 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Map Prior for Autonomous Driving
Apr 17, 2023



High-definition (HD) semantic maps are crucial for autonomous vehicles navigating urban environments. Traditional offline HD maps, created through labor-intensive manual annotation processes, are both costly and incapable of accommodating timely updates. Recently, researchers have proposed inferring local maps based on online sensor observations; however, this approach is constrained by the sensor perception range and is susceptible to occlusions. In this work, we propose Neural Map Prior (NMP), a neural representation of global maps that facilitates automatic global map updates and improves local map inference performance. To incorporate the strong map prior into local map inference, we employ cross-attention that dynamically captures correlations between current features and prior features. For updating the global neural map prior, we use a learning-based fusion module to guide the network in fusing features from previous traversals. This design allows the network to capture a global neural map prior during sequential online map predictions. Experimental results on the nuScenes dataset demonstrate that our framework is highly compatible with various map segmentation and detection architectures and considerably strengthens map prediction performance, even under adverse weather conditions and across longer horizons. To the best of our knowledge, this represents the first learning-based system for constructing a global map prior.
RangeDet:In Defense of Range View for LiDAR-based 3D Object Detection
Mar 18, 2021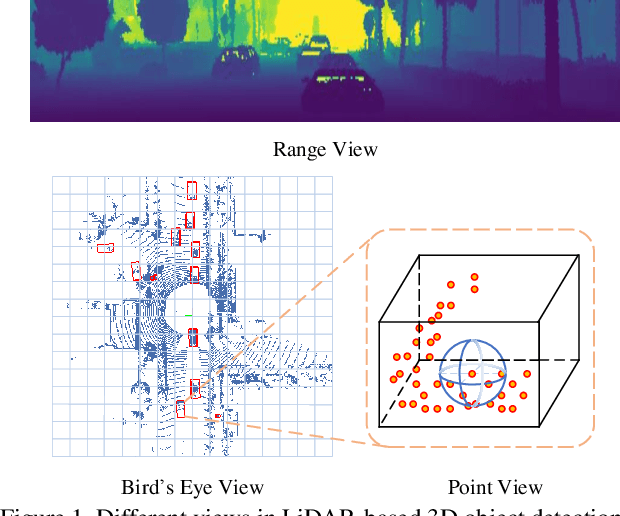
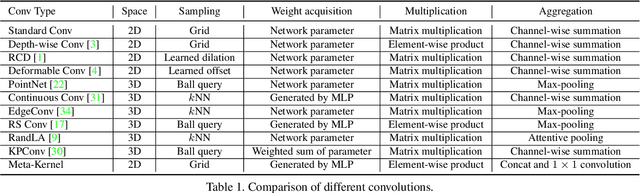
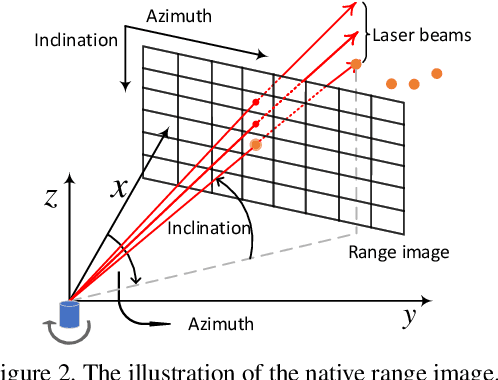
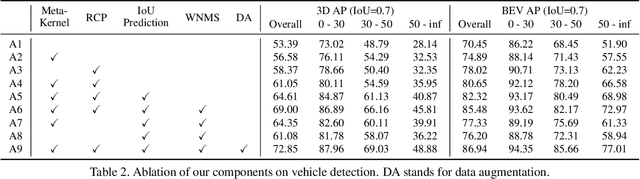
In this paper, we propose an anchor-free single-stage LiDAR-based 3D object detector -- RangeDet. The most notable difference with previous works is that our method is purely based on the range view representation. Compared with the commonly used voxelized or Bird's Eye View (BEV) representations, the range view representation is more compact and without quantization error. Although there are works adopting it for semantic segmentation, its performance in object detection is largely behind voxelized or BEV counterparts. We first analyze the existing range-view-based methods and find two issues overlooked by previous works: 1) the scale variation between nearby and far away objects; 2) the inconsistency between the 2D range image coordinates used in feature extraction and the 3D Cartesian coordinates used in output. Then we deliberately design three components to address these issues in our RangeDet. We test our RangeDet in the large-scale Waymo Open Dataset (WOD). Our best model achieves 72.9/75.9/65.8 3D AP on vehicle/pedestrian/cyclist. These results outperform other range-view-based methods by a large margin (~20 3D AP in vehicle detection), and are overall comparable with the state-of-the-art multi-view-based methods. Codes will be public.