 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparseViT: Revisiting Activation Sparsity for Efficient High-Resolution Vision Transformer
Mar 30, 2023



High-resolution images enable neural networks to learn richer visual representations. However, this improved performance comes at the cost of growing computational complexity, hindering their usage in latency-sensitive applications. As not all pixels are equal, skipping computations for less-important regions offers a simple and effective measure to reduce the computation. This, however, is hard to be translated into actual speedup for CNNs since it breaks the regularity of the dense convolution workload. In this paper, we introduce SparseViT that revisits activation sparsity for recent window-based vision transformers (ViTs). As window attentions are naturally batched over blocks, actual speedup with window activation pruning becomes possible: i.e., ~50% latency reduction with 60% sparsity. Different layers should be assigned with different pruning ratios due to their diverse sensitivities and computational costs. We introduce sparsity-aware adaptation and apply the evolutionary search to efficiently find the optimal layerwise sparsity configuration within the vast search space. SparseViT achieves speedups of 1.5x, 1.4x, and 1.3x compared to its dense counterpart in monocular 3D object detection, 2D instance segmentation, and 2D semantic segmentation, respectively, with negligible to no loss of accuracy.
ViP3D: End-to-end Visual Trajectory Prediction via 3D Agent Queries
Aug 02, 2022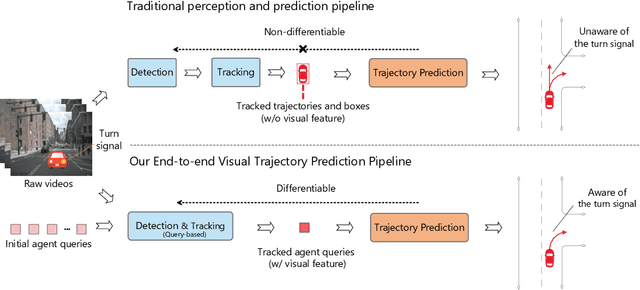
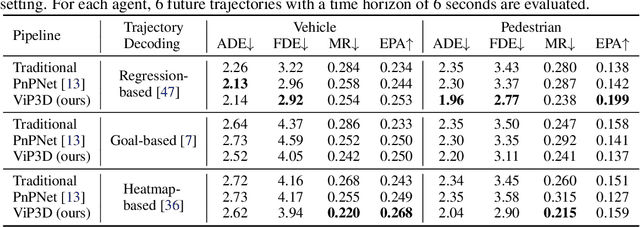
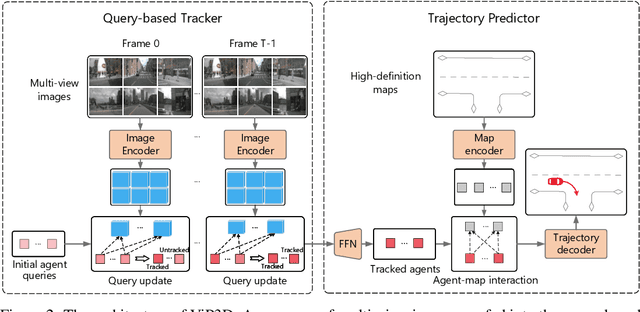
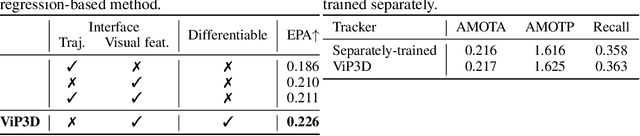
Existing autonomous driving pipelines separate the perception module from the prediction module. The two modules communicate via hand-picked features such as agent boxes and trajectories as interfaces. Due to this separation, the prediction module only receives partial information from the perception module. Even worse, errors from the perception modules can propagate and accumulate, adversely affecting the prediction results. In this work, we propose ViP3D, a visual trajectory prediction pipeline that leverages the rich information from raw videos to predict future trajectories of agents in a scene. ViP3D employs sparse agent queries throughout the pipeline, making it fully differentiable and interpretable. Furthermore, we propose an evaluation metric for this novel end-to-end visual trajectory prediction task. Extensive experimental results on the nuScenes dataset show the strong performance of ViP3D over traditional pipelines and previous end-to-end models.
MUTR3D: A Multi-camera Tracking Framework via 3D-to-2D Queries
May 02, 2022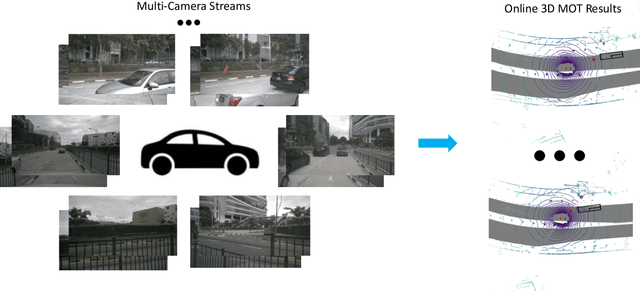
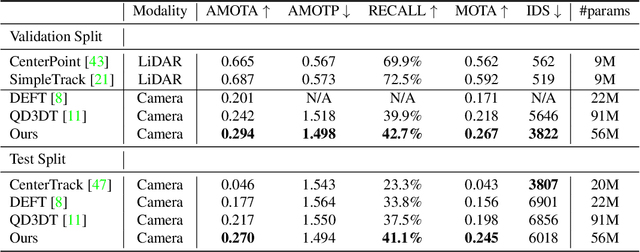
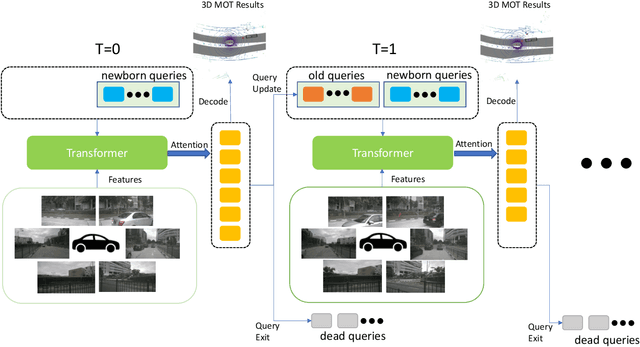

Accurate and consistent 3D tracking from multiple cameras is a key component in a vision-based autonomous driving system. It involves modeling 3D dynamic objects in complex scenes across multiple cameras. This problem is inherently challenging due to depth estimation, visual occlusions, appearance ambiguity, etc. Moreover, objects are not consistently associated across time and cameras. To address that, we propose an end-to-end \textbf{MU}lti-camera \textbf{TR}acking framework called MUTR3D. In contrast to prior works, MUTR3D does not explicitly rely on the spatial and appearance similarity of objects. Instead, our method introduces \textit{3D track query} to model spatial and appearance coherent track for each object that appears in multiple cameras and multiple frames. We use camera transformations to link 3D trackers with their observations in 2D images. Each tracker is further refined according to the features that are obtained from camera images. MUTR3D uses a set-to-set loss to measure the difference between the predicted tracking results and the ground truths. Therefore, it does not require any post-processing such as non-maximum suppression and/or bounding box association. MUTR3D outperforms state-of-the-art methods by 5.3 AMOTA on the nuScenes dataset. Code is available at: \url{https://github.com/a1600012888/MUTR3D}.
FUTR3D: A Unified Sensor Fusion Framework for 3D Detection
Mar 20, 2022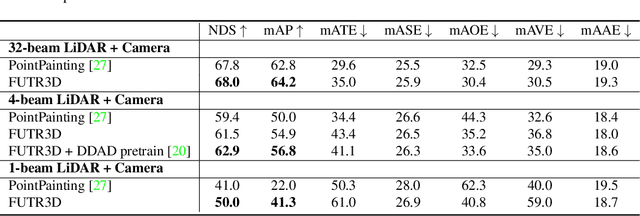
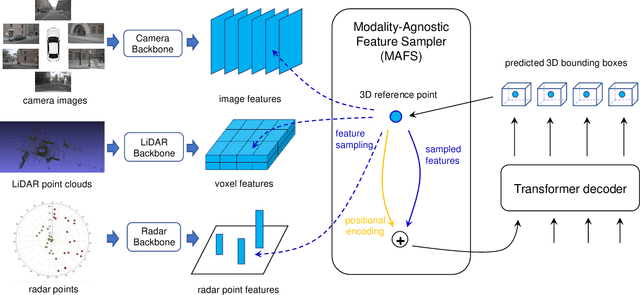

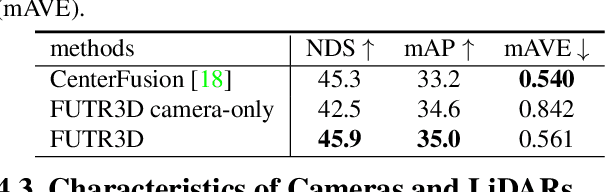
Sensor fusion is an essential topic in many perception systems, such as autonomous driving and robotics. Existing multi-modal 3D detection models usually involve customized designs depending on the sensor combinations or setups. In this work, we propose the first unified end-to-end sensor fusion framework for 3D detection, named FUTR3D, which can be used in (almost) any sensor configuration. FUTR3D employs a query-based Modality-Agnostic Feature Sampler (MAFS), together with a transformer decoder with a set-to-set loss for 3D detection, thus avoiding using late fusion heuristics and post-processing tricks. We validate the effectiveness of our framework on various combinations of cameras, low-resolution LiDARs, high-resolution LiDARs, and Radars. On NuScenes dataset, FUTR3D achieves better performance over specifically designed methods across different sensor combinations. Moreover, FUTR3D achieves great flexibility with different sensor configurations and enables low-cost autonomous driving. For example, only using a 4-beam LiDAR with cameras, FUTR3D (56.8 mAP) achieves on par performance with state-of-the-art 3D detection model CenterPoint (56.6 mAP) using a 32-beam LiDAR.
What Makes Multimodal Learning Better than Single (Provably)
Jun 08, 2021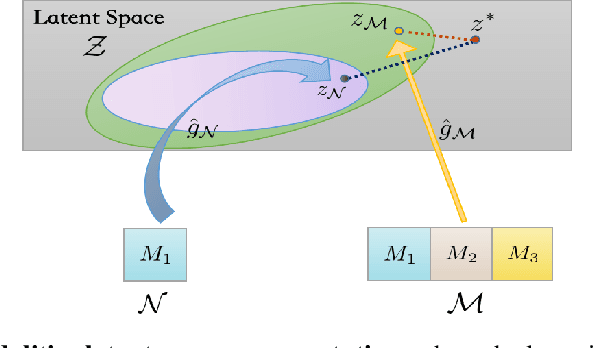


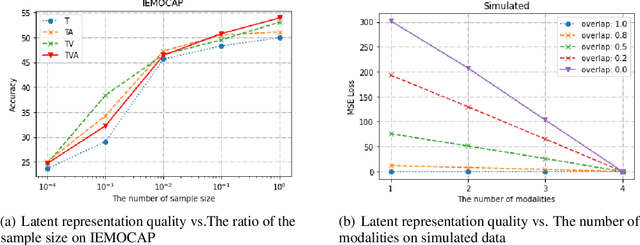
The world provides us with data of multiple modalities. Intuitively, models fusingdata from different modalities outperform unimodal models, since more informationis aggregated. Recently, joining the success of deep learning, there is an influentialline of work on deep multimodal learning, which has remarkable empirical resultson various applications. However, theoretical justifications in this field are notablylacking.Can multimodal provably perform better than unimodal? In this paper, we answer this question under a most popular multimodal learningframework, which firstly encodes features from different modalities into a commonlatent space and seamlessly maps the latent representations into the task space. Weprove that learning with multiple modalities achieves a smaller population risk thanonly using its subset of modalities. The main intuition is that the former has moreaccurate estimate of the latent space representation. To the best of our knowledge,this is the first theoretical treatment to capture important qualitative phenomenaobserved in real multimodal applications. Combining with experiment results, weshow that multimodal learning does possess an appealing formal guarantee.