 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNLGCL: Naturally Existing Neighbor Layers Graph Contrastive Learning for Recommendation
Jul 10, 2025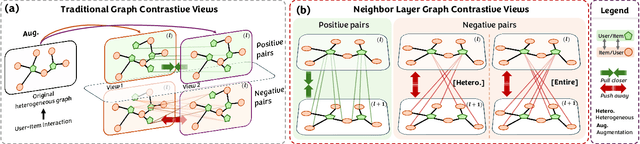
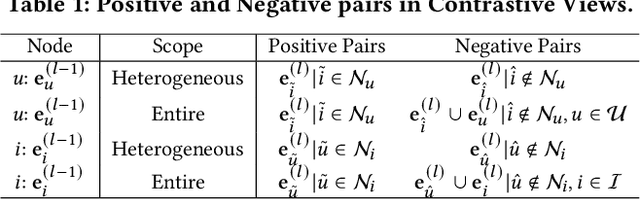
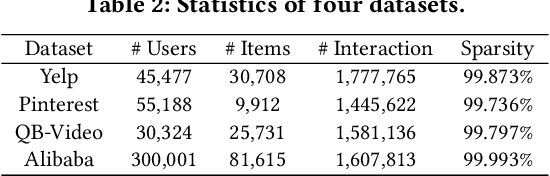
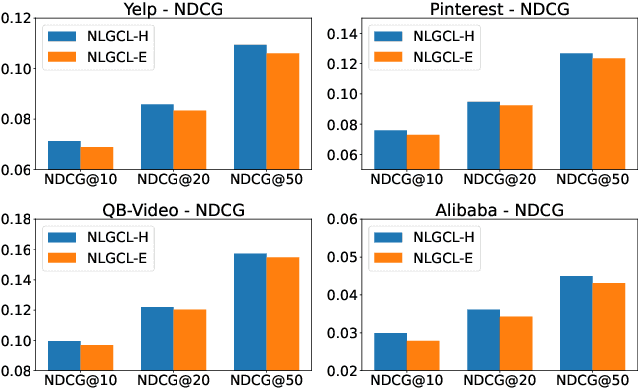
Graph Neural Networks (GNNs) are widely used in collaborative filtering to capture high-order user-item relationships. To address the data sparsity problem in recommendation systems, Graph Contrastive Learning (GCL) has emerged as a promising paradigm that maximizes mutual information between contrastive views. However, existing GCL methods rely on augmentation techniques that introduce semantically irrelevant noise and incur significant computational and storage costs, limiting effectiveness and efficiency. To overcome these challenges, we propose NLGCL, a novel contrastive learning framework that leverages naturally contrastive views between neighbor layers within GNNs. By treating each node and its neighbors in the next layer as positive pairs, and other nodes as negatives, NLGCL avoids augmentation-based noise while preserving semantic relevance. This paradigm eliminates costly view construction and storage, making it computationally efficient and practical for real-world scenarios. Extensive experiments on four public datasets demonstrate that NLGCL outperforms state-of-the-art baselines in effectiveness and efficiency.
TACO: Tackling Over-correction in Federated Learning with Tailored Adaptive Correction
Apr 24, 2025Non-independent and identically distributed (Non-IID) data across edge clients have long posed significant challenges to federated learning (FL) training in edge computing environments. Prior works have proposed various methods to mitigate this statistical heterogeneity. While these works can achieve good theoretical performance, in this work we provide the first investigation into a hidden over-correction phenomenon brought by the uniform model correction coefficients across clients adopted by existing methods. Such over-correction could degrade model performance and even cause failures in model convergence. To address this, we propose TACO, a novel algorithm that addresses the non-IID nature of clients' data by implementing fine-grained, client-specific gradient correction and model aggregation, steering local models towards a more accurate global optimum. Moreover, we verify that leading FL algorithms generally have better model accuracy in terms of communication rounds rather than wall-clock time, resulting from their extra computation overhead imposed on clients. To enhance the training efficiency, TACO deploys a lightweight model correction and tailored aggregation approach that requires minimum computation overhead and no extra information beyond the synchronized model parameters. To validate TACO's effectiveness, we present the first FL convergence analysis that reveals the root cause of over-correction. Extensive experiments across various datasets confirm TACO's superior and stable performance in practice.
Can 3D Vision-Language Models Truly Understand Natural Language?
Mar 28, 2024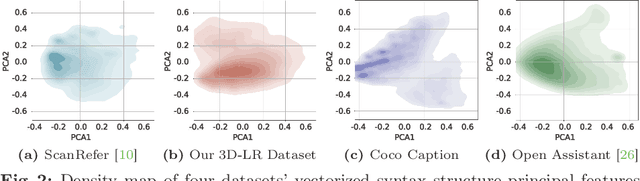
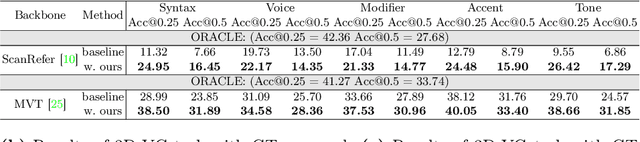
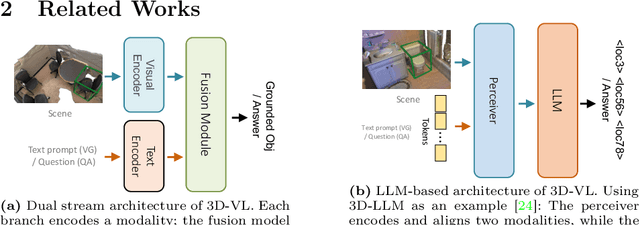
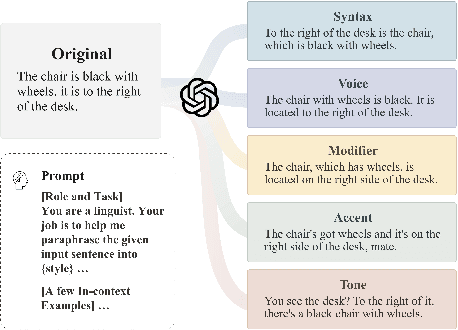
Rapid advancements in 3D vision-language (3D-VL) tasks have opened up new avenues for human interaction with embodied agents or robots using natural language. Despite this progress, we find a notable limitation: existing 3D-VL models exhibit sensitivity to the styles of language input, struggling to understand sentences with the same semantic meaning but written in different variants. This observation raises a critical question: Can 3D vision-language models truly understand natural language? To test the language understandability of 3D-VL models, we first propose a language robustness task for systematically assessing 3D-VL models across various tasks, benchmarking their performance when presented with different language style variants. Importantly, these variants are commonly encountered in applications requiring direct interaction with humans, such as embodied robotics, given the diversity and unpredictability of human language. We propose a 3D Language Robustness Dataset, designed based on the characteristics of human language, to facilitate the systematic study of robustness. Our comprehensive evaluation uncovers a significant drop in the performance of all existing models across various 3D-VL tasks. Even the state-of-the-art 3D-LLM fails to understand some variants of the same sentences. Further in-depth analysis suggests that the existing models have a fragile and biased fusion module, which stems from the low diversity of the existing dataset. Finally, we propose a training-free module driven by LLM, which improves language robustness. Datasets and code will be available at github.
Beyond Finite Data: Towards Data-free Out-of-distribution Generalization via Extrapolation
Mar 11, 2024Out-of-distribution (OOD) generalization is a favorable yet challenging property for deep neural networks. The core challenges lie in the limited availability of source domains that help models learn an invariant representation from the spurious features. Various domain augmentation have been proposed but largely rely on interpolating existing domains and frequently face difficulties in creating truly "novel" domains. Humans, on the other hand, can easily extrapolate novel domains, thus, an intriguing question arises: How can neural networks extrapolate like humans and achieve OOD generalization? We introduce a novel approach to domain extrapolation that leverages reasoning ability and the extensive knowledge encapsulated within large language models (LLMs) to synthesize entirely new domains. Starting with the class of interest, we query the LLMs to extract relevant knowledge for these novel domains. We then bridge the gap between the text-centric knowledge derived from LLMs and the pixel input space of the model using text-to-image generation techniques. By augmenting the training set of domain generalization datasets with high-fidelity, photo-realistic images of these new domains, we achieve significant improvements over all existing methods, as demonstrated in both single and multi-domain generalization across various benchmarks. With the ability to extrapolate any domains for any class, our method has the potential to learn a generalized model for any task without any data. To illustrate, we put forth a much more difficult setting termed, data-free domain generalization, that aims to learn a generalized model in the absence of any collected data. Our empirical findings support the above argument and our methods exhibit commendable performance in this setting, even surpassing the supervised setting by approximately 1-2\% on datasets such as VLCS.
Auto-weighted Robust Federated Learning with Corrupted Data Sources
Jan 14, 2021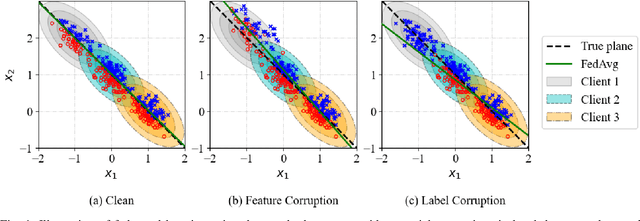



Federated learning provides a communication-efficient and privacy-preserving training process by enabling learning statistical models with massive participants while keeping their data in local clients. However, standard federated learning techniques that naively minimize an average loss function are vulnerable to data corruptions from outliers, systematic mislabeling, or even adversaries. In addition, it is often prohibited for service providers to verify the quality of data samples due to the increasing concern of user data privacy. In this paper, we address this challenge by proposing Auto-weighted Robust Federated Learning (arfl), a novel approach that jointly learns the global model and the weights of local updates to provide robustness against corrupted data sources. We prove a learning bound on the expected risk with respect to the predictor and the weights of clients, which guides the definition of the objective for robust federated learning. The weights are allocated by comparing the empirical loss of a client with the average loss of the best p clients (p-average), thus we can downweight the clients with significantly high losses, thereby lower their contributions to the global model. We show that this approach achieves robustness when the data of corrupted clients is distributed differently from benign ones. To optimize the objective function, we propose a communication-efficient algorithm based on the blockwise minimization paradigm. We conduct experiments on multiple benchmark datasets, including CIFAR-10, FEMNIST and Shakespeare, considering different deep neural network models. The results show that our solution is robust against different scenarios including label shuffling, label flipping and noisy features, and outperforms the state-of-the-art methods in most scenarios.
Emotion Recognition From Gait Analyses: Current Research and Future Directions
Mar 13, 2020



Human gait refers to a daily motion that represents not only mobility, but it can also be used to identify the walker by either human observers or computers. Recent studies reveal that gait even conveys information about the walker's emotion. Individuals in different emotion states may show different gait patterns. The mapping between various emotions and gait patterns provides a new source for automated emotion recognition. Compared to traditional emotion detection biometrics, such as facial expression, speech and physiological parameters, gait is remotely observable, more difficult to imitate, and requires less cooperation from the subject. These advantages make gait a promising source for emotion detection. This article reviews current research on gait-based emotion detection, particularly on how gait parameters can be affected by different emotion states and how the emotion states can be recognized through distinct gait patterns. We focus on the detailed methods and techniques applied in the whole process of emotion recognition: data collection, preprocessing, and classification. At last, we discuss possible future developments of efficient and effective gait-based emotion recognition using the state of the art techniques on intelligent computation and big data.