 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
Kimi K2: Open Agentic Intelligence
Jul 28, 2025



We introduce Kimi K2, a Mixture-of-Experts (MoE) large language model with 32 billion activated parameters and 1 trillion total parameters. We propose the MuonClip optimizer, which improves upon Muon with a novel QK-clip technique to address training instability while enjoying the advanced token efficiency of Muon. Based on MuonClip, K2 was pre-trained on 15.5 trillion tokens with zero loss spike. During post-training, K2 undergoes a multi-stage post-training process, highlighted by a large-scale agentic data synthesis pipeline and a joint reinforcement learning (RL) stage, where the model improves its capabilities through interactions with real and synthetic environments. Kimi K2 achieves state-of-the-art performance among open-source non-thinking models, with strengths in agentic capabilities. Notably, K2 obtains 66.1 on Tau2-Bench, 76.5 on ACEBench (En), 65.8 on SWE-Bench Verified, and 47.3 on SWE-Bench Multilingual -- surpassing most open and closed-sourced baselines in non-thinking settings. It also exhibits strong capabilities in coding, mathematics, and reasoning tasks, with a score of 53.7 on LiveCodeBench v6, 49.5 on AIME 2025, 75.1 on GPQA-Diamond, and 27.1 on OJBench, all without extended thinking. These results position Kimi K2 as one of the most capable open-source large language models to date, particularly in software engineering and agentic tasks. We release our base and post-trained model checkpoints to facilitate future research and applications of agentic intelligence.
Kimi-VL Technical Report
Apr 10, 2025



We present Kimi-VL, an efficient open-source Mixture-of-Experts (MoE) vision-language model (VLM) that offers advanced multimodal reasoning, long-context understanding, and strong agent capabilities - all while activating only 2.8B parameters in its language decoder (Kimi-VL-A3B). Kimi-VL demonstrates strong performance across challenging domains: as a general-purpose VLM, Kimi-VL excels in multi-turn agent tasks (e.g., OSWorld), matching flagship models. Furthermore, it exhibits remarkable capabilities across diverse challenging vision language tasks, including college-level image and video comprehension, OCR, mathematical reasoning, and multi-image understanding. In comparative evaluations, it effectively competes with cutting-edge efficient VLMs such as GPT-4o-mini, Qwen2.5-VL-7B, and Gemma-3-12B-IT, while surpassing GPT-4o in several key domains. Kimi-VL also advances in processing long contexts and perceiving clearly. With a 128K extended context window, Kimi-VL can process diverse long inputs, achieving impressive scores of 64.5 on LongVideoBench and 35.1 on MMLongBench-Doc. Its native-resolution vision encoder, MoonViT, further allows it to see and understand ultra-high-resolution visual inputs, achieving 83.2 on InfoVQA and 34.5 on ScreenSpot-Pro, while maintaining lower computational cost for common tasks. Building upon Kimi-VL, we introduce an advanced long-thinking variant: Kimi-VL-Thinking. Developed through long chain-of-thought (CoT) supervised fine-tuning (SFT) and reinforcement learning (RL), this model exhibits strong long-horizon reasoning capabilities. It achieves scores of 61.7 on MMMU, 36.8 on MathVision, and 71.3 on MathVista while maintaining the compact 2.8B activated LLM parameters, setting a new standard for efficient multimodal thinking models. Code and models are publicly accessible at https://github.com/MoonshotAI/Kimi-VL.
What Makes for Robust Multi-Modal Models in the Face of Missing Modalities?
Oct 10, 2023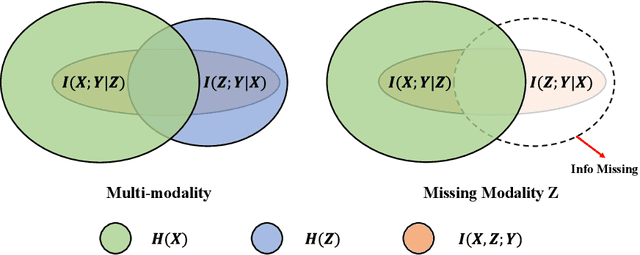
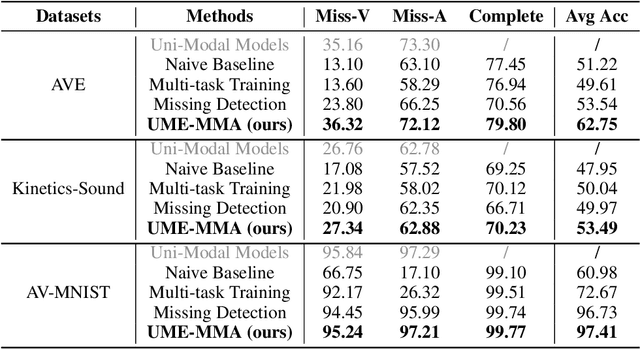
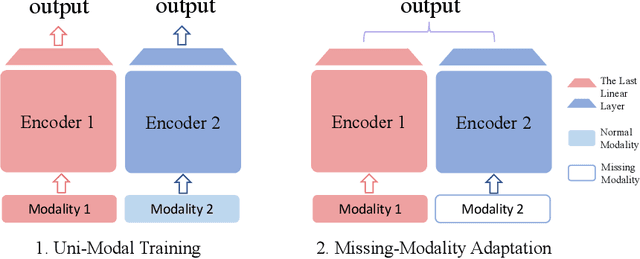
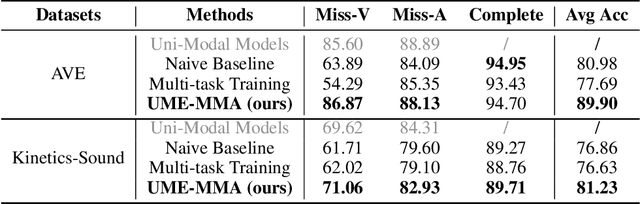
With the growing success of multi-modal learning, research on the robustness of multi-modal models, especially when facing situations with missing modalities, is receiving increased attention. Nevertheless, previous studies in this domain exhibit certain limitations, as they often lack theoretical insights or their methodologies are tied to specific network architectures or modalities. We model the scenarios of multi-modal models encountering missing modalities from an information-theoretic perspective and illustrate that the performance ceiling in such scenarios can be approached by efficiently utilizing the information inherent in non-missing modalities. In practice, there are two key aspects: (1) The encoder should be able to extract sufficiently good features from the non-missing modality; (2) The extracted features should be robust enough not to be influenced by noise during the fusion process across modalities. To this end, we introduce Uni-Modal Ensemble with Missing Modality Adaptation (UME-MMA). UME-MMA employs uni-modal pre-trained weights for the multi-modal model to enhance feature extraction and utilizes missing modality data augmentation techniques to better adapt to situations with missing modalities. Apart from that, UME-MMA, built on a late-fusion learning framework, allows for the plug-and-play use of various encoders, making it suitable for a wide range of modalities and enabling seamless integration of large-scale pre-trained encoders to further enhance performance. And we demonstrate UME-MMA's effectiveness in audio-visual datasets~(e.g., AV-MNIST, Kinetics-Sound, AVE) and vision-language datasets~(e.g., MM-IMDB, UPMC Food101).
Improving Discriminative Multi-Modal Learning with Large-Scale Pre-Trained Models
Oct 08, 2023



This paper investigates how to better leverage large-scale pre-trained uni-modal models to further enhance discriminative multi-modal learning. Even when fine-tuned with only uni-modal data, these models can outperform previous multi-modal models in certain tasks. It's clear that their incorporation into multi-modal learning would significantly improve performance. However, multi-modal learning with these models still suffers from insufficient learning of uni-modal features, which weakens the resulting multi-modal model's generalization ability. While fine-tuning uni-modal models separately and then aggregating their predictions is straightforward, it doesn't allow for adequate adaptation between modalities, also leading to sub-optimal results. To this end, we introduce Multi-Modal Low-Rank Adaptation learning (MMLoRA). By freezing the weights of uni-modal fine-tuned models, adding extra trainable rank decomposition matrices to them, and subsequently performing multi-modal joint training, our method enhances adaptation between modalities and boosts overall performance. We demonstrate the effectiveness of MMLoRA on three dataset categories: audio-visual (e.g., AVE, Kinetics-Sound, CREMA-D), vision-language (e.g., MM-IMDB, UPMC Food101), and RGB-Optical Flow (UCF101).
ChatDB: Augmenting LLMs with Databases as Their Symbolic Memory
Jun 07, 2023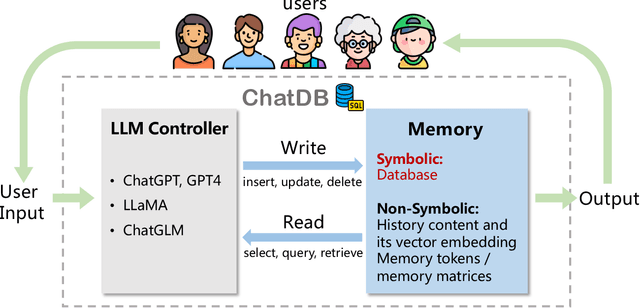

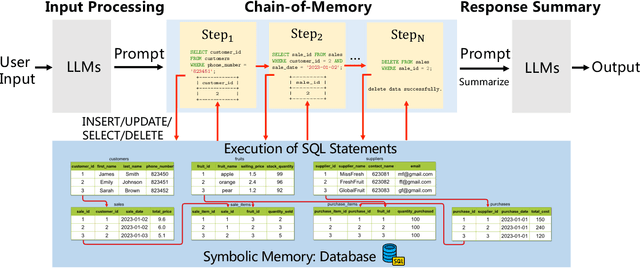
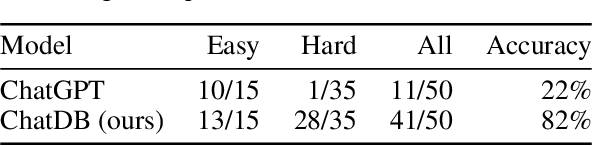
Large language models (LLMs) with memory are computationally universal. However, mainstream LLMs are not taking full advantage of memory, and the designs are heavily influenced by biological brains. Due to their approximate nature and proneness to the accumulation of errors, conventional neural memory mechanisms cannot support LLMs to simulate complex reasoning. In this paper, we seek inspiration from modern computer architectures to augment LLMs with symbolic memory for complex multi-hop reasoning. Such a symbolic memory framework is instantiated as an LLM and a set of SQL databases, where the LLM generates SQL instructions to manipulate the SQL databases. We validate the effectiveness of the proposed memory framework on a synthetic dataset requiring complex reasoning. The project website is available at https://chatdatabase.github.io/ .
On Uni-Modal Feature Learning in Supervised Multi-Modal Learning
May 03, 2023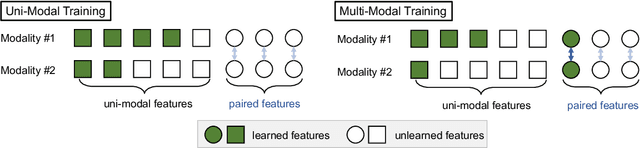
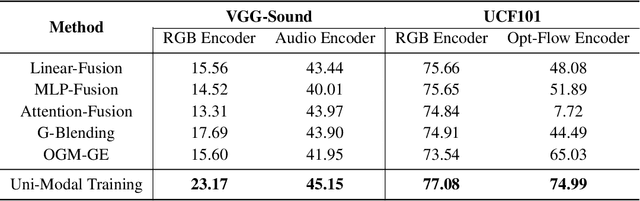
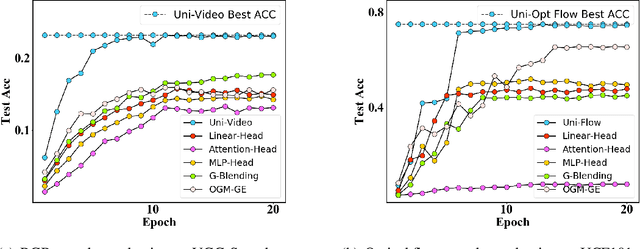
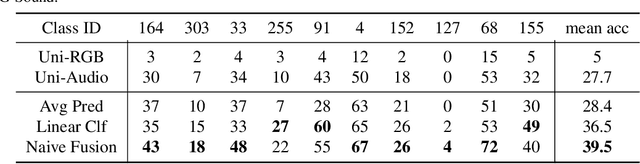
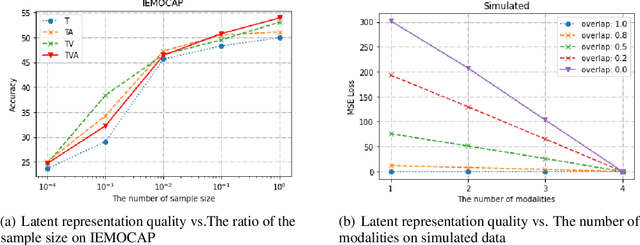
We abstract the features (i.e. learned representations) of multi-modal data into 1) uni-modal features, which can be learned from uni-modal training, and 2) paired features, which can only be learned from cross-modal interactions. Multi-modal models are expected to benefit from cross-modal interactions on the basis of ensuring uni-modal feature learning. However, recent supervised multi-modal late-fusion training approaches still suffer from insufficient learning of uni-modal features on each modality. We prove that this phenomenon does hurt the model's generalization ability. To this end, we propose to choose a targeted late-fusion learning method for the given supervised multi-modal task from Uni-Modal Ensemble(UME) and the proposed Uni-Modal Teacher(UMT), according to the distribution of uni-modal and paired features. We demonstrate that, under a simple guiding strategy, we can achieve comparable results to other complex late-fusion or intermediate-fusion methods on various multi-modal datasets, including VGG-Sound, Kinetics-400, UCF101, and ModelNet40.
Intrinsically Motivated Self-supervised Learning in Reinforcement Learning
Jun 26, 2021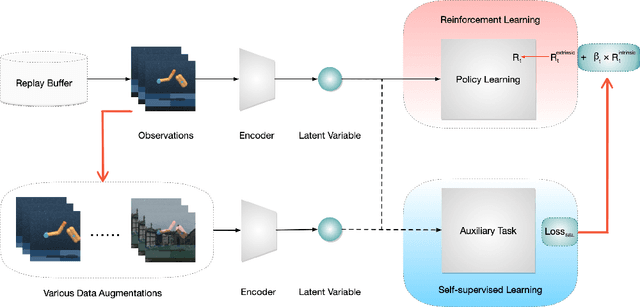
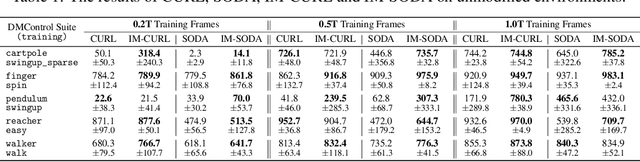
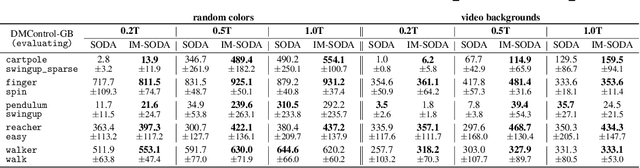

In vision-based reinforcement learning (RL) tasks, it is prevalent to assign the auxiliary task with a surrogate self-supervised loss so as to obtain more semantic representations and improve sample efficiency. However, abundant information in self-supervised auxiliary tasks has been disregarded, since the representation learning part and the decision-making part are separated. To sufficiently utilize information in the auxiliary task, we present a simple yet effective idea to employ self-supervised loss as an intrinsic reward, called Intrinsically Motivated Self-Supervised learning in Reinforcement learning (IM-SSR). We formally show that the self-supervised loss can be decomposed as exploration for novel states and robustness improvement from nuisance elimination. IM-SSR can be effortlessly plugged into any reinforcement learning with self-supervised auxiliary objectives with nearly no additional cost. Combined with IM-SSR, the previous underlying algorithms achieve salient improvements on both sample efficiency and generalization in various vision-based robotics tasks from the DeepMind Control Suite, especially when the reward signal is sparse.
Improving Multi-Modal Learning with Uni-Modal Teachers
Jun 21, 2021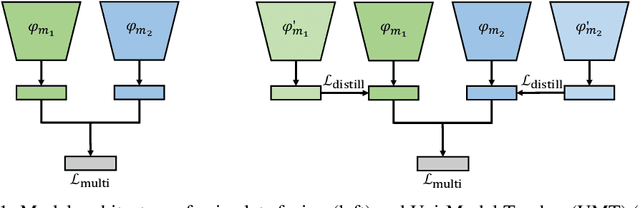
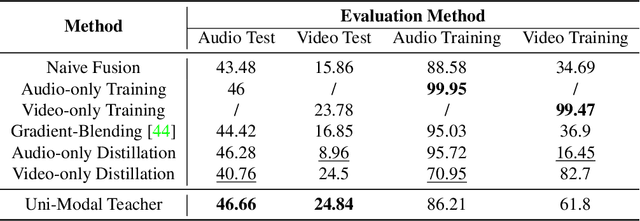
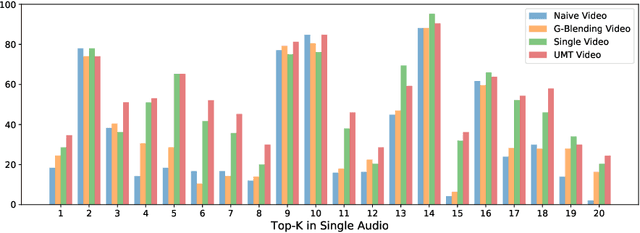

Learning multi-modal representations is an essential step towards real-world robotic applications, and various multi-modal fusion models have been developed for this purpose. However, we observe that existing models, whose objectives are mostly based on joint training, often suffer from learning inferior representations of each modality. We name this problem Modality Failure, and hypothesize that the imbalance of modalities and the implicit bias of common objectives in fusion method prevent encoders of each modality from sufficient feature learning. To this end, we propose a new multi-modal learning method, Uni-Modal Teacher, which combines the fusion objective and uni-modal distillation to tackle the modality failure problem. We show that our method not only drastically improves the representation of each modality, but also improves the overall multi-modal task performance. Our method can be effectively generalized to most multi-modal fusion approaches. We achieve more than 3% improvement on the VGGSound audio-visual classification task, as well as improving performance on the NYU depth V2 RGB-D image segmentation task.
What Makes Multimodal Learning Better than Single (Provably)
Jun 08, 2021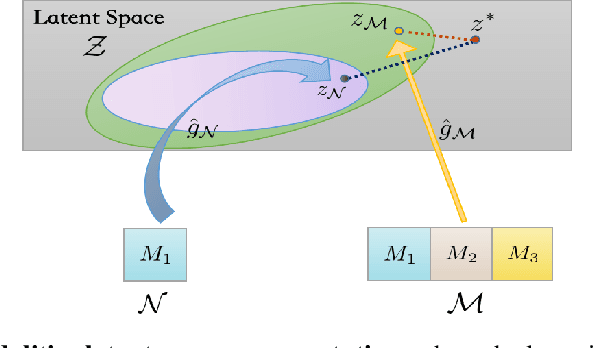


The world provides us with data of multiple modalities. Intuitively, models fusingdata from different modalities outperform unimodal models, since more informationis aggregated. Recently, joining the success of deep learning, there is an influentialline of work on deep multimodal learning, which has remarkable empirical resultson various applications. However, theoretical justifications in this field are notablylacking.Can multimodal provably perform better than unimodal? In this paper, we answer this question under a most popular multimodal learningframework, which firstly encodes features from different modalities into a commonlatent space and seamlessly maps the latent representations into the task space. Weprove that learning with multiple modalities achieves a smaller population risk thanonly using its subset of modalities. The main intuition is that the former has moreaccurate estimate of the latent space representation. To the best of our knowledge,this is the first theoretical treatment to capture important qualitative phenomenaobserved in real multimodal applications. Combining with experiment results, weshow that multimodal learning does possess an appealing formal guarantee.