 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTACO: Tackling Over-correction in Federated Learning with Tailored Adaptive Correction
Apr 24, 2025Non-independent and identically distributed (Non-IID) data across edge clients have long posed significant challenges to federated learning (FL) training in edge computing environments. Prior works have proposed various methods to mitigate this statistical heterogeneity. While these works can achieve good theoretical performance, in this work we provide the first investigation into a hidden over-correction phenomenon brought by the uniform model correction coefficients across clients adopted by existing methods. Such over-correction could degrade model performance and even cause failures in model convergence. To address this, we propose TACO, a novel algorithm that addresses the non-IID nature of clients' data by implementing fine-grained, client-specific gradient correction and model aggregation, steering local models towards a more accurate global optimum. Moreover, we verify that leading FL algorithms generally have better model accuracy in terms of communication rounds rather than wall-clock time, resulting from their extra computation overhead imposed on clients. To enhance the training efficiency, TACO deploys a lightweight model correction and tailored aggregation approach that requires minimum computation overhead and no extra information beyond the synchronized model parameters. To validate TACO's effectiveness, we present the first FL convergence analysis that reveals the root cause of over-correction. Extensive experiments across various datasets confirm TACO's superior and stable performance in practice.
FedMoE-DA: Federated Mixture of Experts via Domain Aware Fine-grained Aggregation
Nov 04, 2024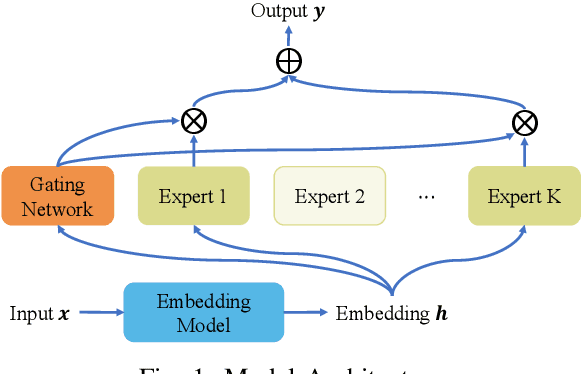
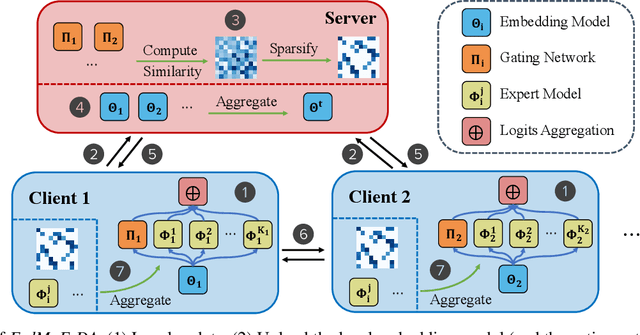
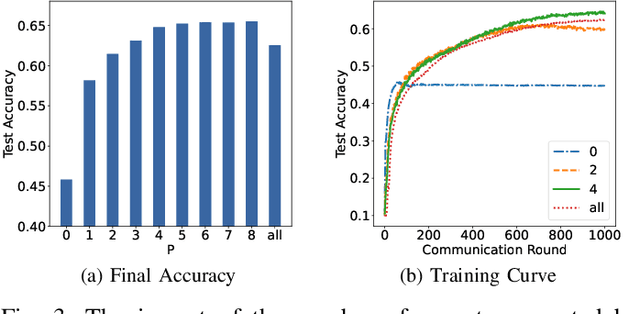
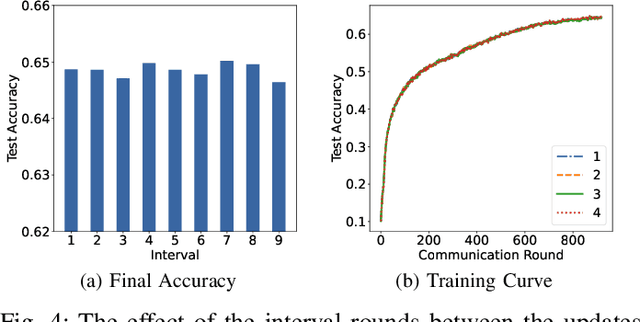
Federated learning (FL) is a collaborative machine learning approach that enables multiple clients to train models without sharing their private data. With the rise of deep learning, large-scale models have garnered significant attention due to their exceptional performance. However, a key challenge in FL is the limitation imposed by clients with constrained computational and communication resources, which hampers the deployment of these large models. The Mixture of Experts (MoE) architecture addresses this challenge with its sparse activation property, which reduces computational workload and communication demands during inference and updates. Additionally, MoE facilitates better personalization by allowing each expert to specialize in different subsets of the data distribution. To alleviate the communication burdens between the server and clients, we propose FedMoE-DA, a new FL model training framework that leverages the MoE architecture and incorporates a novel domain-aware, fine-grained aggregation strategy to enhance the robustness, personalizability, and communication efficiency simultaneously. Specifically, the correlation between both intra-client expert models and inter-client data heterogeneity is exploited. Moreover, we utilize peer-to-peer (P2P) communication between clients for selective expert model synchronization, thus significantly reducing the server-client transmissions. Experiments demonstrate that our FedMoE-DA achieves excellent performance while reducing the communication pressure on the server.
FedReMa: Improving Personalized Federated Learning via Leveraging the Most Relevant Clients
Nov 04, 2024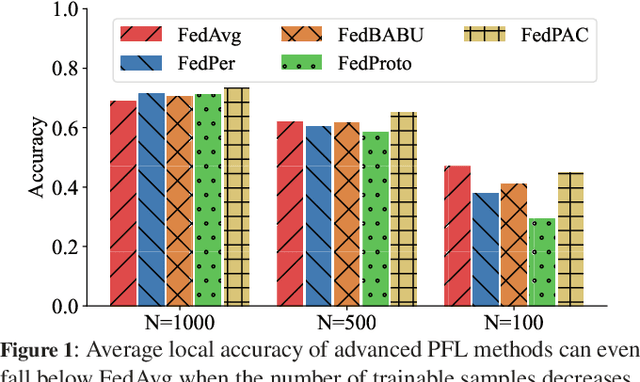
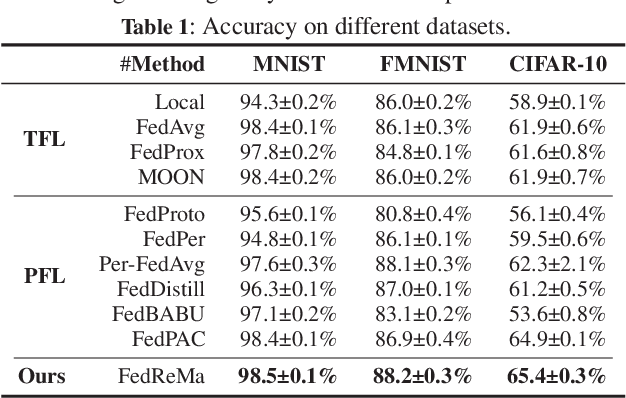
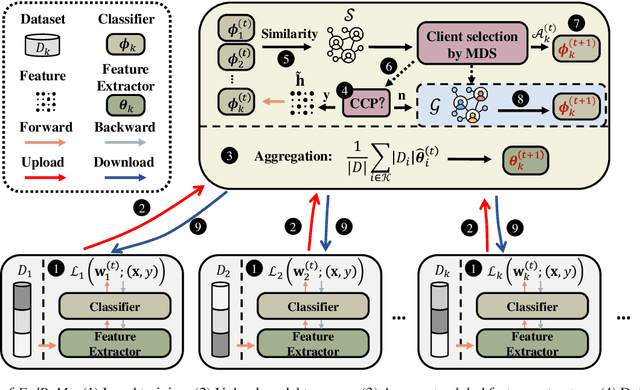
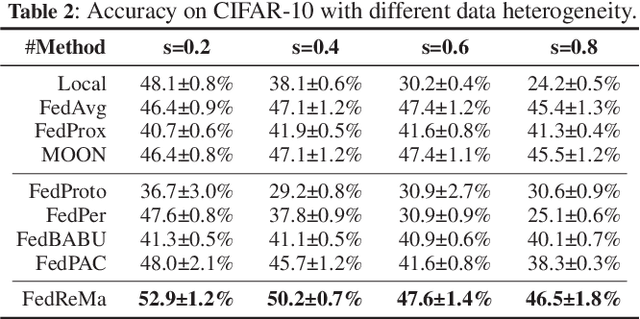
Federated Learning (FL) is a distributed machine learning paradigm that achieves a globally robust model through decentralized computation and periodic model synthesis, primarily focusing on the global model's accuracy over aggregated datasets of all participating clients. Personalized Federated Learning (PFL) instead tailors exclusive models for each client, aiming to enhance the accuracy of clients' individual models on specific local data distributions. Despite of their wide adoption, existing FL and PFL works have yet to comprehensively address the class-imbalance issue, one of the most critical challenges within the realm of data heterogeneity in PFL and FL research. In this paper, we propose FedReMa, an efficient PFL algorithm that can tackle class-imbalance by 1) utilizing an adaptive inter-client co-learning approach to identify and harness different clients' expertise on different data classes throughout various phases of the training process, and 2) employing distinct aggregation methods for clients' feature extractors and classifiers, with the choices informed by the different roles and implications of these model components. Specifically, driven by our experimental findings on inter-client similarity dynamics, we develop critical co-learning period (CCP), wherein we introduce a module named maximum difference segmentation (MDS) to assess and manage task relevance by analyzing the similarities between clients' logits of their classifiers. Outside the CCP, we employ an additional scheme for model aggregation that utilizes historical records of each client's most relevant peers to further enhance the personalization stability. We demonstrate the superiority of our FedReMa in extensive experiments.