 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoteIt: A System Converting Instructional Videos to Interactable Notes Through Multimodal Video Understanding
Aug 20, 2025



Users often take notes for instructional videos to access key knowledge later without revisiting long videos. Automated note generation tools enable users to obtain informative notes efficiently. However, notes generated by existing research or off-the-shelf tools fail to preserve the information conveyed in the original videos comprehensively, nor can they satisfy users' expectations for diverse presentation formats and interactive features when using notes digitally. In this work, we present NoteIt, a system, which automatically converts instructional videos to interactable notes using a novel pipeline that faithfully extracts hierarchical structure and multimodal key information from videos. With NoteIt's interface, users can interact with the system to further customize the content and presentation formats of the notes according to their preferences. We conducted both a technical evaluation and a comparison user study (N=36). The solid performance in objective metrics and the positive user feedback demonstrated the effectiveness of the pipeline and the overall usability of NoteIt. Project website: https://zhaorunning.github.io/NoteIt/
Continual Learning with Strategic Selection and Forgetting for Network Intrusion Detection
Dec 20, 2024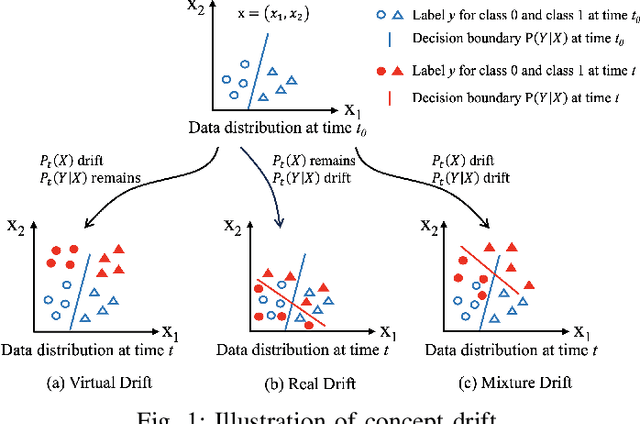
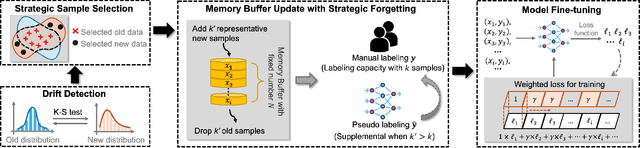
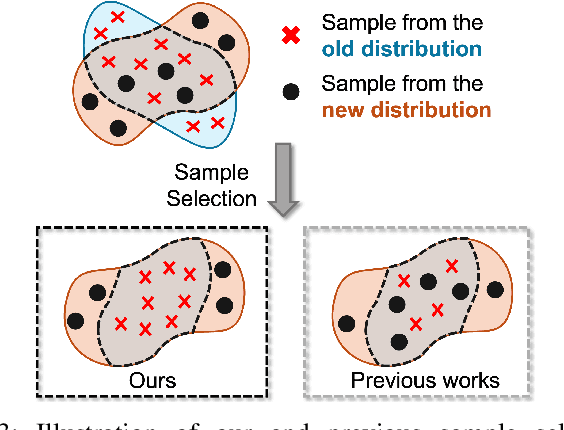
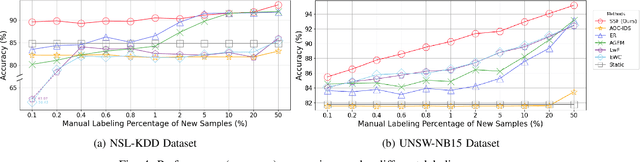
Intrusion Detection Systems (IDS) are crucial for safeguarding digital infrastructure. In dynamic network environments, both threat landscapes and normal operational behaviors are constantly changing, resulting in concept drift. While continuous learning mitigates the adverse effects of concept drift, insufficient attention to drift patterns and excessive preservation of outdated knowledge can still hinder the IDS's adaptability. In this paper, we propose SSF (Strategic Selection and Forgetting), a novel continual learning method for IDS, providing continuous model updates with a constantly refreshed memory buffer. Our approach features a strategic sample selection algorithm to select representative new samples and a strategic forgetting mechanism to drop outdated samples. The proposed strategic sample selection algorithm prioritizes new samples that cause the `drifted' pattern, enabling the model to better understand the evolving landscape. Additionally, we introduce strategic forgetting upon detecting significant drift by discarding outdated samples to free up memory, allowing the incorporation of more recent data. SSF captures evolving patterns effectively and ensures the model is aligned with the change of data patterns, significantly enhancing the IDS's adaptability to concept drift. The state-of-the-art performance of SSF on NSL-KDD and UNSW-NB15 datasets demonstrates its superior adaptability to concept drift for network intrusion detection.
Towards Edge General Intelligence via Large Language Models: Opportunities and Challenges
Oct 16, 2024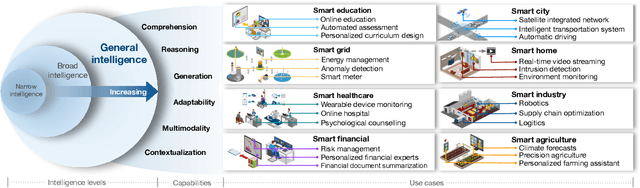
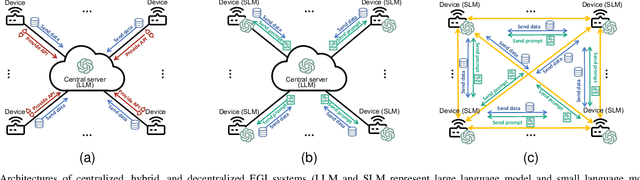
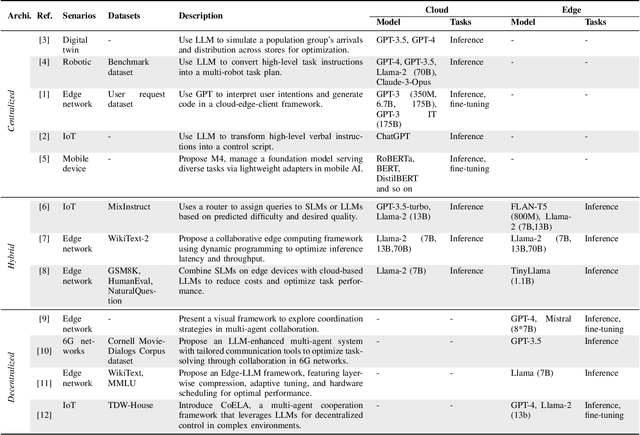
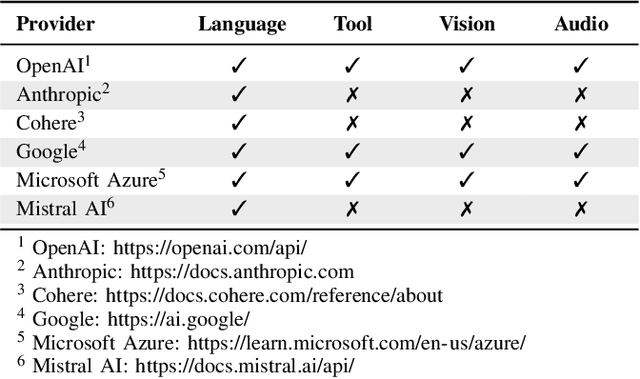
Edge Intelligence (EI) has been instrumental in delivering real-time, localized services by leveraging the computational capabilities of edge networks. The integration of Large Language Models (LLMs) empowers EI to evolve into the next stage: Edge General Intelligence (EGI), enabling more adaptive and versatile applications that require advanced understanding and reasoning capabilities. However, systematic exploration in this area remains insufficient. This survey delineates the distinctions between EGI and traditional EI, categorizing LLM-empowered EGI into three conceptual systems: centralized, hybrid, and decentralized. For each system, we detail the framework designs and review existing implementations. Furthermore, we evaluate the performance and throughput of various Small Language Models (SLMs) that are more suitable for development on edge devices. This survey provides researchers with a comprehensive vision of EGI, offering insights into its vast potential and establishing a foundation for future advancements in this rapidly evolving field.
FaultProfIT: Hierarchical Fault Profiling of Incident Tickets in Large-scale Cloud Systems
Feb 27, 2024Postmortem analysis is essential in the management of incidents within cloud systems, which provides valuable insights to improve system's reliability and robustness. At CloudA, fault pattern profiling is performed during the postmortem phase, which involves the classification of incidents' faults into unique categories, referred to as fault pattern. By aggregating and analyzing these fault patterns, engineers can discern common faults, vulnerable components and emerging fault trends. However, this process is currently conducted by manual labeling, which has inherent drawbacks. On the one hand, the sheer volume of incidents means only the most severe ones are analyzed, causing a skewed overview of fault patterns. On the other hand, the complexity of the task demands extensive domain knowledge, which leads to errors and inconsistencies. To address these limitations, we propose an automated approach, named FaultProfIT, for Fault pattern Profiling of Incident Tickets. It leverages hierarchy-guided contrastive learning to train a hierarchy-aware incident encoder and predicts fault patterns with enhanced incident representations. We evaluate FaultProfIT using the production incidents from CloudA. The results demonstrate that FaultProfIT outperforms state-of-the-art methods. Our ablation study and analysis also verify the effectiveness of hierarchy-guided contrastive learning. Additionally, we have deployed FaultProfIT at CloudA for six months. To date, FaultProfIT has analyzed 10,000+ incidents from 30+ cloud services, successfully revealing several fault trends that have informed system improvements.
Internal Cross-layer Gradients for Extending Homogeneity to Heterogeneity in Federated Learning
Aug 22, 2023

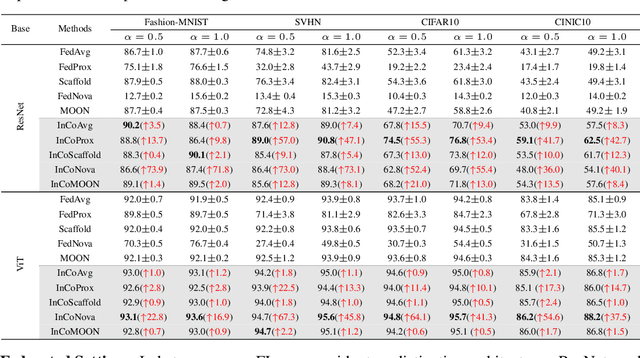

Federated learning (FL) inevitably confronts the challenge of system heterogeneity in practical scenarios. To enhance the capabilities of most model-homogeneous FL methods in handling system heterogeneity, we propose a training scheme that can extend their capabilities to cope with this challenge. In this paper, we commence our study with a detailed exploration of homogeneous and heterogeneous FL settings and discover three key observations: (1) a positive correlation between client performance and layer similarities, (2) higher similarities in the shallow layers in contrast to the deep layers, and (3) the smoother gradients distributions indicate the higher layer similarities. Building upon these observations, we propose InCo Aggregation that leverags internal cross-layer gradients, a mixture of gradients from shallow and deep layers within a server model, to augment the similarity in the deep layers without requiring additional communication between clients. Furthermore, our methods can be tailored to accommodate model-homogeneous FL methods such as FedAvg, FedProx, FedNova, Scaffold, and MOON, to expand their capabilities to handle the system heterogeneity. Copious experimental results validate the effectiveness of InCo Aggregation, spotlighting internal cross-layer gradients as a promising avenue to enhance the performance in heterogenous FL.
Scalable and Adaptive Log-based Anomaly Detection with Expert in the Loop
Jun 08, 2023System logs play a critical role in maintaining the reliability of software systems. Fruitful studies have explored automatic log-based anomaly detection and achieved notable accuracy on benchmark datasets. However, when applied to large-scale cloud systems, these solutions face limitations due to high resource consumption and lack of adaptability to evolving logs. In this paper, we present an accurate, lightweight, and adaptive log-based anomaly detection framework, referred to as SeaLog. Our method introduces a Trie-based Detection Agent (TDA) that employs a lightweight, dynamically-growing trie structure for real-time anomaly detection. To enhance TDA's accuracy in response to evolving log data, we enable it to receive feedback from experts. Interestingly, our findings suggest that contemporary large language models, such as ChatGPT, can provide feedback with a level of consistency comparable to human experts, which can potentially reduce manual verification efforts. We extensively evaluate SeaLog on two public datasets and an industrial dataset. The results show that SeaLog outperforms all baseline methods in terms of effectiveness, runs 2X to 10X faster and only consumes 5% to 41% of the memory resource.
FedIN: Federated Intermediate Layers Learning for Model Heterogeneity
Apr 12, 2023
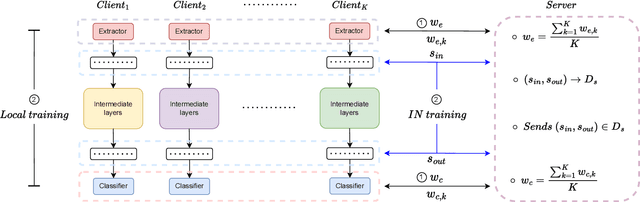


Federated learning (FL) facilitates edge devices to cooperatively train a global shared model while maintaining the training data locally and privately. However, a common but impractical assumption in FL is that the participating edge devices possess the same required resources and share identical global model architecture. In this study, we propose a novel FL method called Federated Intermediate Layers Learning (FedIN), supporting heterogeneous models without utilizing any public dataset. The training models in FedIN are divided into three parts, including an extractor, the intermediate layers, and a classifier. The model architectures of the extractor and classifier are the same in all devices to maintain the consistency of the intermediate layer features, while the architectures of the intermediate layers can vary for heterogeneous devices according to their resource capacities. To exploit the knowledge from features, we propose IN training, training the intermediate layers in line with the features from other clients. Additionally, we formulate and solve a convex optimization problem to mitigate the gradient divergence problem induced by the conflicts between the IN training and the local training. The experiment results show that FedIN achieves the best performance in the heterogeneous model environment compared with the state-of-the-art algorithms. Furthermore, our ablation study demonstrates the effectiveness of IN training and the solution to the convex optimization problem.