 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRadio2Text: Streaming Speech Recognition Using mmWave Radio Signals
Aug 16, 2023Millimeter wave (mmWave) based speech recognition provides more possibility for audio-related applications, such as conference speech transcription and eavesdropping. However, considering the practicality in real scenarios, latency and recognizable vocabulary size are two critical factors that cannot be overlooked. In this paper, we propose Radio2Text, the first mmWave-based system for streaming automatic speech recognition (ASR) with a vocabulary size exceeding 13,000 words. Radio2Text is based on a tailored streaming Transformer that is capable of effectively learning representations of speech-related features, paving the way for streaming ASR with a large vocabulary. To alleviate the deficiency of streaming networks unable to access entire future inputs, we propose the Guidance Initialization that facilitates the transfer of feature knowledge related to the global context from the non-streaming Transformer to the tailored streaming Transformer through weight inheritance. Further, we propose a cross-modal structure based on knowledge distillation (KD), named cross-modal KD, to mitigate the negative effect of low quality mmWave signals on recognition performance. In the cross-modal KD, the audio streaming Transformer provides feature and response guidance that inherit fruitful and accurate speech information to supervise the training of the tailored radio streaming Transformer. The experimental results show that our Radio2Text can achieve a character error rate of 5.7% and a word error rate of 9.4% for the recognition of a vocabulary consisting of over 13,000 words.
Radio2Speech: High Quality Speech Recovery from Radio Frequency Signals
Jun 22, 2022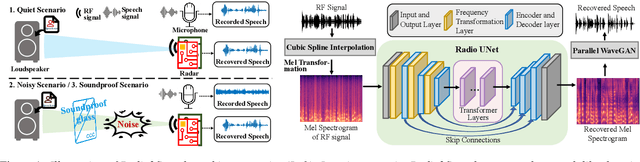
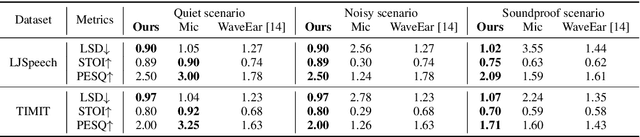

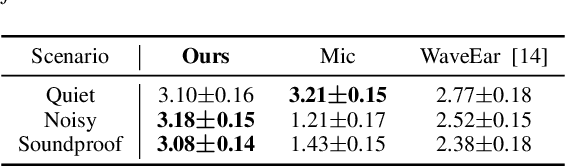
Considering the microphone is easily affected by noise and soundproof materials, the radio frequency (RF) signal is a promising candidate to recover audio as it is immune to noise and can traverse many soundproof objects. In this paper, we introduce Radio2Speech, a system that uses RF signals to recover high quality speech from the loudspeaker. Radio2Speech can recover speech comparable to the quality of the microphone, advancing from recovering only single tone music or incomprehensible speech in existing approaches. We use Radio UNet to accurately recover speech in time-frequency domain from RF signals with limited frequency band. Also, we incorporate the neural vocoder to synthesize the speech waveform from the estimated time-frequency representation without using the contaminated phase. Quantitative and qualitative evaluations show that in quiet, noisy and soundproof scenarios, Radio2Speech achieves state-of-the-art performance and is on par with the microphone that works in quiet scenarios.