 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion-Based Generative Models for 3D Occupancy Prediction in Autonomous Driving
May 29, 2025Accurately predicting 3D occupancy grids from visual inputs is critical for autonomous driving, but current discriminative methods struggle with noisy data, incomplete observations, and the complex structures inherent in 3D scenes. In this work, we reframe 3D occupancy prediction as a generative modeling task using diffusion models, which learn the underlying data distribution and incorporate 3D scene priors. This approach enhances prediction consistency, noise robustness, and better handles the intricacies of 3D spatial structures. Our extensive experiments show that diffusion-based generative models outperform state-of-the-art discriminative approaches, delivering more realistic and accurate occupancy predictions, especially in occluded or low-visibility regions. Moreover, the improved predictions significantly benefit downstream planning tasks, highlighting the practical advantages of our method for real-world autonomous driving applications.
P-MapNet: Far-seeing Map Generator Enhanced by both SDMap and HDMap Priors
Mar 29, 2024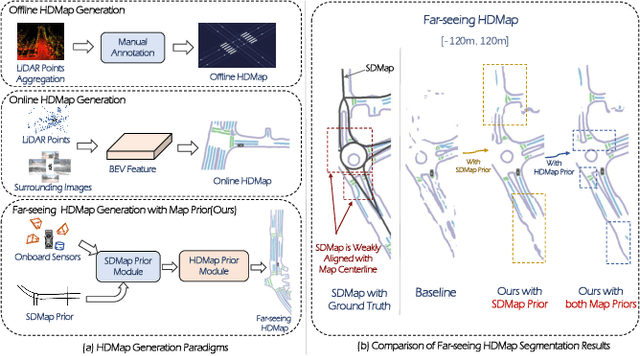
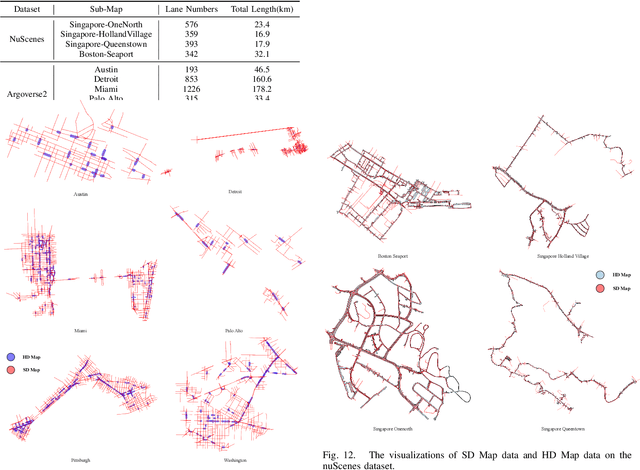
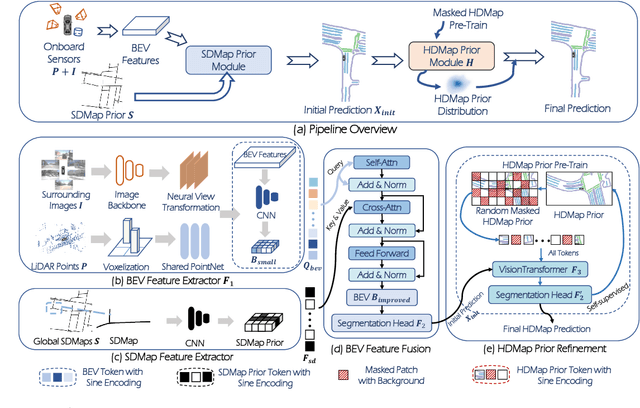
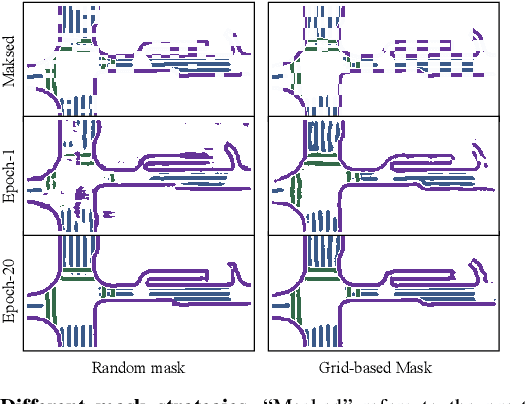
Autonomous vehicles are gradually entering city roads today, with the help of high-definition maps (HDMaps). However, the reliance on HDMaps prevents autonomous vehicles from stepping into regions without this expensive digital infrastructure. This fact drives many researchers to study online HDMap generation algorithms, but the performance of these algorithms at far regions is still unsatisfying. We present P-MapNet, in which the letter P highlights the fact that we focus on incorporating map priors to improve model performance. Specifically, we exploit priors in both SDMap and HDMap. On one hand, we extract weakly aligned SDMap from OpenStreetMap, and encode it as an additional conditioning branch. Despite the misalignment challenge, our attention-based architecture adaptively attends to relevant SDMap skeletons and significantly improves performance. On the other hand, we exploit a masked autoencoder to capture the prior distribution of HDMap, which can serve as a refinement module to mitigate occlusions and artifacts. We benchmark on the nuScenes and Argoverse2 datasets. Through comprehensive experiments, we show that: (1) our SDMap prior can improve online map generation performance, using both rasterized (by up to $+18.73$ $\rm mIoU$) and vectorized (by up to $+8.50$ $\rm mAP$) output representations. (2) our HDMap prior can improve map perceptual metrics by up to $6.34\%$. (3) P-MapNet can be switched into different inference modes that covers different regions of the accuracy-efficiency trade-off landscape. (4) P-MapNet is a far-seeing solution that brings larger improvements on longer ranges. Codes and models are publicly available at https://jike5.github.io/P-MapNet.
PreSight: Enhancing Autonomous Vehicle Perception with City-Scale NeRF Priors
Mar 14, 2024



Autonomous vehicles rely extensively on perception systems to navigate and interpret their surroundings. Despite significant advancements in these systems recently, challenges persist under conditions like occlusion, extreme lighting, or in unfamiliar urban areas. Unlike these systems, humans do not solely depend on immediate observations to perceive the environment. In navigating new cities, humans gradually develop a preliminary mental map to supplement real-time perception during subsequent visits. Inspired by this human approach, we introduce a novel framework, Pre-Sight, that leverages past traversals to construct static prior memories, enhancing online perception in later navigations. Our method involves optimizing a city-scale neural radiance field with data from previous journeys to generate neural priors. These priors, rich in semantic and geometric details, are derived without manual annotations and can seamlessly augment various state-of-the-art perception models, improving their efficacy with minimal additional computational cost. Experimental results on the nuScenes dataset demonstrate the framework's high compatibility with diverse online perception models. Specifically, it shows remarkable improvements in HD-map construction and occupancy prediction tasks, highlighting its potential as a new perception framework for autonomous driving systems. Our code will be released at https://github.com/yuantianyuan01/PreSight.
StreamMapNet: Streaming Mapping Network for Vectorized Online HD Map Construction
Aug 27, 2023High-Definition (HD) maps are essential for the safety of autonomous driving systems. While existing techniques employ camera images and onboard sensors to generate vectorized high-precision maps, they are constrained by their reliance on single-frame input. This approach limits their stability and performance in complex scenarios such as occlusions, largely due to the absence of temporal information. Moreover, their performance diminishes when applied to broader perception ranges. In this paper, we present StreamMapNet, a novel online mapping pipeline adept at long-sequence temporal modeling of videos. StreamMapNet employs multi-point attention and temporal information which empowers the construction of large-range local HD maps with high stability and further addresses the limitations of existing methods. Furthermore, we critically examine widely used online HD Map construction benchmark and datasets, Argoverse2 and nuScenes, revealing significant bias in the existing evaluation protocols. We propose to resplit the benchmarks according to geographical spans, promoting fair and precise evaluations. Experimental results validate that StreamMapNet significantly outperforms existing methods across all settings while maintaining an online inference speed of $14.2$ FPS. Our code is available at https://github.com/yuantianyuan01/StreamMapNet.
On Uni-Modal Feature Learning in Supervised Multi-Modal Learning
May 03, 2023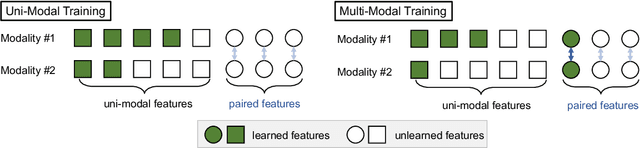
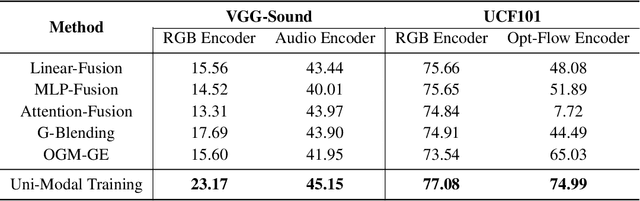
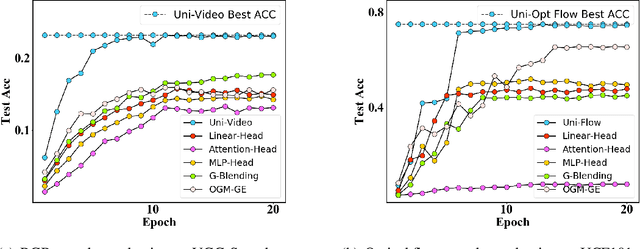
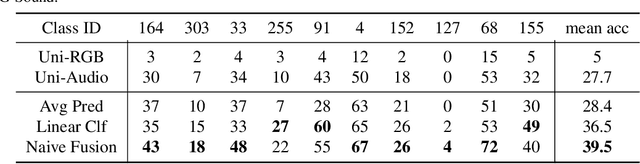
We abstract the features (i.e. learned representations) of multi-modal data into 1) uni-modal features, which can be learned from uni-modal training, and 2) paired features, which can only be learned from cross-modal interactions. Multi-modal models are expected to benefit from cross-modal interactions on the basis of ensuring uni-modal feature learning. However, recent supervised multi-modal late-fusion training approaches still suffer from insufficient learning of uni-modal features on each modality. We prove that this phenomenon does hurt the model's generalization ability. To this end, we propose to choose a targeted late-fusion learning method for the given supervised multi-modal task from Uni-Modal Ensemble(UME) and the proposed Uni-Modal Teacher(UMT), according to the distribution of uni-modal and paired features. We demonstrate that, under a simple guiding strategy, we can achieve comparable results to other complex late-fusion or intermediate-fusion methods on various multi-modal datasets, including VGG-Sound, Kinetics-400, UCF101, and ModelNet40.
Neural Map Prior for Autonomous Driving
Apr 17, 2023



High-definition (HD) semantic maps are crucial for autonomous vehicles navigating urban environments. Traditional offline HD maps, created through labor-intensive manual annotation processes, are both costly and incapable of accommodating timely updates. Recently, researchers have proposed inferring local maps based on online sensor observations; however, this approach is constrained by the sensor perception range and is susceptible to occlusions. In this work, we propose Neural Map Prior (NMP), a neural representation of global maps that facilitates automatic global map updates and improves local map inference performance. To incorporate the strong map prior into local map inference, we employ cross-attention that dynamically captures correlations between current features and prior features. For updating the global neural map prior, we use a learning-based fusion module to guide the network in fusing features from previous traversals. This design allows the network to capture a global neural map prior during sequential online map predictions. Experimental results on the nuScenes dataset demonstrate that our framework is highly compatible with various map segmentation and detection architectures and considerably strengthens map prediction performance, even under adverse weather conditions and across longer horizons. To the best of our knowledge, this represents the first learning-based system for constructing a global map prior.