 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssoCiAm: A Benchmark for Evaluating Association Thinking while Circumventing Ambiguity
Sep 18, 2025Recent advancements in multimodal large language models (MLLMs) have garnered significant attention, offering a promising pathway toward artificial general intelligence (AGI). Among the essential capabilities required for AGI, creativity has emerged as a critical trait for MLLMs, with association serving as its foundation. Association reflects a model' s ability to think creatively, making it vital to evaluate and understand. While several frameworks have been proposed to assess associative ability, they often overlook the inherent ambiguity in association tasks, which arises from the divergent nature of associations and undermines the reliability of evaluations. To address this issue, we decompose ambiguity into two types-internal ambiguity and external ambiguity-and introduce AssoCiAm, a benchmark designed to evaluate associative ability while circumventing the ambiguity through a hybrid computational method. We then conduct extensive experiments on MLLMs, revealing a strong positive correlation between cognition and association. Additionally, we observe that the presence of ambiguity in the evaluation process causes MLLMs' behavior to become more random-like. Finally, we validate the effectiveness of our method in ensuring more accurate and reliable evaluations. See Project Page for the data and codes.
FedMoE-DA: Federated Mixture of Experts via Domain Aware Fine-grained Aggregation
Nov 04, 2024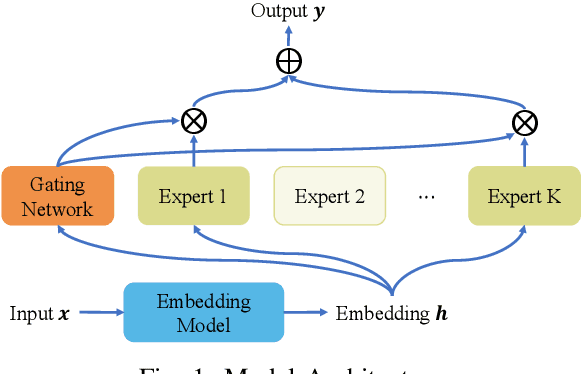
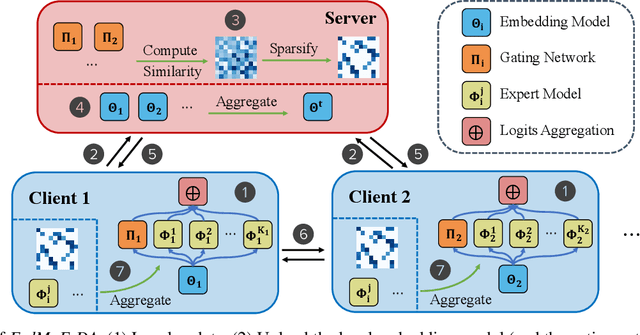
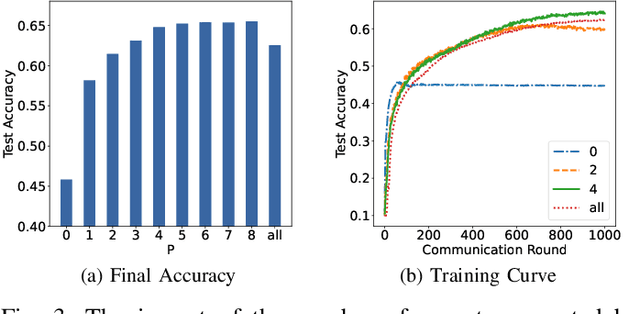
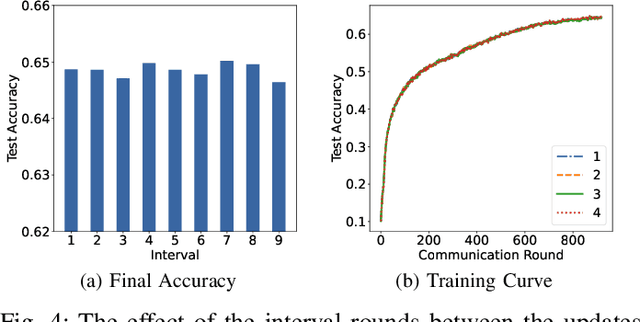
Federated learning (FL) is a collaborative machine learning approach that enables multiple clients to train models without sharing their private data. With the rise of deep learning, large-scale models have garnered significant attention due to their exceptional performance. However, a key challenge in FL is the limitation imposed by clients with constrained computational and communication resources, which hampers the deployment of these large models. The Mixture of Experts (MoE) architecture addresses this challenge with its sparse activation property, which reduces computational workload and communication demands during inference and updates. Additionally, MoE facilitates better personalization by allowing each expert to specialize in different subsets of the data distribution. To alleviate the communication burdens between the server and clients, we propose FedMoE-DA, a new FL model training framework that leverages the MoE architecture and incorporates a novel domain-aware, fine-grained aggregation strategy to enhance the robustness, personalizability, and communication efficiency simultaneously. Specifically, the correlation between both intra-client expert models and inter-client data heterogeneity is exploited. Moreover, we utilize peer-to-peer (P2P) communication between clients for selective expert model synchronization, thus significantly reducing the server-client transmissions. Experiments demonstrate that our FedMoE-DA achieves excellent performance while reducing the communication pressure on the server.