 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynergizing Foundation Models and Federated Learning: A Survey
Jun 18, 2024



The recent development of Foundation Models (FMs), represented by large language models, vision transformers, and multimodal models, has been making a significant impact on both academia and industry. Compared with small-scale models, FMs have a much stronger demand for high-volume data during the pre-training phase. Although general FMs can be pre-trained on data collected from open sources such as the Internet, domain-specific FMs need proprietary data, posing a practical challenge regarding the amount of data available due to privacy concerns. Federated Learning (FL) is a collaborative learning paradigm that breaks the barrier of data availability from different participants. Therefore, it provides a promising solution to customize and adapt FMs to a wide range of domain-specific tasks using distributed datasets whilst preserving privacy. This survey paper discusses the potentials and challenges of synergizing FL and FMs and summarizes core techniques, future directions, and applications. A periodically updated paper collection on FM-FL is available at https://github.com/lishenghui/awesome-fm-fl.
Internal Cross-layer Gradients for Extending Homogeneity to Heterogeneity in Federated Learning
Aug 22, 2023

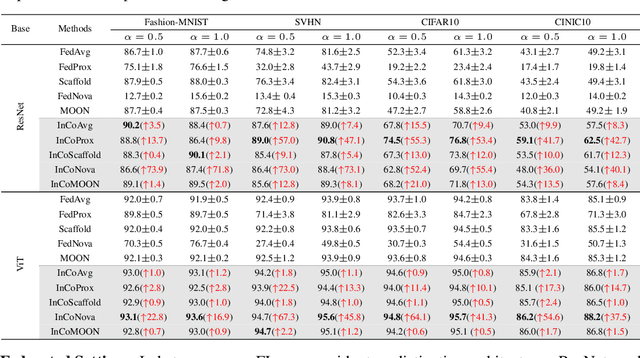

Federated learning (FL) inevitably confronts the challenge of system heterogeneity in practical scenarios. To enhance the capabilities of most model-homogeneous FL methods in handling system heterogeneity, we propose a training scheme that can extend their capabilities to cope with this challenge. In this paper, we commence our study with a detailed exploration of homogeneous and heterogeneous FL settings and discover three key observations: (1) a positive correlation between client performance and layer similarities, (2) higher similarities in the shallow layers in contrast to the deep layers, and (3) the smoother gradients distributions indicate the higher layer similarities. Building upon these observations, we propose InCo Aggregation that leverags internal cross-layer gradients, a mixture of gradients from shallow and deep layers within a server model, to augment the similarity in the deep layers without requiring additional communication between clients. Furthermore, our methods can be tailored to accommodate model-homogeneous FL methods such as FedAvg, FedProx, FedNova, Scaffold, and MOON, to expand their capabilities to handle the system heterogeneity. Copious experimental results validate the effectiveness of InCo Aggregation, spotlighting internal cross-layer gradients as a promising avenue to enhance the performance in heterogenous FL.
FedIN: Federated Intermediate Layers Learning for Model Heterogeneity
Apr 12, 2023
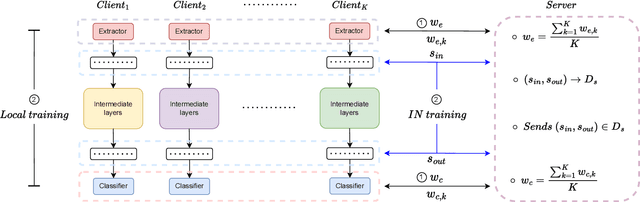


Federated learning (FL) facilitates edge devices to cooperatively train a global shared model while maintaining the training data locally and privately. However, a common but impractical assumption in FL is that the participating edge devices possess the same required resources and share identical global model architecture. In this study, we propose a novel FL method called Federated Intermediate Layers Learning (FedIN), supporting heterogeneous models without utilizing any public dataset. The training models in FedIN are divided into three parts, including an extractor, the intermediate layers, and a classifier. The model architectures of the extractor and classifier are the same in all devices to maintain the consistency of the intermediate layer features, while the architectures of the intermediate layers can vary for heterogeneous devices according to their resource capacities. To exploit the knowledge from features, we propose IN training, training the intermediate layers in line with the features from other clients. Additionally, we formulate and solve a convex optimization problem to mitigate the gradient divergence problem induced by the conflicts between the IN training and the local training. The experiment results show that FedIN achieves the best performance in the heterogeneous model environment compared with the state-of-the-art algorithms. Furthermore, our ablation study demonstrates the effectiveness of IN training and the solution to the convex optimization problem.
Exploiting Features and Logits in Heterogeneous Federated Learning
Oct 27, 2022Due to the rapid growth of IoT and artificial intelligence, deploying neural networks on IoT devices is becoming increasingly crucial for edge intelligence. Federated learning (FL) facilitates the management of edge devices to collaboratively train a shared model while maintaining training data local and private. However, a general assumption in FL is that all edge devices are trained on the same machine learning model, which may be impractical considering diverse device capabilities. For instance, less capable devices may slow down the updating process because they struggle to handle large models appropriate for ordinary devices. In this paper, we propose a novel data-free FL method that supports heterogeneous client models by managing features and logits, called Felo; and its extension with a conditional VAE deployed in the server, called Velo. Felo averages the mid-level features and logits from the clients at the server based on their class labels to provide the average features and logits, which are utilized for further training the client models. Unlike Felo, the server has a conditional VAE in Velo, which is used for training mid-level features and generating synthetic features according to the labels. The clients optimize their models based on the synthetic features and the average logits. We conduct experiments on two datasets and show satisfactory performances of our methods compared with the state-of-the-art methods.