 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy Does the LLM Stop Computing: An Empirical Study of User-Reported Failures in Open-Source LLMs
Jan 20, 2026The democratization of open-source Large Language Models (LLMs) allows users to fine-tune and deploy models on local infrastructure but exposes them to a First Mile deployment landscape. Unlike black-box API consumption, the reliability of user-managed orchestration remains a critical blind spot. To bridge this gap, we conduct the first large-scale empirical study of 705 real-world failures from the open-source DeepSeek, Llama, and Qwen ecosystems. Our analysis reveals a paradigm shift: white-box orchestration relocates the reliability bottleneck from model algorithmic defects to the systemic fragility of the deployment stack. We identify three key phenomena: (1) Diagnostic Divergence: runtime crashes distinctively signal infrastructure friction, whereas incorrect functionality serves as a signature for internal tokenizer defects. (2) Systemic Homogeneity: Root causes converge across divergent series, confirming reliability barriers are inherent to the shared ecosystem rather than specific architectures. (3) Lifecycle Escalation: Barriers escalate from intrinsic configuration struggles during fine-tuning to compounded environmental incompatibilities during inference. Supported by our publicly available dataset, these insights provide actionable guidance for enhancing the reliability of the LLM landscape.
RVRAE: A Dynamic Factor Model Based on Variational Recurrent Autoencoder for Stock Returns Prediction
Mar 04, 2024
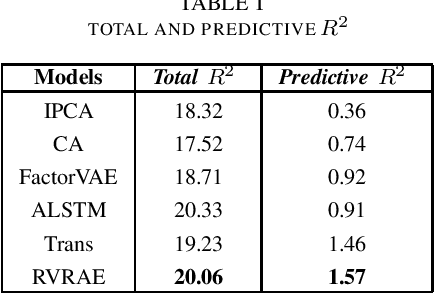


In recent years, the dynamic factor model has emerged as a dominant tool in economics and finance, particularly for investment strategies. This model offers improved handling of complex, nonlinear, and noisy market conditions compared to traditional static factor models. The advancement of machine learning, especially in dealing with nonlinear data, has further enhanced asset pricing methodologies. This paper introduces a groundbreaking dynamic factor model named RVRAE. This model is a probabilistic approach that addresses the temporal dependencies and noise in market data. RVRAE ingeniously combines the principles of dynamic factor modeling with the variational recurrent autoencoder (VRAE) from deep learning. A key feature of RVRAE is its use of a prior-posterior learning method. This method fine-tunes the model's learning process by seeking an optimal posterior factor model informed by future data. Notably, RVRAE is adept at risk modeling in volatile stock markets, estimating variances from latent space distributions while also predicting returns. Our empirical tests with real stock market data underscore RVRAE's superior performance compared to various established baseline methods.
StreamMapNet: Streaming Mapping Network for Vectorized Online HD Map Construction
Aug 27, 2023High-Definition (HD) maps are essential for the safety of autonomous driving systems. While existing techniques employ camera images and onboard sensors to generate vectorized high-precision maps, they are constrained by their reliance on single-frame input. This approach limits their stability and performance in complex scenarios such as occlusions, largely due to the absence of temporal information. Moreover, their performance diminishes when applied to broader perception ranges. In this paper, we present StreamMapNet, a novel online mapping pipeline adept at long-sequence temporal modeling of videos. StreamMapNet employs multi-point attention and temporal information which empowers the construction of large-range local HD maps with high stability and further addresses the limitations of existing methods. Furthermore, we critically examine widely used online HD Map construction benchmark and datasets, Argoverse2 and nuScenes, revealing significant bias in the existing evaluation protocols. We propose to resplit the benchmarks according to geographical spans, promoting fair and precise evaluations. Experimental results validate that StreamMapNet significantly outperforms existing methods across all settings while maintaining an online inference speed of $14.2$ FPS. Our code is available at https://github.com/yuantianyuan01/StreamMapNet.
Occ3D: A Large-Scale 3D Occupancy Prediction Benchmark for Autonomous Driving
Apr 27, 2023



Robotic perception requires the modeling of both 3D geometry and semantics. Existing methods typically focus on estimating 3D bounding boxes, neglecting finer geometric details and struggling to handle general, out-of-vocabulary objects. To overcome these limitations, we introduce a novel task for 3D occupancy prediction, which aims to estimate the detailed occupancy and semantics of objects from multi-view images. To facilitate this task, we develop a label generation pipeline that produces dense, visibility-aware labels for a given scene. This pipeline includes point cloud aggregation, point labeling, and occlusion handling. We construct two benchmarks based on the Waymo Open Dataset and the nuScenes Dataset, resulting in the Occ3D-Waymo and Occ3D-nuScenes benchmarks. Lastly, we propose a model, dubbed Coarse-to-Fine Occupancy (CTF-Occ) network, which demonstrates superior performance in the 3D occupancy prediction task. This approach addresses the need for finer geometric understanding in a coarse-to-fine fashion. The code, data, and benchmarks are released at https://tsinghua-mars-lab.github.io/Occ3D/.
Neural Map Prior for Autonomous Driving
Apr 17, 2023



High-definition (HD) semantic maps are crucial for autonomous vehicles navigating urban environments. Traditional offline HD maps, created through labor-intensive manual annotation processes, are both costly and incapable of accommodating timely updates. Recently, researchers have proposed inferring local maps based on online sensor observations; however, this approach is constrained by the sensor perception range and is susceptible to occlusions. In this work, we propose Neural Map Prior (NMP), a neural representation of global maps that facilitates automatic global map updates and improves local map inference performance. To incorporate the strong map prior into local map inference, we employ cross-attention that dynamically captures correlations between current features and prior features. For updating the global neural map prior, we use a learning-based fusion module to guide the network in fusing features from previous traversals. This design allows the network to capture a global neural map prior during sequential online map predictions. Experimental results on the nuScenes dataset demonstrate that our framework is highly compatible with various map segmentation and detection architectures and considerably strengthens map prediction performance, even under adverse weather conditions and across longer horizons. To the best of our knowledge, this represents the first learning-based system for constructing a global map prior.
Facial recognition technology can expose political orientation from facial images even when controlling for demographics and self-presentation
Mar 28, 2023



A facial recognition algorithm was used to extract face descriptors from carefully standardized images of 591 neutral faces taken in the laboratory setting. Face descriptors were entered into a cross-validated linear regression to predict participants' scores on a political orientation scale (Cronbach's alpha=.94) while controlling for age, gender, and ethnicity. The model's performance exceeded r=.20: much better than that of human raters and on par with how well job interviews predict job success, alcohol drives aggressiveness, or psychological therapy improves mental health. Moreover, the model derived from standardized images performed well (r=.12) in a sample of naturalistic images of 3,401 politicians from the U.S., UK, and Canada, suggesting that the associations between facial appearance and political orientation generalize beyond our sample. The analysis of facial features associated with political orientation revealed that conservatives had larger lower faces, although political orientation was only weakly associated with body mass index (BMI). The predictability of political orientation from standardized images has critical implications for privacy, regulation of facial recognition technology, as well as the understanding the origins and consequences of political orientation.
ViP3D: End-to-end Visual Trajectory Prediction via 3D Agent Queries
Aug 02, 2022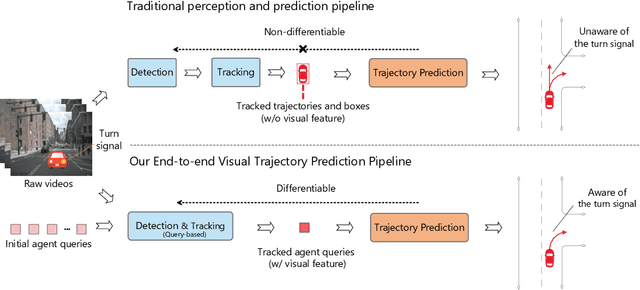
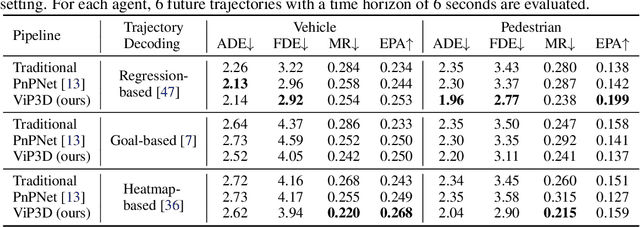
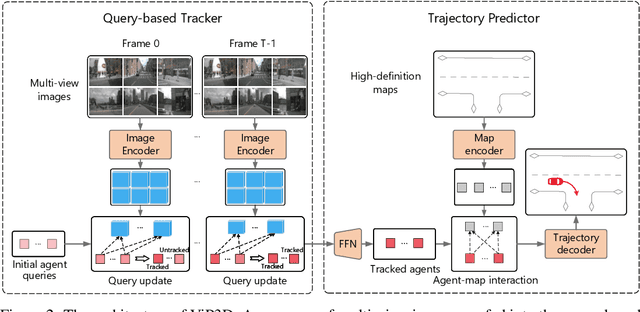
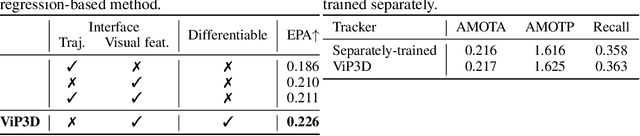
Existing autonomous driving pipelines separate the perception module from the prediction module. The two modules communicate via hand-picked features such as agent boxes and trajectories as interfaces. Due to this separation, the prediction module only receives partial information from the perception module. Even worse, errors from the perception modules can propagate and accumulate, adversely affecting the prediction results. In this work, we propose ViP3D, a visual trajectory prediction pipeline that leverages the rich information from raw videos to predict future trajectories of agents in a scene. ViP3D employs sparse agent queries throughout the pipeline, making it fully differentiable and interpretable. Furthermore, we propose an evaluation metric for this novel end-to-end visual trajectory prediction task. Extensive experimental results on the nuScenes dataset show the strong performance of ViP3D over traditional pipelines and previous end-to-end models.
VectorMapNet: End-to-end Vectorized HD Map Learning
Jun 17, 2022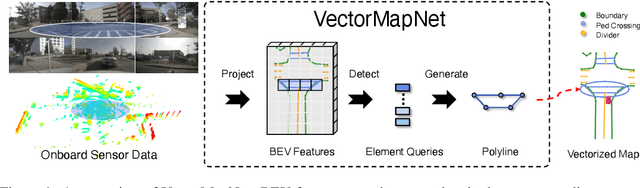
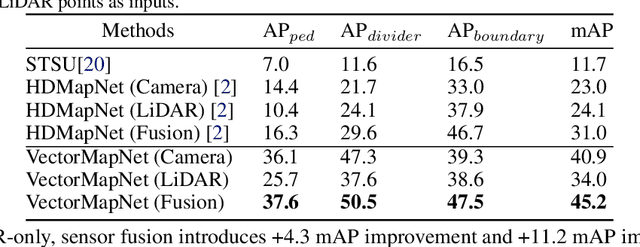
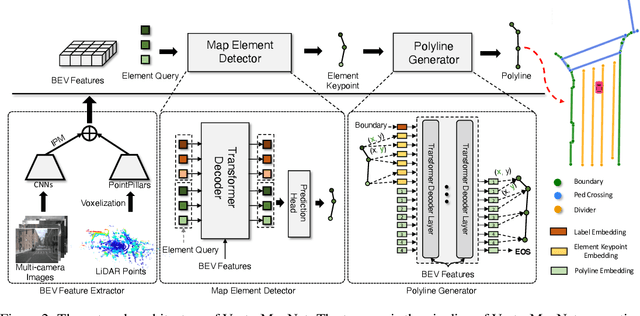

Autonomous driving systems require a good understanding of surrounding environments, including moving obstacles and static High-Definition (HD) semantic maps. Existing methods approach the semantic map problem by offline manual annotations, which suffer from serious scalability issues. More recent learning-based methods produce dense rasterized segmentation predictions which do not include instance information of individual map elements and require heuristic post-processing that involves many hand-designed components, to obtain vectorized maps. To that end, we introduce an end-to-end vectorized HD map learning pipeline, termed VectorMapNet. VectorMapNet takes onboard sensor observations and predicts a sparse set of polylines primitives in the bird's-eye view to model the geometry of HD maps. Based on this pipeline, our method can explicitly model the spatial relation between map elements and generate vectorized maps that are friendly for downstream autonomous driving tasks without the need for post-processing. In our experiments, VectorMapNet achieves strong HD map learning performance on nuScenes dataset, surpassing previous state-of-the-art methods by 14.2 mAP. Qualitatively, we also show that VectorMapNet is capable of generating comprehensive maps and capturing more fine-grained details of road geometry. To the best of our knowledge, VectorMapNet is the first work designed toward end-to-end vectorized HD map learning problems.
MUTR3D: A Multi-camera Tracking Framework via 3D-to-2D Queries
May 02, 2022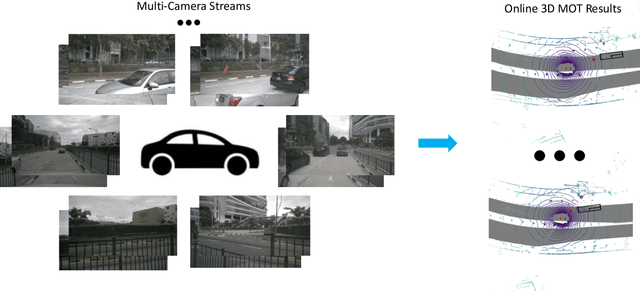
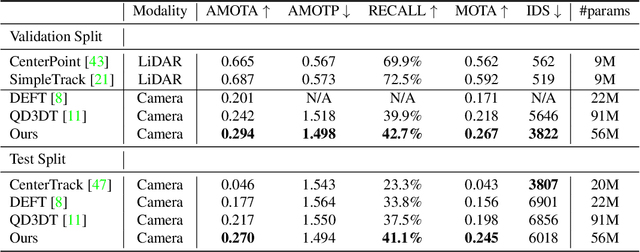
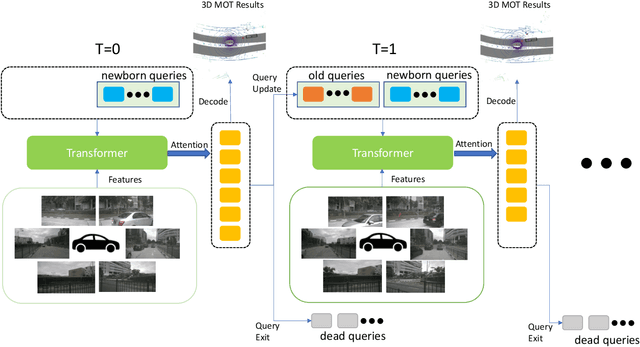

Accurate and consistent 3D tracking from multiple cameras is a key component in a vision-based autonomous driving system. It involves modeling 3D dynamic objects in complex scenes across multiple cameras. This problem is inherently challenging due to depth estimation, visual occlusions, appearance ambiguity, etc. Moreover, objects are not consistently associated across time and cameras. To address that, we propose an end-to-end \textbf{MU}lti-camera \textbf{TR}acking framework called MUTR3D. In contrast to prior works, MUTR3D does not explicitly rely on the spatial and appearance similarity of objects. Instead, our method introduces \textit{3D track query} to model spatial and appearance coherent track for each object that appears in multiple cameras and multiple frames. We use camera transformations to link 3D trackers with their observations in 2D images. Each tracker is further refined according to the features that are obtained from camera images. MUTR3D uses a set-to-set loss to measure the difference between the predicted tracking results and the ground truths. Therefore, it does not require any post-processing such as non-maximum suppression and/or bounding box association. MUTR3D outperforms state-of-the-art methods by 5.3 AMOTA on the nuScenes dataset. Code is available at: \url{https://github.com/a1600012888/MUTR3D}.
FUTR3D: A Unified Sensor Fusion Framework for 3D Detection
Mar 20, 2022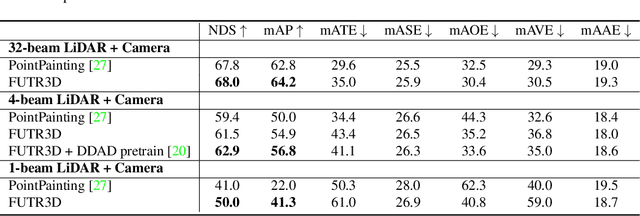
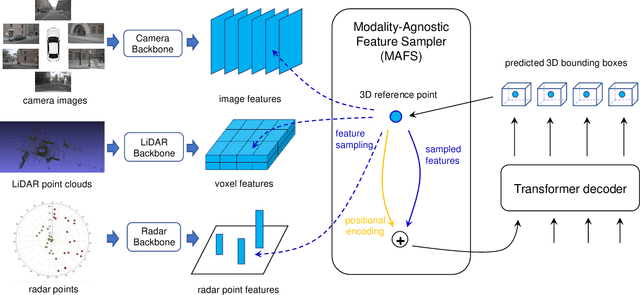

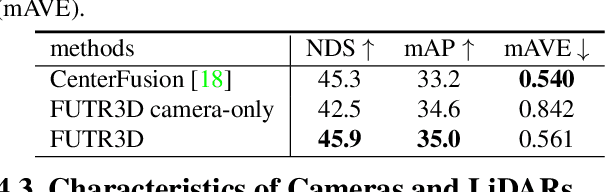
Sensor fusion is an essential topic in many perception systems, such as autonomous driving and robotics. Existing multi-modal 3D detection models usually involve customized designs depending on the sensor combinations or setups. In this work, we propose the first unified end-to-end sensor fusion framework for 3D detection, named FUTR3D, which can be used in (almost) any sensor configuration. FUTR3D employs a query-based Modality-Agnostic Feature Sampler (MAFS), together with a transformer decoder with a set-to-set loss for 3D detection, thus avoiding using late fusion heuristics and post-processing tricks. We validate the effectiveness of our framework on various combinations of cameras, low-resolution LiDARs, high-resolution LiDARs, and Radars. On NuScenes dataset, FUTR3D achieves better performance over specifically designed methods across different sensor combinations. Moreover, FUTR3D achieves great flexibility with different sensor configurations and enables low-cost autonomous driving. For example, only using a 4-beam LiDAR with cameras, FUTR3D (56.8 mAP) achieves on par performance with state-of-the-art 3D detection model CenterPoint (56.6 mAP) using a 32-beam LiDAR.