 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCIDER: A Causal Cure for Brand-Obsessed Text-to-Image Models
Sep 19, 2025



Text-to-image (T2I) models exhibit a significant yet under-explored "brand bias", a tendency to generate contents featuring dominant commercial brands from generic prompts, posing ethical and legal risks. We propose CIDER, a novel, model-agnostic framework to mitigate bias at inference-time through prompt refinement to avoid costly retraining. CIDER uses a lightweight detector to identify branded content and a Vision-Language Model (VLM) to generate stylistically divergent alternatives. We introduce the Brand Neutrality Score (BNS) to quantify this issue and perform extensive experiments on leading T2I models. Results show CIDER significantly reduces both explicit and implicit biases while maintaining image quality and aesthetic appeal. Our work offers a practical solution for more original and equitable content, contributing to the development of trustworthy generative AI.
UPRPRC: Unified Pipeline for Reproducing Parallel Resources -- Corpus from the United Nations
Sep 19, 2025The quality and accessibility of multilingual datasets are crucial for advancing machine translation. However, previous corpora built from United Nations documents have suffered from issues such as opaque process, difficulty of reproduction, and limited scale. To address these challenges, we introduce a complete end-to-end solution, from data acquisition via web scraping to text alignment. The entire process is fully reproducible, with a minimalist single-machine example and optional distributed computing steps for scalability. At its core, we propose a new Graph-Aided Paragraph Alignment (GAPA) algorithm for efficient and flexible paragraph-level alignment. The resulting corpus contains over 713 million English tokens, more than doubling the scale of prior work. To the best of our knowledge, this represents the largest publicly available parallel corpus composed entirely of human-translated, non-AI-generated content. Our code and corpus are accessible under the MIT License.
AssoCiAm: A Benchmark for Evaluating Association Thinking while Circumventing Ambiguity
Sep 18, 2025Recent advancements in multimodal large language models (MLLMs) have garnered significant attention, offering a promising pathway toward artificial general intelligence (AGI). Among the essential capabilities required for AGI, creativity has emerged as a critical trait for MLLMs, with association serving as its foundation. Association reflects a model' s ability to think creatively, making it vital to evaluate and understand. While several frameworks have been proposed to assess associative ability, they often overlook the inherent ambiguity in association tasks, which arises from the divergent nature of associations and undermines the reliability of evaluations. To address this issue, we decompose ambiguity into two types-internal ambiguity and external ambiguity-and introduce AssoCiAm, a benchmark designed to evaluate associative ability while circumventing the ambiguity through a hybrid computational method. We then conduct extensive experiments on MLLMs, revealing a strong positive correlation between cognition and association. Additionally, we observe that the presence of ambiguity in the evaluation process causes MLLMs' behavior to become more random-like. Finally, we validate the effectiveness of our method in ensuring more accurate and reliable evaluations. See Project Page for the data and codes.
Boundary-Driven Table-Filling with Cross-Granularity Contrastive Learning for Aspect Sentiment Triplet Extraction
Feb 04, 2025



The Aspect Sentiment Triplet Extraction (ASTE) task aims to extract aspect terms, opinion terms, and their corresponding sentiment polarity from a given sentence. It remains one of the most prominent subtasks in fine-grained sentiment analysis. Most existing approaches frame triplet extraction as a 2D table-filling process in an end-to-end manner, focusing primarily on word-level interactions while often overlooking sentence-level representations. This limitation hampers the model's ability to capture global contextual information, particularly when dealing with multi-word aspect and opinion terms in complex sentences. To address these issues, we propose boundary-driven table-filling with cross-granularity contrastive learning (BTF-CCL) to enhance the semantic consistency between sentence-level representations and word-level representations. By constructing positive and negative sample pairs, the model is forced to learn the associations at both the sentence level and the word level. Additionally, a multi-scale, multi-granularity convolutional method is proposed to capture rich semantic information better. Our approach can capture sentence-level contextual information more effectively while maintaining sensitivity to local details. Experimental results show that the proposed method achieves state-of-the-art performance on public benchmarks according to the F1 score.
MoExtend: Tuning New Experts for Modality and Task Extension
Aug 07, 2024



Large language models (LLMs) excel in various tasks but are primarily trained on text data, limiting their application scope. Expanding LLM capabilities to include vision-language understanding is vital, yet training them on multimodal data from scratch is challenging and costly. Existing instruction tuning methods, e.g., LLAVA, often connects a pretrained CLIP vision encoder and LLMs via fully fine-tuning LLMs to bridge the modality gap. However, full fine-tuning is plagued by catastrophic forgetting, i.e., forgetting previous knowledge, and high training costs particularly in the era of increasing tasks and modalities. To solve this issue, we introduce MoExtend, an effective framework designed to streamline the modality adaptation and extension of Mixture-of-Experts (MoE) models. MoExtend seamlessly integrates new experts into pre-trained MoE models, endowing them with novel knowledge without the need to tune pretrained models such as MoE and vision encoders. This approach enables rapid adaptation and extension to new modal data or tasks, effectively addressing the challenge of accommodating new modalities within LLMs. Furthermore, MoExtend avoids tuning pretrained models, thus mitigating the risk of catastrophic forgetting. Experimental results demonstrate the efficacy and efficiency of MoExtend in enhancing the multimodal capabilities of LLMs, contributing to advancements in multimodal AI research. Code: https://github.com/zhongshsh/MoExtend.
Mirror Gradient: Towards Robust Multimodal Recommender Systems via Exploring Flat Local Minima
Feb 17, 2024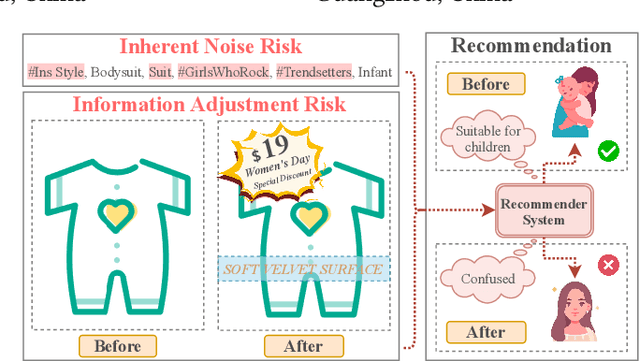
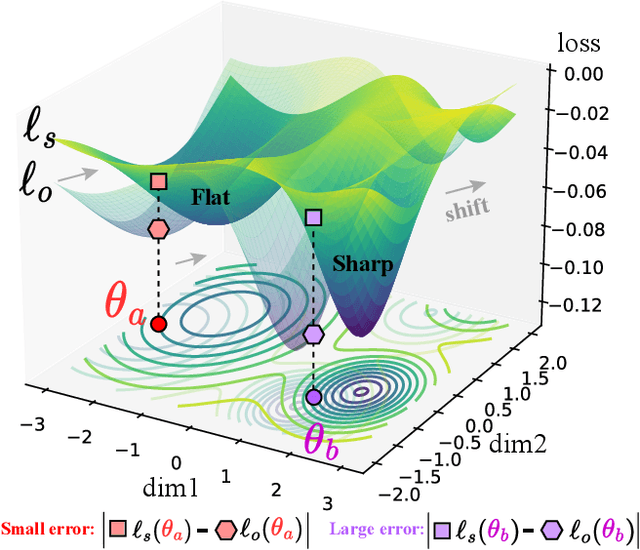
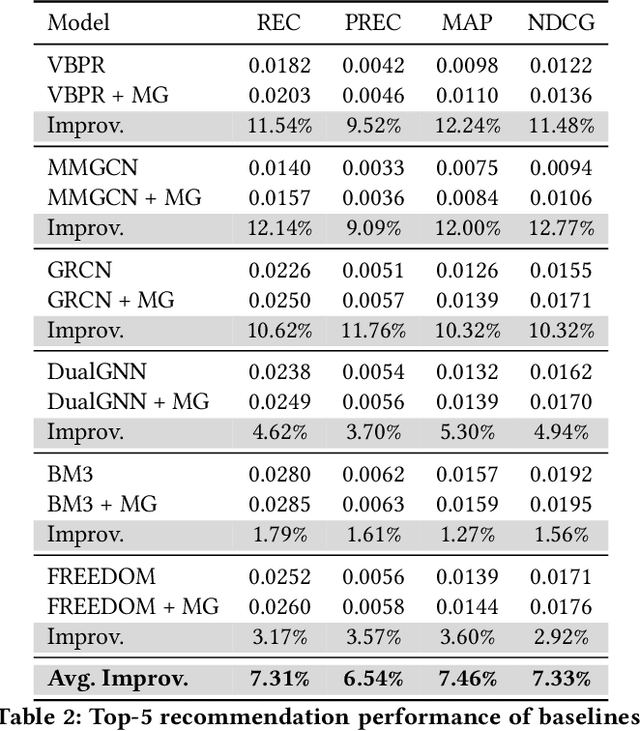
Multimodal recommender systems utilize various types of information to model user preferences and item features, helping users discover items aligned with their interests. The integration of multimodal information mitigates the inherent challenges in recommender systems, e.g., the data sparsity problem and cold-start issues. However, it simultaneously magnifies certain risks from multimodal information inputs, such as information adjustment risk and inherent noise risk. These risks pose crucial challenges to the robustness of recommendation models. In this paper, we analyze multimodal recommender systems from the novel perspective of flat local minima and propose a concise yet effective gradient strategy called Mirror Gradient (MG). This strategy can implicitly enhance the model's robustness during the optimization process, mitigating instability risks arising from multimodal information inputs. We also provide strong theoretical evidence and conduct extensive empirical experiments to show the superiority of MG across various multimodal recommendation models and benchmarks. Furthermore, we find that the proposed MG can complement existing robust training methods and be easily extended to diverse advanced recommendation models, making it a promising new and fundamental paradigm for training multimodal recommender systems. The code is released at https://github.com/Qrange-group/Mirror-Gradient.
Let's Think Outside the Box: Exploring Leap-of-Thought in Large Language Models with Creative Humor Generation
Dec 06, 2023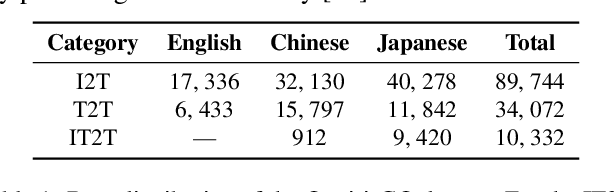
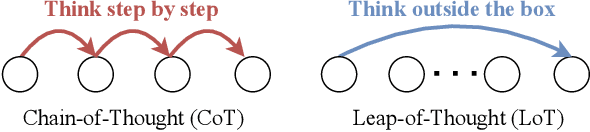
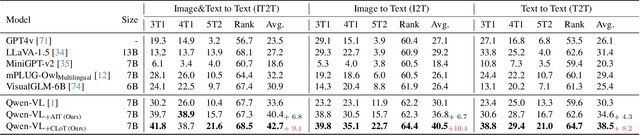
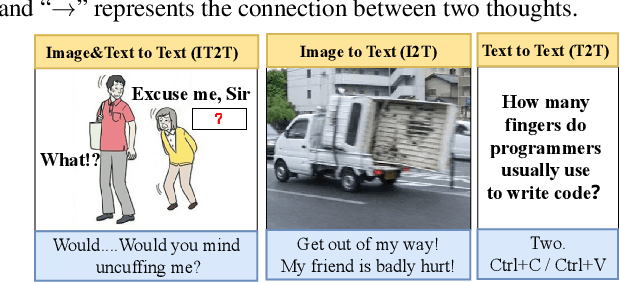
Chain-of-Thought (CoT) guides large language models (LLMs) to reason step-by-step, and can motivate their logical reasoning ability. While effective for logical tasks, CoT is not conducive to creative problem-solving which often requires out-of-box thoughts and is crucial for innovation advancements. In this paper, we explore the Leap-of-Thought (LoT) abilities within LLMs -- a non-sequential, creative paradigm involving strong associations and knowledge leaps. To this end, we study LLMs on the popular Oogiri game which needs participants to have good creativity and strong associative thinking for responding unexpectedly and humorously to the given image, text, or both, and thus is suitable for LoT study. Then to investigate LLMs' LoT ability in the Oogiri game, we first build a multimodal and multilingual Oogiri-GO dataset which contains over 130,000 samples from the Oogiri game, and observe the insufficient LoT ability or failures of most existing LLMs on the Oogiri game. Accordingly, we introduce a creative Leap-of-Thought (CLoT) paradigm to improve LLM's LoT ability. CLoT first formulates the Oogiri-GO dataset into LoT-oriented instruction tuning data to train pretrained LLM for achieving certain LoT humor generation and discrimination abilities. Then CLoT designs an explorative self-refinement that encourages the LLM to generate more creative LoT data via exploring parallels between seemingly unrelated concepts and selects high-quality data to train itself for self-refinement. CLoT not only excels in humor generation in the Oogiri game but also boosts creative abilities in various tasks like cloud guessing game and divergent association task. These findings advance our understanding and offer a pathway to improve LLMs' creative capacities for innovative applications across domains. The dataset, code, and models will be released online. https://zhongshsh.github.io/CLoT/.
SUR-adapter: Enhancing Text-to-Image Pre-trained Diffusion Models with Large Language Models
May 12, 2023

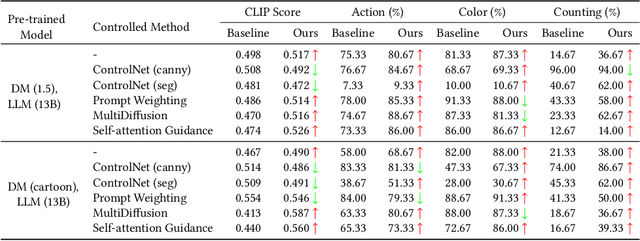

Diffusion models, which have emerged to become popular text-to-image generation models, can produce high-quality and content-rich images guided by textual prompts. However, there are limitations to semantic understanding and commonsense reasoning in existing models when the input prompts are concise narrative, resulting in low-quality image generation. To improve the capacities for narrative prompts, we propose a simple-yet-effective parameter-efficient fine-tuning approach called the Semantic Understanding and Reasoning adapter (SUR-adapter) for pre-trained diffusion models. To reach this goal, we first collect and annotate a new dataset SURD which consists of more than 57,000 semantically corrected multi-modal samples. Each sample contains a simple narrative prompt, a complex keyword-based prompt, and a high-quality image. Then, we align the semantic representation of narrative prompts to the complex prompts and transfer knowledge of large language models (LLMs) to our SUR-adapter via knowledge distillation so that it can acquire the powerful semantic understanding and reasoning capabilities to build a high-quality textual semantic representation for text-to-image generation. We conduct experiments by integrating multiple LLMs and popular pre-trained diffusion models to show the effectiveness of our approach in enabling diffusion models to understand and reason concise natural language without image quality degradation. Our approach can make text-to-image diffusion models easier to use with better user experience, which demonstrates our approach has the potential for further advancing the development of user-friendly text-to-image generation models by bridging the semantic gap between simple narrative prompts and complex keyword-based prompts. The code is released at https://github.com/Qrange-group/SUR-adapter.
LSAS: Lightweight Sub-attention Strategy for Alleviating Attention Bias Problem
May 09, 2023



In computer vision, the performance of deep neural networks (DNNs) is highly related to the feature extraction ability, i.e., the ability to recognize and focus on key pixel regions in an image. However, in this paper, we quantitatively and statistically illustrate that DNNs have a serious attention bias problem on many samples from some popular datasets: (1) Position bias: DNNs fully focus on label-independent regions; (2) Range bias: The focused regions from DNN are not completely contained in the ideal region. Moreover, we find that the existing self-attention modules can alleviate these biases to a certain extent, but the biases are still non-negligible. To further mitigate them, we propose a lightweight sub-attention strategy (LSAS), which utilizes high-order sub-attention modules to improve the original self-attention modules. The effectiveness of LSAS is demonstrated by extensive experiments on widely-used benchmark datasets and popular attention networks. We release our code to help other researchers to reproduce the results of LSAS~\footnote{https://github.com/Qrange-group/LSAS}.
ASR: Attention-alike Structural Re-parameterization
Apr 13, 2023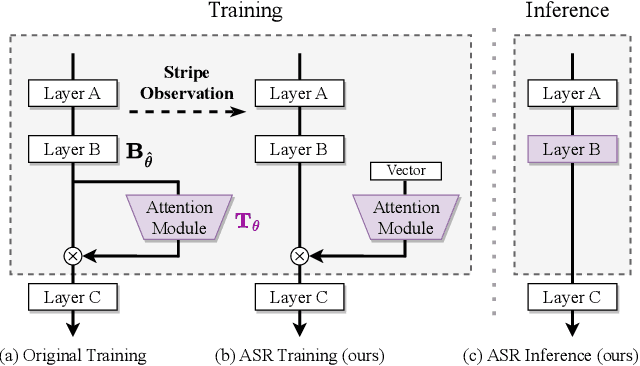
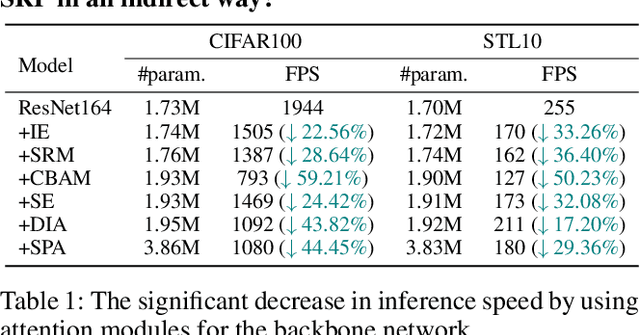
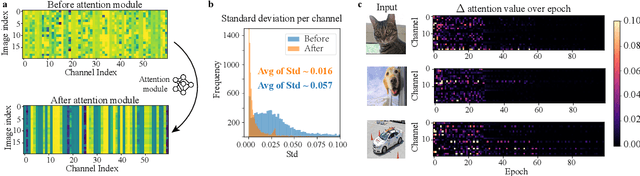
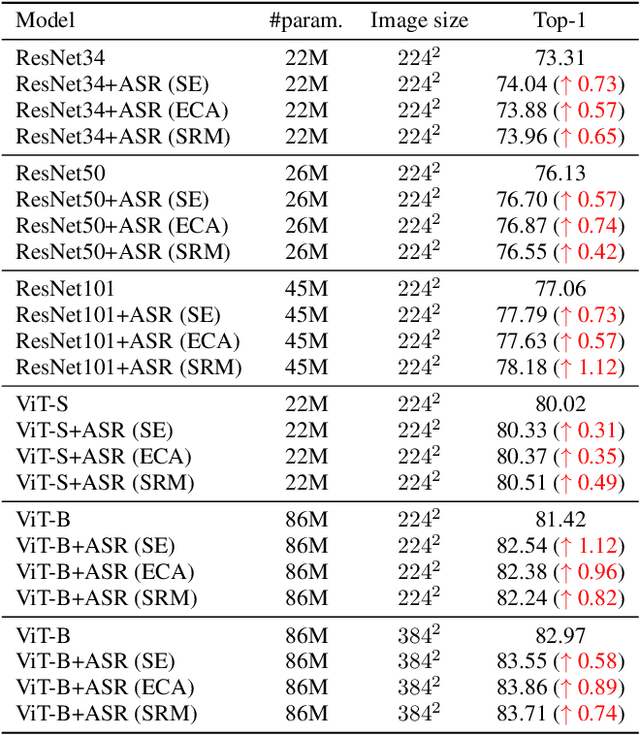
The structural re-parameterization (SRP) technique is a novel deep learning technique that achieves interconversion between different network architectures through equivalent parameter transformations. This technique enables the mitigation of the extra costs for performance improvement during training, such as parameter size and inference time, through these transformations during inference, and therefore SRP has great potential for industrial and practical applications. The existing SRP methods have successfully considered many commonly used architectures, such as normalizations, pooling methods, multi-branch convolution. However, the widely used self-attention modules cannot be directly implemented by SRP due to these modules usually act on the backbone network in a multiplicative manner and the modules' output is input-dependent during inference, which limits the application scenarios of SRP. In this paper, we conduct extensive experiments from a statistical perspective and discover an interesting phenomenon Stripe Observation, which reveals that channel attention values quickly approach some constant vectors during training. This observation inspires us to propose a simple-yet-effective attention-alike structural re-parameterization (ASR) that allows us to achieve SRP for a given network while enjoying the effectiveness of the self-attention mechanism. Extensive experiments conducted on several standard benchmarks demonstrate the effectiveness of ASR in generally improving the performance of existing backbone networks, self-attention modules, and SRP methods without any elaborated model crafting. We also analyze the limitations and provide experimental or theoretical evidence for the strong robustness of the proposed ASR.