter preprocesses time-series data but is challenging to use as a scalable module. We propose $\textbf{sTransformer}$, which introduces the Sequence and Temporal Convolutional Network (STCN) to fully capture both sequential and temporal information. Additionally, we introduce a Sequence-guided Mask Attention mechanism to capture global feature information. Our approach ensures the capture of inter-sequential information while maintaining module scalability. We compare our model with linear models and existing forecasting models on long-term time-series forecasting, achieving new state-of-the-art results. We also conducted experiments on other time-series tasks, achieving strong performance. These demonstrate that Transformer-based structures remain effective and our model can serve as a viable baseline for time-series tasks.