 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoteIt: A System Converting Instructional Videos to Interactable Notes Through Multimodal Video Understanding
Aug 20, 2025



Users often take notes for instructional videos to access key knowledge later without revisiting long videos. Automated note generation tools enable users to obtain informative notes efficiently. However, notes generated by existing research or off-the-shelf tools fail to preserve the information conveyed in the original videos comprehensively, nor can they satisfy users' expectations for diverse presentation formats and interactive features when using notes digitally. In this work, we present NoteIt, a system, which automatically converts instructional videos to interactable notes using a novel pipeline that faithfully extracts hierarchical structure and multimodal key information from videos. With NoteIt's interface, users can interact with the system to further customize the content and presentation formats of the notes according to their preferences. We conducted both a technical evaluation and a comparison user study (N=36). The solid performance in objective metrics and the positive user feedback demonstrated the effectiveness of the pipeline and the overall usability of NoteIt. Project website: https://zhaorunning.github.io/NoteIt/
Continual Learning with Strategic Selection and Forgetting for Network Intrusion Detection
Dec 20, 2024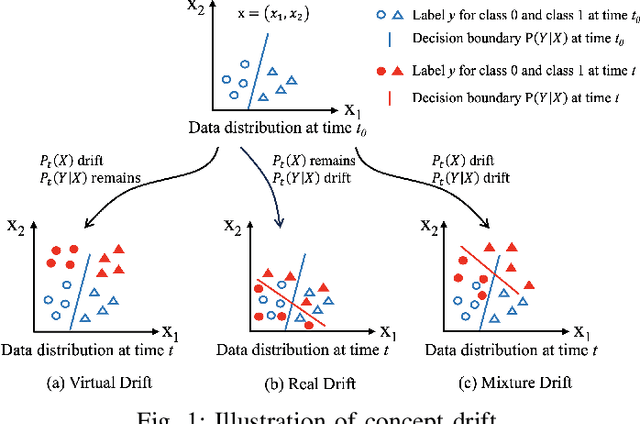
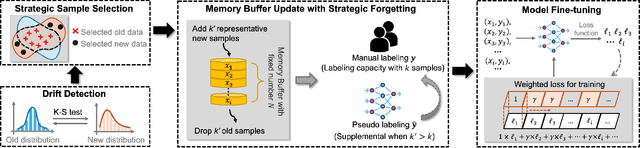
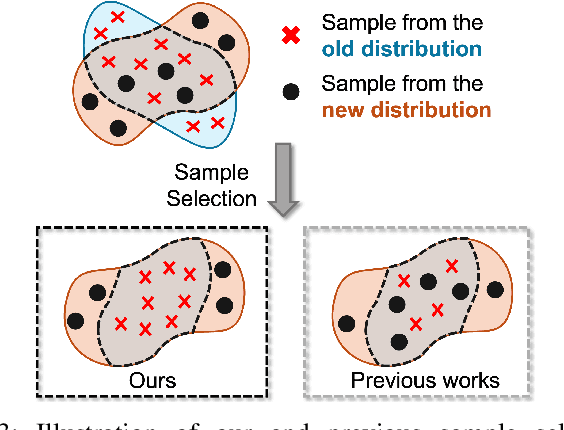
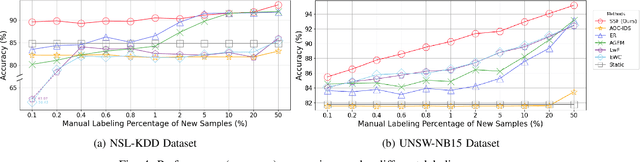
Intrusion Detection Systems (IDS) are crucial for safeguarding digital infrastructure. In dynamic network environments, both threat landscapes and normal operational behaviors are constantly changing, resulting in concept drift. While continuous learning mitigates the adverse effects of concept drift, insufficient attention to drift patterns and excessive preservation of outdated knowledge can still hinder the IDS's adaptability. In this paper, we propose SSF (Strategic Selection and Forgetting), a novel continual learning method for IDS, providing continuous model updates with a constantly refreshed memory buffer. Our approach features a strategic sample selection algorithm to select representative new samples and a strategic forgetting mechanism to drop outdated samples. The proposed strategic sample selection algorithm prioritizes new samples that cause the `drifted' pattern, enabling the model to better understand the evolving landscape. Additionally, we introduce strategic forgetting upon detecting significant drift by discarding outdated samples to free up memory, allowing the incorporation of more recent data. SSF captures evolving patterns effectively and ensures the model is aligned with the change of data patterns, significantly enhancing the IDS's adaptability to concept drift. The state-of-the-art performance of SSF on NSL-KDD and UNSW-NB15 datasets demonstrates its superior adaptability to concept drift for network intrusion detection.
USpeech: Ultrasound-Enhanced Speech with Minimal Human Effort via Cross-Modal Synthesis
Oct 29, 2024



Speech enhancement is crucial in human-computer interaction, especially for ubiquitous devices. Ultrasound-based speech enhancement has emerged as an attractive choice because of its superior ubiquity and performance. However, inevitable interference from unexpected and unintended sources during audio-ultrasound data acquisition makes existing solutions rely heavily on human effort for data collection and processing. This leads to significant data scarcity that limits the full potential of ultrasound-based speech enhancement. To address this, we propose USpeech, a cross-modal ultrasound synthesis framework for speech enhancement with minimal human effort. At its core is a two-stage framework that establishes correspondence between visual and ultrasonic modalities by leveraging audible audio as a bridge. This approach overcomes challenges from the lack of paired video-ultrasound datasets and the inherent heterogeneity between video and ultrasound data. Our framework incorporates contrastive video-audio pre-training to project modalities into a shared semantic space and employs an audio-ultrasound encoder-decoder for ultrasound synthesis. We then present a speech enhancement network that enhances speech in the time-frequency domain and recovers the clean speech waveform via a neural vocoder. Comprehensive experiments show USpeech achieves remarkable performance using synthetic ultrasound data comparable to physical data, significantly outperforming state-of-the-art ultrasound-based speech enhancement baselines. USpeech is open-sourced at https://github.com/aiot-lab/USpeech/.
Internal Cross-layer Gradients for Extending Homogeneity to Heterogeneity in Federated Learning
Aug 22, 2023

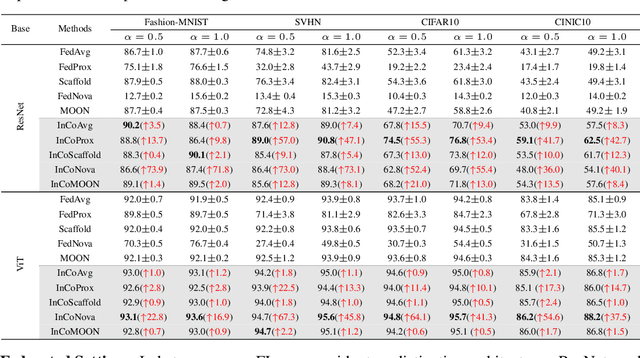

Federated learning (FL) inevitably confronts the challenge of system heterogeneity in practical scenarios. To enhance the capabilities of most model-homogeneous FL methods in handling system heterogeneity, we propose a training scheme that can extend their capabilities to cope with this challenge. In this paper, we commence our study with a detailed exploration of homogeneous and heterogeneous FL settings and discover three key observations: (1) a positive correlation between client performance and layer similarities, (2) higher similarities in the shallow layers in contrast to the deep layers, and (3) the smoother gradients distributions indicate the higher layer similarities. Building upon these observations, we propose InCo Aggregation that leverags internal cross-layer gradients, a mixture of gradients from shallow and deep layers within a server model, to augment the similarity in the deep layers without requiring additional communication between clients. Furthermore, our methods can be tailored to accommodate model-homogeneous FL methods such as FedAvg, FedProx, FedNova, Scaffold, and MOON, to expand their capabilities to handle the system heterogeneity. Copious experimental results validate the effectiveness of InCo Aggregation, spotlighting internal cross-layer gradients as a promising avenue to enhance the performance in heterogenous FL.
Radio2Text: Streaming Speech Recognition Using mmWave Radio Signals
Aug 16, 2023Millimeter wave (mmWave) based speech recognition provides more possibility for audio-related applications, such as conference speech transcription and eavesdropping. However, considering the practicality in real scenarios, latency and recognizable vocabulary size are two critical factors that cannot be overlooked. In this paper, we propose Radio2Text, the first mmWave-based system for streaming automatic speech recognition (ASR) with a vocabulary size exceeding 13,000 words. Radio2Text is based on a tailored streaming Transformer that is capable of effectively learning representations of speech-related features, paving the way for streaming ASR with a large vocabulary. To alleviate the deficiency of streaming networks unable to access entire future inputs, we propose the Guidance Initialization that facilitates the transfer of feature knowledge related to the global context from the non-streaming Transformer to the tailored streaming Transformer through weight inheritance. Further, we propose a cross-modal structure based on knowledge distillation (KD), named cross-modal KD, to mitigate the negative effect of low quality mmWave signals on recognition performance. In the cross-modal KD, the audio streaming Transformer provides feature and response guidance that inherit fruitful and accurate speech information to supervise the training of the tailored radio streaming Transformer. The experimental results show that our Radio2Text can achieve a character error rate of 5.7% and a word error rate of 9.4% for the recognition of a vocabulary consisting of over 13,000 words.
Radio2Speech: High Quality Speech Recovery from Radio Frequency Signals
Jun 22, 2022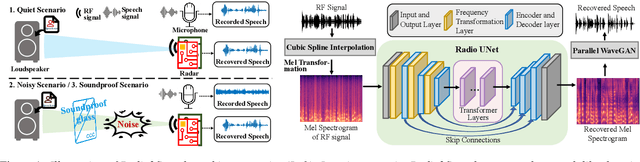
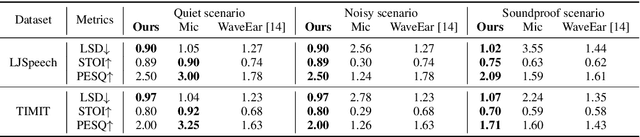

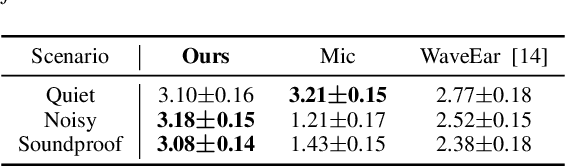
Considering the microphone is easily affected by noise and soundproof materials, the radio frequency (RF) signal is a promising candidate to recover audio as it is immune to noise and can traverse many soundproof objects. In this paper, we introduce Radio2Speech, a system that uses RF signals to recover high quality speech from the loudspeaker. Radio2Speech can recover speech comparable to the quality of the microphone, advancing from recovering only single tone music or incomprehensible speech in existing approaches. We use Radio UNet to accurately recover speech in time-frequency domain from RF signals with limited frequency band. Also, we incorporate the neural vocoder to synthesize the speech waveform from the estimated time-frequency representation without using the contaminated phase. Quantitative and qualitative evaluations show that in quiet, noisy and soundproof scenarios, Radio2Speech achieves state-of-the-art performance and is on par with the microphone that works in quiet scenarios.