 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMUTR3D: A Multi-camera Tracking Framework via 3D-to-2D Queries
Paper and Code
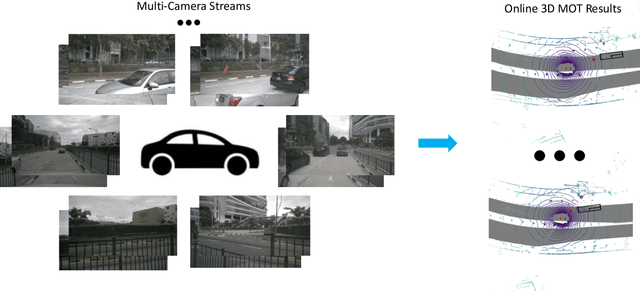
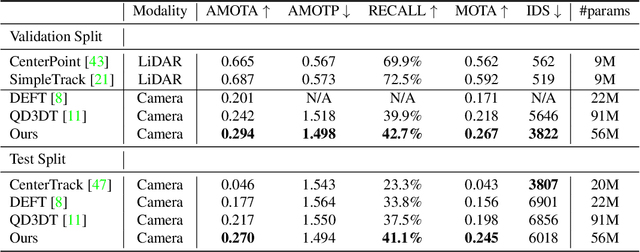
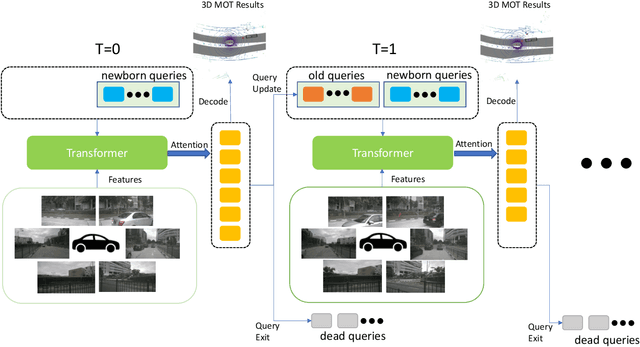

Accurate and consistent 3D tracking from multiple cameras is a key component in a vision-based autonomous driving system. It involves modeling 3D dynamic objects in complex scenes across multiple cameras. This problem is inherently challenging due to depth estimation, visual occlusions, appearance ambiguity, etc. Moreover, objects are not consistently associated across time and cameras. To address that, we propose an end-to-end \textbf{MU}lti-camera \textbf{TR}acking framework called MUTR3D. In contrast to prior works, MUTR3D does not explicitly rely on the spatial and appearance similarity of objects. Instead, our method introduces \textit{3D track query} to model spatial and appearance coherent track for each object that appears in multiple cameras and multiple frames. We use camera transformations to link 3D trackers with their observations in 2D images. Each tracker is further refined according to the features that are obtained from camera images. MUTR3D uses a set-to-set loss to measure the difference between the predicted tracking results and the ground truths. Therefore, it does not require any post-processing such as non-maximum suppression and/or bounding box association. MUTR3D outperforms state-of-the-art methods by 5.3 AMOTA on the nuScenes dataset. Code is available at: \url{https://github.com/a1600012888/MUTR3D}.