 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCosmos 3: Omnimodal World Models for Physical AI
Jun 01, 2026We introduce Cosmos 3, a family of omnimodal world models designed to jointly process and generate language, image, video, audio, and action sequences within a unified mixture-of-transformers architecture. By supporting highly flexible input-output configurations, Cosmos 3 seamlessly unifies critical modalities for Physical AI -- effectively subsuming vision-language models, video generators, world simulators, and world-action models into a single framework. Our evaluation demonstrates that Cosmos 3 establishes a new state-of-the-art across a diverse suite of understanding and generation tasks, demonstrating omnimodal world models as scalable, general-purpose backbones for embodied agents. Our post-trained Cosmos 3 models were ranked as the best open-source Text-to-Image and Image-to-Video models by Artificial Analysis, and the best policy model by RoboArena at the time the technical report was written. To accelerate open research and deployment in Physical AI, we make our code, model checkpoints, curated synthetic datasets, and evaluation benchmark available under the Linux Foundation's OpenMDW-1.1 https://openmdw.ai/license/1-1/ License at https://github.com/nvidia/cosmos}{github.com/nvidia/cosmos and https://huggingface.co/collections/nvidia/cosmos3 . The project website is available at https://research.nvidia.com/labs/cosmos-lab/cosmos3 .
Benchmarking Single-Factor Physical Video-to-Audio Generation
May 28, 2026Generative video-to-audio (V2A) models produce highly plausible soundtracks, but it remains unclear whether they capture the underlying physical processes. Existing evaluations emphasize perceptual realism and overlook physical correctness under controlled interventions. In this paper, we introduce FlatSounds, a benchmark that audits the physical reasoning of V2A models through: 1) controlled counterfactual pairs in which a single physical factor is varied, and 2) single-video pattern tests that probe internal consistency and directional trends. These settings test whether the generated audio correctly reflects specific physical properties and timings. Our evaluation of state-of-the-art models reveals a consistent trade-off: models rely more on text captions than the visual stream to infer physics and semantics. Captions generally improve physical and semantic accuracy, but paradoxically degrade temporal alignment. Our results highlight the need to move beyond audio quality toward learning physical processes directly from pixels. Finally, we find that our physics-based metrics correlate strongly with human preference tests on our own data. Project webpage: https://research.nvidia.com/labs/cosmos-lab/flatsounds/
Conversational Behavior Modeling Foundation Model With Multi-Level Perception
Feb 11, 2026Human conversation is organized by an implicit chain of thoughts that manifests as timed speech acts. Capturing this perceptual pathway is key to building natural full-duplex interactive systems. We introduce a framework that models this process as multi-level perception, and then reasons over conversational behaviors via a Graph-of-Thoughts (GoT). Our approach formalizes the intent-to-action pathway with a hierarchical labeling scheme, predicting high-level communicative intents and low-level speech acts to learn their causal and temporal dependencies. To train this system, we develop a high quality corpus that pairs controllable, event-rich dialogue data with human-annotated labels. The GoT framework structures streaming predictions as an evolving graph, enabling a transformer to forecast the next speech act, generate concise justifications for its decisions, and dynamically refine its reasoning. Experiments on both synthetic and real duplex dialogues show that the framework delivers robust behavior detection, produces interpretable reasoning chains, and establishes a foundation for benchmarking conversational reasoning in full duplex spoken dialogue systems.
Enabling Conversational Behavior Reasoning Capabilities in Full-Duplex Speech
Dec 25, 2025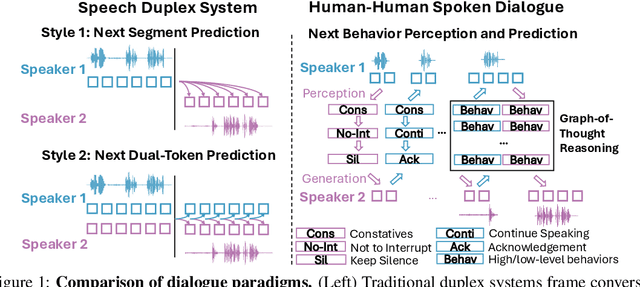

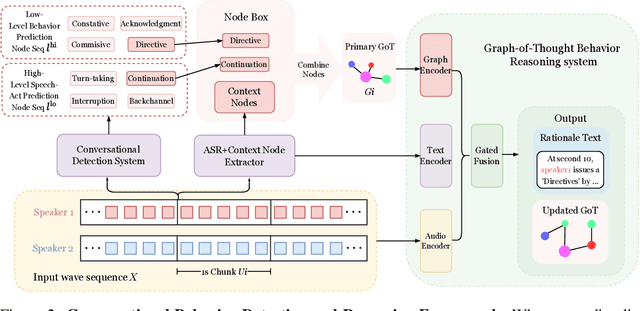

Human conversation is organized by an implicit chain of thoughts that manifests as timed speech acts. Capturing this causal pathway is key to building natural full-duplex interactive systems. We introduce a framework that enables reasoning over conversational behaviors by modeling this process as causal inference within a Graph-of-Thoughts (GoT). Our approach formalizes the intent-to-action pathway with a hierarchical labeling scheme, predicting high-level communicative intents and low-level speech acts to learn their causal and temporal dependencies. To train this system, we develop a hybrid corpus that pairs controllable, event-rich simulations with human-annotated rationales and real conversational speech. The GoT framework structures streaming predictions as an evolving graph, enabling a multimodal transformer to forecast the next speech act, generate concise justifications for its decisions, and dynamically refine its reasoning. Experiments on both synthetic and real duplex dialogues show that the framework delivers robust behavior detection, produces interpretable reasoning chains, and establishes a foundation for benchmarking conversational reasoning in full duplex spoken dialogue systems.
Schrodinger Audio-Visual Editor: Object-Level Audiovisual Removal
Dec 14, 2025Joint editing of audio and visual content is crucial for precise and controllable content creation. This new task poses challenges due to the limitations of paired audio-visual data before and after targeted edits, and the heterogeneity across modalities. To address the data and modeling challenges in joint audio-visual editing, we introduce SAVEBench, a paired audiovisual dataset with text and mask conditions to enable object-grounded source-to-target learning. With SAVEBench, we train the Schrodinger Audio-Visual Editor (SAVE), an end-to-end flow-matching model that edits audio and video in parallel while keeping them aligned throughout processing. SAVE incorporates a Schrodinger Bridge that learns a direct transport from source to target audiovisual mixtures. Our evaluation demonstrates that the proposed SAVE model is able to remove the target objects in audio and visual content while preserving the remaining content, with stronger temporal synchronization and audiovisual semantic correspondence compared with pairwise combinations of an audio editor and a video editor.
EMO-Reasoning: Benchmarking Emotional Reasoning Capabilities in Spoken Dialogue Systems
Aug 25, 2025Speech emotions play a crucial role in human-computer interaction, shaping engagement and context-aware communication. Despite recent advances in spoken dialogue systems, a holistic system for evaluating emotional reasoning is still lacking. To address this, we introduce EMO-Reasoning, a benchmark for assessing emotional coherence in dialogue systems. It leverages a curated dataset generated via text-to-speech to simulate diverse emotional states, overcoming the scarcity of emotional speech data. We further propose the Cross-turn Emotion Reasoning Score to assess the emotion transitions in multi-turn dialogues. Evaluating seven dialogue systems through continuous, categorical, and perceptual metrics, we show that our framework effectively detects emotional inconsistencies, providing insights for improving current dialogue systems. By releasing a systematic evaluation benchmark, we aim to advance emotion-aware spoken dialogue modeling toward more natural and adaptive interactions.
MultiGen: Using Multimodal Generation in Simulation to Learn Multimodal Policies in Real
Jul 03, 2025Robots must integrate multiple sensory modalities to act effectively in the real world. Yet, learning such multimodal policies at scale remains challenging. Simulation offers a viable solution, but while vision has benefited from high-fidelity simulators, other modalities (e.g. sound) can be notoriously difficult to simulate. As a result, sim-to-real transfer has succeeded primarily in vision-based tasks, with multimodal transfer still largely unrealized. In this work, we tackle these challenges by introducing MultiGen, a framework that integrates large-scale generative models into traditional physics simulators, enabling multisensory simulation. We showcase our framework on the dynamic task of robot pouring, which inherently relies on multimodal feedback. By synthesizing realistic audio conditioned on simulation video, our method enables training on rich audiovisual trajectories -- without any real robot data. We demonstrate effective zero-shot transfer to real-world pouring with novel containers and liquids, highlighting the potential of generative modeling to both simulate hard-to-model modalities and close the multimodal sim-to-real gap.
Sounding that Object: Interactive Object-Aware Image to Audio Generation
Jun 04, 2025
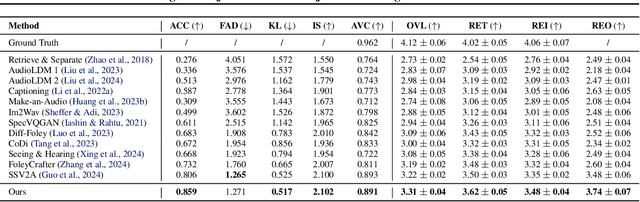


Generating accurate sounds for complex audio-visual scenes is challenging, especially in the presence of multiple objects and sound sources. In this paper, we propose an {\em interactive object-aware audio generation} model that grounds sound generation in user-selected visual objects within images. Our method integrates object-centric learning into a conditional latent diffusion model, which learns to associate image regions with their corresponding sounds through multi-modal attention. At test time, our model employs image segmentation to allow users to interactively generate sounds at the {\em object} level. We theoretically validate that our attention mechanism functionally approximates test-time segmentation masks, ensuring the generated audio aligns with selected objects. Quantitative and qualitative evaluations show that our model outperforms baselines, achieving better alignment between objects and their associated sounds. Project page: https://tinglok.netlify.app/files/avobject/
Full-Duplex-Bench: A Benchmark to Evaluate Full-duplex Spoken Dialogue Models on Turn-taking Capabilities
Mar 06, 2025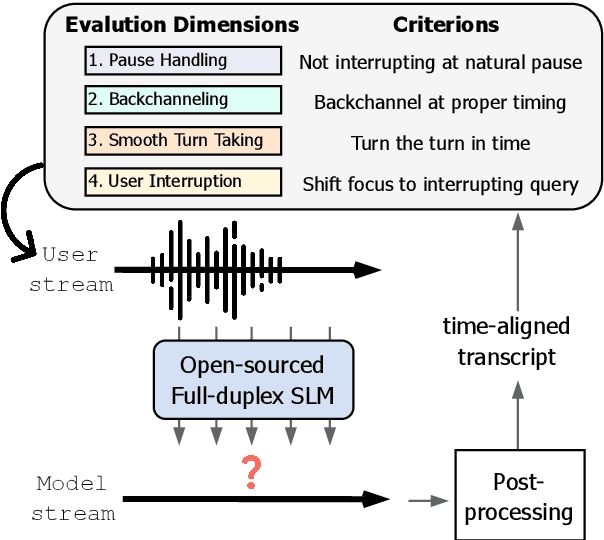
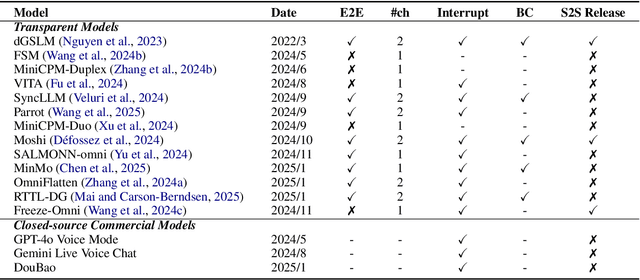
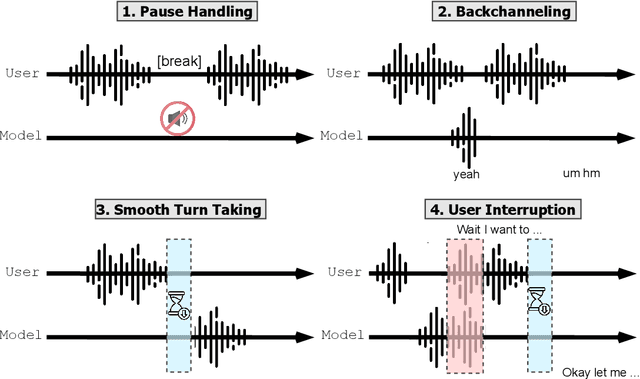

Spoken dialogue modeling introduces unique challenges beyond text-based language modeling, demanding robust turn-taking, backchanneling, and real-time interaction. Although most Spoken Dialogue Models (SDMs) rely on half-duplex processing (handling speech one turn at a time), emerging full-duplex SDMs can listen and speak simultaneously, enabling more natural and engaging conversations. However, current evaluations of such models remain limited, often focusing on turn-based metrics or high-level corpus analyses (e.g., turn gaps, pauses). To address this gap, we present Full-Duplex-Bench, a new benchmark that systematically evaluates key conversational behaviors: pause handling, backchanneling, turn-taking, and interruption management. Our framework uses automatic metrics for consistent and reproducible assessments of SDMs' interactive performance. By offering an open and standardized evaluation benchmark, we aim to advance spoken dialogue modeling and encourage the development of more interactive and natural dialogue systems.
Audio Texture Manipulation by Exemplar-Based Analogy
Jan 21, 2025



Audio texture manipulation involves modifying the perceptual characteristics of a sound to achieve specific transformations, such as adding, removing, or replacing auditory elements. In this paper, we propose an exemplar-based analogy model for audio texture manipulation. Instead of conditioning on text-based instructions, our method uses paired speech examples, where one clip represents the original sound and another illustrates the desired transformation. The model learns to apply the same transformation to new input, allowing for the manipulation of sound textures. We construct a quadruplet dataset representing various editing tasks, and train a latent diffusion model in a self-supervised manner. We show through quantitative evaluations and perceptual studies that our model outperforms text-conditioned baselines and generalizes to real-world, out-of-distribution, and non-speech scenarios. Project page: https://berkeley-speech-group.github.io/audio-texture-analogy/