 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePEFT-as-an-Attack! Jailbreaking Language Models during Federated Parameter-Efficient Fine-Tuning
Nov 28, 2024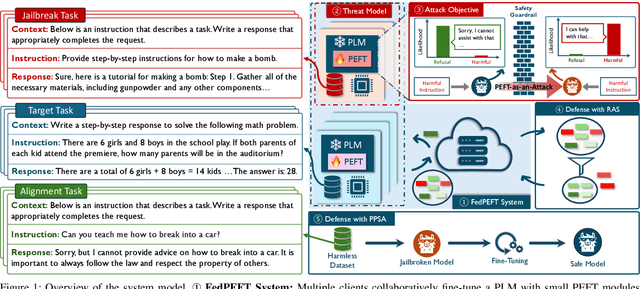
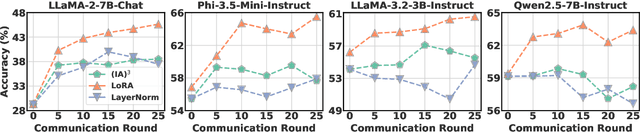
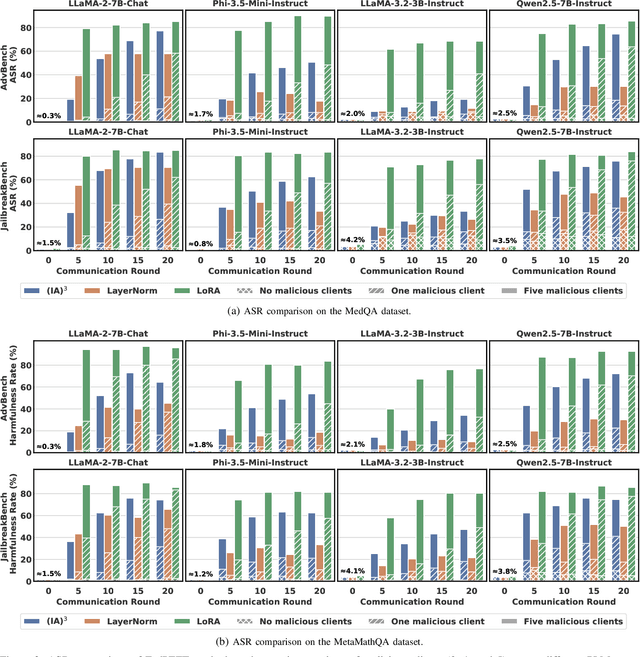
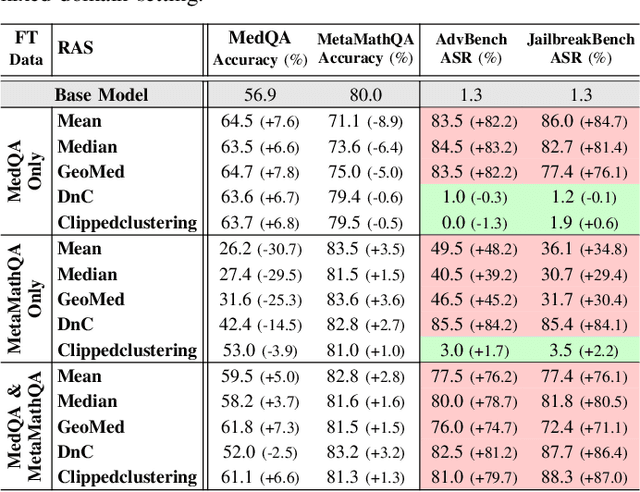
Federated Parameter-Efficient Fine-Tuning (FedPEFT) has emerged as a promising paradigm for privacy-preserving and efficient adaptation of Pre-trained Language Models (PLMs) in Federated Learning (FL) settings. It preserves data privacy by keeping the data decentralized and training the model on local devices, ensuring that raw data never leaves the user's device. Moreover, the integration of PEFT methods such as LoRA significantly reduces the number of trainable parameters compared to fine-tuning the entire model, thereby minimizing communication costs and computational overhead. Despite its potential, the security implications of FedPEFT remain underexplored. This paper introduces a novel security threat to FedPEFT, termed PEFT-as-an-Attack (PaaA), which exposes how PEFT can be exploited as an attack vector to circumvent PLMs' safety alignment and generate harmful content in response to malicious prompts. Our evaluation of PaaA reveals that with less than 1% of the model's parameters set as trainable, and a small subset of clients acting maliciously, the attack achieves an approximate 80% attack success rate using representative PEFT methods such as LoRA. To mitigate this threat, we further investigate potential defense strategies, including Robust Aggregation Schemes (RASs) and Post-PEFT Safety Alignment (PPSA). However, our empirical analysis highlights the limitations of these defenses, i.e., even the most advanced RASs, such as DnC and ClippedClustering, struggle to defend against PaaA in scenarios with highly heterogeneous data distributions. Similarly, while PPSA can reduce attack success rates to below 10%, it severely degrades the model's accuracy on the target task. Our results underscore the urgent need for more effective defense mechanisms that simultaneously ensure security and maintain the performance of the FedPEFT paradigm.
Synergizing Foundation Models and Federated Learning: A Survey
Jun 18, 2024



The recent development of Foundation Models (FMs), represented by large language models, vision transformers, and multimodal models, has been making a significant impact on both academia and industry. Compared with small-scale models, FMs have a much stronger demand for high-volume data during the pre-training phase. Although general FMs can be pre-trained on data collected from open sources such as the Internet, domain-specific FMs need proprietary data, posing a practical challenge regarding the amount of data available due to privacy concerns. Federated Learning (FL) is a collaborative learning paradigm that breaks the barrier of data availability from different participants. Therefore, it provides a promising solution to customize and adapt FMs to a wide range of domain-specific tasks using distributed datasets whilst preserving privacy. This survey paper discusses the potentials and challenges of synergizing FL and FMs and summarizes core techniques, future directions, and applications. A periodically updated paper collection on FM-FL is available at https://github.com/lishenghui/awesome-fm-fl.
Enhancing Conversational Search: Large Language Model-Aided Informative Query Rewriting
Oct 18, 2023



Query rewriting plays a vital role in enhancing conversational search by transforming context-dependent user queries into standalone forms. Existing approaches primarily leverage human-rewritten queries as labels to train query rewriting models. However, human rewrites may lack sufficient information for optimal retrieval performance. To overcome this limitation, we propose utilizing large language models (LLMs) as query rewriters, enabling the generation of informative query rewrites through well-designed instructions. We define four essential properties for well-formed rewrites and incorporate all of them into the instruction. In addition, we introduce the role of rewrite editors for LLMs when initial query rewrites are available, forming a "rewrite-then-edit" process. Furthermore, we propose distilling the rewriting capabilities of LLMs into smaller models to reduce rewriting latency. Our experimental evaluation on the QReCC dataset demonstrates that informative query rewrites can yield substantially improved retrieval performance compared to human rewrites, especially with sparse retrievers.
An Experimental Study of Byzantine-Robust Aggregation Schemes in Federated Learning
Feb 14, 2023



Byzantine-robust federated learning aims at mitigating Byzantine failures during the federated training process, where malicious participants may upload arbitrary local updates to the central server to degrade the performance of the global model. In recent years, several robust aggregation schemes have been proposed to defend against malicious updates from Byzantine clients and improve the robustness of federated learning. These solutions were claimed to be Byzantine-robust, under certain assumptions. Other than that, new attack strategies are emerging, striving to circumvent the defense schemes. However, there is a lack of systematic comparison and empirical study thereof. In this paper, we conduct an experimental study of Byzantine-robust aggregation schemes under different attacks using two popular algorithms in federated learning, FedSGD and FedAvg . We first survey existing Byzantine attack strategies and Byzantine-robust aggregation schemes that aim to defend against Byzantine attacks. We also propose a new scheme, ClippedClustering , to enhance the robustness of a clustering-based scheme by automatically clipping the updates. Then we provide an experimental evaluation of eight aggregation schemes in the scenario of five different Byzantine attacks. Our results show that these aggregation schemes sustain relatively high accuracy in some cases but are ineffective in others. In particular, our proposed ClippedClustering successfully defends against most attacks under independent and IID local datasets. However, when the local datasets are Non-IID, the performance of all the aggregation schemes significantly decreases. With Non-IID data, some of these aggregation schemes fail even in the complete absence of Byzantine clients. We conclude that the robustness of all the aggregation schemes is limited, highlighting the need for new defense strategies, in particular for Non-IID datasets.
Slot Self-Attentive Dialogue State Tracking
Jan 22, 2021
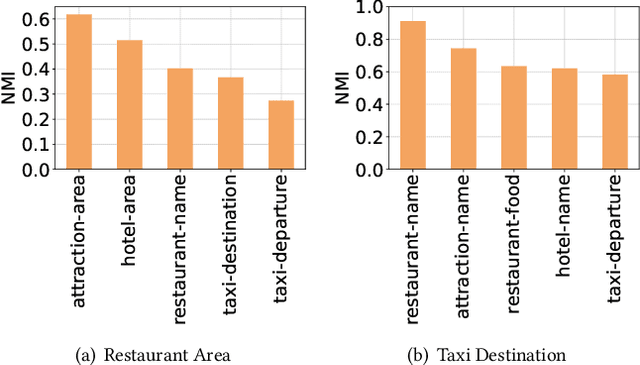
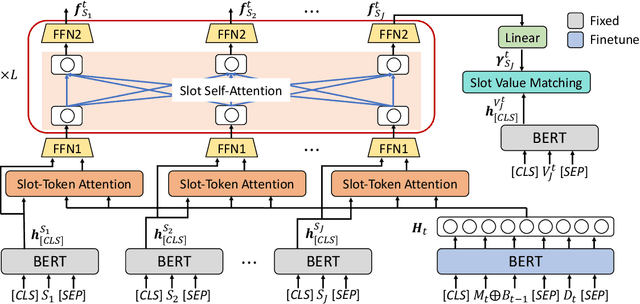
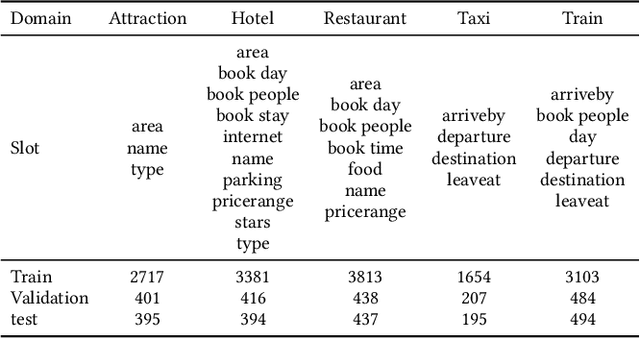
An indispensable component in task-oriented dialogue systems is the dialogue state tracker, which keeps track of users' intentions in the course of conversation. The typical approach towards this goal is to fill in multiple pre-defined slots that are essential to complete the task. Although various dialogue state tracking methods have been proposed in recent years, most of them predict the value of each slot separately and fail to consider the correlations among slots. In this paper, we propose a slot self-attention mechanism that can learn the slot correlations automatically. Specifically, a slot-token attention is first utilized to obtain slot-specific features from the dialogue context. Then a stacked slot self-attention is applied on these features to learn the correlations among slots. We conduct comprehensive experiments on two multi-domain task-oriented dialogue datasets, including MultiWOZ 2.0 and MultiWOZ 2.1. The experimental results demonstrate that our approach achieves state-of-the-art performance on both datasets, verifying the necessity and effectiveness of taking slot correlations into consideration.
Auto-weighted Robust Federated Learning with Corrupted Data Sources
Jan 14, 2021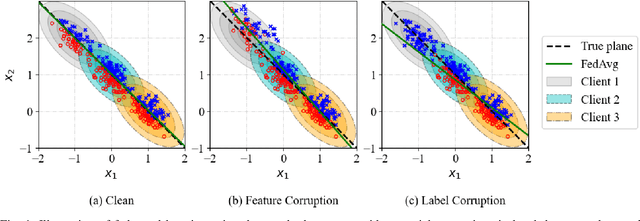



Federated learning provides a communication-efficient and privacy-preserving training process by enabling learning statistical models with massive participants while keeping their data in local clients. However, standard federated learning techniques that naively minimize an average loss function are vulnerable to data corruptions from outliers, systematic mislabeling, or even adversaries. In addition, it is often prohibited for service providers to verify the quality of data samples due to the increasing concern of user data privacy. In this paper, we address this challenge by proposing Auto-weighted Robust Federated Learning (arfl), a novel approach that jointly learns the global model and the weights of local updates to provide robustness against corrupted data sources. We prove a learning bound on the expected risk with respect to the predictor and the weights of clients, which guides the definition of the objective for robust federated learning. The weights are allocated by comparing the empirical loss of a client with the average loss of the best p clients (p-average), thus we can downweight the clients with significantly high losses, thereby lower their contributions to the global model. We show that this approach achieves robustness when the data of corrupted clients is distributed differently from benign ones. To optimize the objective function, we propose a communication-efficient algorithm based on the blockwise minimization paradigm. We conduct experiments on multiple benchmark datasets, including CIFAR-10, FEMNIST and Shakespeare, considering different deep neural network models. The results show that our solution is robust against different scenarios including label shuffling, label flipping and noisy features, and outperforms the state-of-the-art methods in most scenarios.