 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCertifying the Right to Be Forgotten: Primal-Dual Optimization for Sample and Label Unlearning in Vertical Federated Learning
Dec 29, 2025Federated unlearning has become an attractive approach to address privacy concerns in collaborative machine learning, for situations when sensitive data is remembered by AI models during the machine learning process. It enables the removal of specific data influences from trained models, aligning with the growing emphasis on the "right to be forgotten." While extensively studied in horizontal federated learning, unlearning in vertical federated learning (VFL) remains challenging due to the distributed feature architecture. VFL unlearning includes sample unlearning that removes specific data points' influence and label unlearning that removes entire classes. Since different parties hold complementary features of the same samples, unlearning tasks require cross-party coordination, creating computational overhead and complexities from feature interdependencies. To address such challenges, we propose FedORA (Federated Optimization for data Removal via primal-dual Algorithm), designed for sample and label unlearning in VFL. FedORA formulates the removal of certain samples or labels as a constrained optimization problem solved using a primal-dual framework. Our approach introduces a new unlearning loss function that promotes classification uncertainty rather than misclassification. An adaptive step size enhances stability, while an asymmetric batch design, considering the prior influence of the remaining data on the model, handles unlearning and retained data differently to efficiently reduce computational costs. We provide theoretical analysis proving that the model difference between FedORA and Train-from-scratch is bounded, establishing guarantees for unlearning effectiveness. Experiments on tabular and image datasets demonstrate that FedORA achieves unlearning effectiveness and utility preservation comparable to Train-from-scratch with reduced computation and communication overhead.
* Published in the IEEE Transactions on Information Forensics and Security
STADI: Fine-Grained Step-Patch Diffusion Parallelism for Heterogeneous GPUs
Sep 05, 2025The escalating adoption of diffusion models for applications such as image generation demands efficient parallel inference techniques to manage their substantial computational cost. However, existing diffusion parallelism inference schemes often underutilize resources in heterogeneous multi-GPU environments, where varying hardware capabilities or background tasks cause workload imbalance. This paper introduces Spatio-Temporal Adaptive Diffusion Inference (STADI), a novel framework to accelerate diffusion model inference in such settings. At its core is a hybrid scheduler that orchestrates fine-grained parallelism across both temporal and spatial dimensions. Temporally, STADI introduces a novel computation-aware step allocator applied after warmup phases, using a least-common-multiple-minimizing quantization technique to reduce denoising steps on slower GPUs and execution synchronization. To further minimize GPU idle periods, STADI executes an elastic patch parallelism mechanism that allocates variably sized image patches to GPUs according to their computational capability, ensuring balanced workload distribution through a complementary spatial mechanism. Extensive experiments on both load-imbalanced and heterogeneous multi-GPU clusters validate STADI's efficacy, demonstrating improved load balancing and mitigation of performance bottlenecks. Compared to patch parallelism, a state-of-the-art diffusion inference framework, our method significantly reduces end-to-end inference latency by up to 45% and significantly improves resource utilization on heterogeneous GPUs.
TACO: Tackling Over-correction in Federated Learning with Tailored Adaptive Correction
Apr 24, 2025Non-independent and identically distributed (Non-IID) data across edge clients have long posed significant challenges to federated learning (FL) training in edge computing environments. Prior works have proposed various methods to mitigate this statistical heterogeneity. While these works can achieve good theoretical performance, in this work we provide the first investigation into a hidden over-correction phenomenon brought by the uniform model correction coefficients across clients adopted by existing methods. Such over-correction could degrade model performance and even cause failures in model convergence. To address this, we propose TACO, a novel algorithm that addresses the non-IID nature of clients' data by implementing fine-grained, client-specific gradient correction and model aggregation, steering local models towards a more accurate global optimum. Moreover, we verify that leading FL algorithms generally have better model accuracy in terms of communication rounds rather than wall-clock time, resulting from their extra computation overhead imposed on clients. To enhance the training efficiency, TACO deploys a lightweight model correction and tailored aggregation approach that requires minimum computation overhead and no extra information beyond the synchronized model parameters. To validate TACO's effectiveness, we present the first FL convergence analysis that reveals the root cause of over-correction. Extensive experiments across various datasets confirm TACO's superior and stable performance in practice.
Online Location Planning for AI-Defined Vehicles: Optimizing Joint Tasks of Order Serving and Spatio-Temporal Heterogeneous Model Fine-Tuning
Feb 06, 2025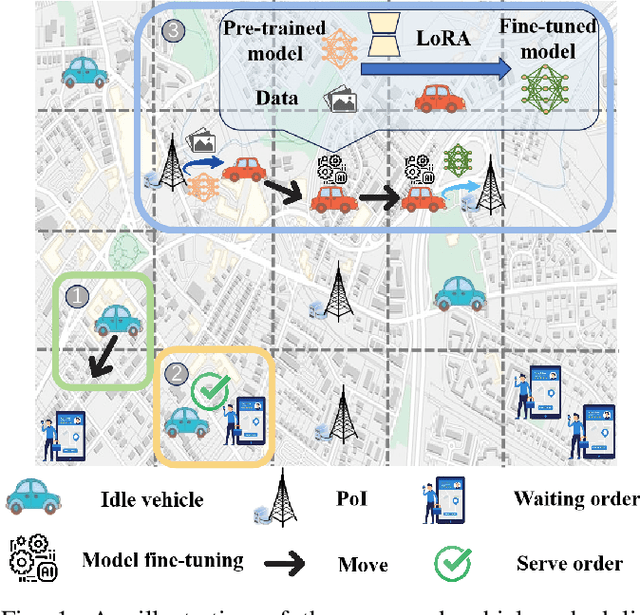



Advances in artificial intelligence (AI) including foundation models (FMs), are increasingly transforming human society, with smart city driving the evolution of urban living.Meanwhile, vehicle crowdsensing (VCS) has emerged as a key enabler, leveraging vehicles' mobility and sensor-equipped capabilities. In particular, ride-hailing vehicles can effectively facilitate flexible data collection and contribute towards urban intelligence, despite resource limitations. Therefore, this work explores a promising scenario, where edge-assisted vehicles perform joint tasks of order serving and the emerging foundation model fine-tuning using various urban data. However, integrating the VCS AI task with the conventional order serving task is challenging, due to their inconsistent spatio-temporal characteristics: (i) The distributions of ride orders and data point-of-interests (PoIs) may not coincide in geography, both following a priori unknown patterns; (ii) they have distinct forms of temporal effects, i.e., prolonged waiting makes orders become instantly invalid while data with increased staleness gradually reduces its utility for model fine-tuning.To overcome these obstacles, we propose an online framework based on multi-agent reinforcement learning (MARL) with careful augmentation. A new quality-of-service (QoS) metric is designed to characterize and balance the utility of the two joint tasks, under the effects of varying data volumes and staleness. We also integrate graph neural networks (GNNs) with MARL to enhance state representations, capturing graph-structured, time-varying dependencies among vehicles and across locations. Extensive experiments on our testbed simulator, utilizing various real-world foundation model fine-tuning tasks and the New York City Taxi ride order dataset, demonstrate the advantage of our proposed method.
Real-Time Neural-Enhancement for Online Cloud Gaming
Jan 12, 2025



Online Cloud gaming demands real-time, high-quality video transmission across variable wide-area networks (WANs). Neural-enhanced video transmission algorithms employing super-resolution (SR) for video quality enhancement have effectively challenged WAN environments. However, these SR-based methods require intensive fine-tuning for the whole video, making it infeasible in diverse online cloud gaming. To address this, we introduce River, a cloud gaming delivery framework designed based on the observation that video segment features in cloud gaming are typically repetitive and redundant. This permits a significant opportunity to reuse fine-tuned SR models, reducing the fine-tuning latency of minutes to query latency of milliseconds. To enable the idea, we design a practical system that addresses several challenges, such as model organization, online model scheduler, and transfer strategy. River first builds a content-aware encoder that fine-tunes SR models for diverse video segments and stores them in a lookup table. When delivering cloud gaming video streams online, River checks the video features and retrieves the most relevant SR models to enhance the frame quality. Meanwhile, if no existing SR model performs well enough for some video segments, River will further fine-tune new models and update the lookup table. Finally, to avoid the overhead of streaming model weight to the clients, River designs a prefetching strategy that predicts the models with the highest possibility of being retrieved. Our evaluation based on real video game streaming demonstrates River can reduce redundant training overhead by 44% and improve the Peak-Signal-to-Noise-Ratio by 1.81dB compared to the SOTA solutions. Practical deployment shows River meets real-time requirements, achieving approximately 720p 20fps on mobile devices.
FedMoE-DA: Federated Mixture of Experts via Domain Aware Fine-grained Aggregation
Nov 04, 2024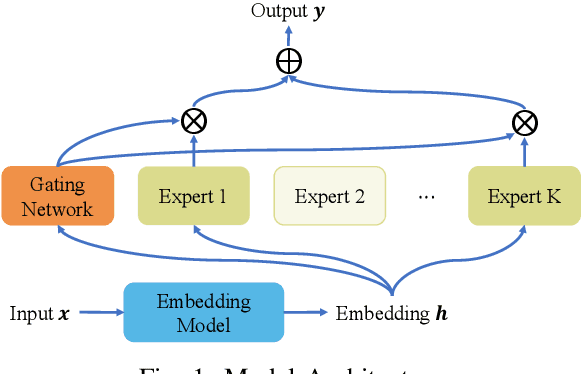
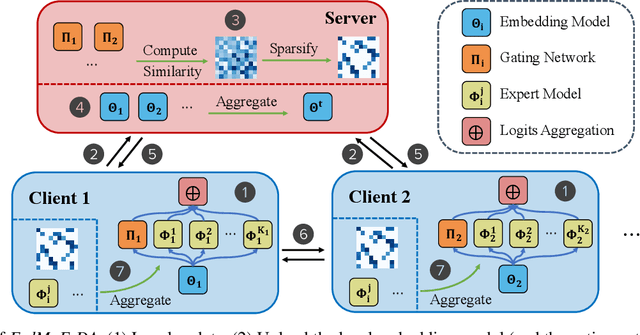
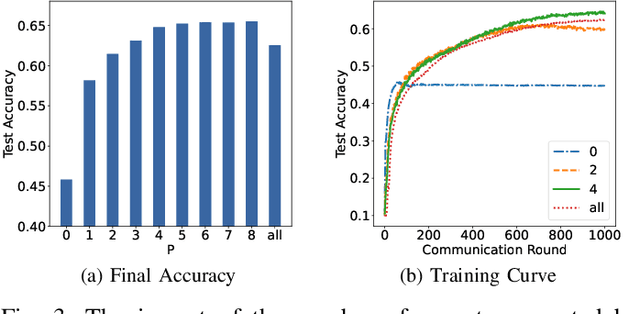
Federated learning (FL) is a collaborative machine learning approach that enables multiple clients to train models without sharing their private data. With the rise of deep learning, large-scale models have garnered significant attention due to their exceptional performance. However, a key challenge in FL is the limitation imposed by clients with constrained computational and communication resources, which hampers the deployment of these large models. The Mixture of Experts (MoE) architecture addresses this challenge with its sparse activation property, which reduces computational workload and communication demands during inference and updates. Additionally, MoE facilitates better personalization by allowing each expert to specialize in different subsets of the data distribution. To alleviate the communication burdens between the server and clients, we propose FedMoE-DA, a new FL model training framework that leverages the MoE architecture and incorporates a novel domain-aware, fine-grained aggregation strategy to enhance the robustness, personalizability, and communication efficiency simultaneously. Specifically, the correlation between both intra-client expert models and inter-client data heterogeneity is exploited. Moreover, we utilize peer-to-peer (P2P) communication between clients for selective expert model synchronization, thus significantly reducing the server-client transmissions. Experiments demonstrate that our FedMoE-DA achieves excellent performance while reducing the communication pressure on the server.
FedReMa: Improving Personalized Federated Learning via Leveraging the Most Relevant Clients
Nov 04, 2024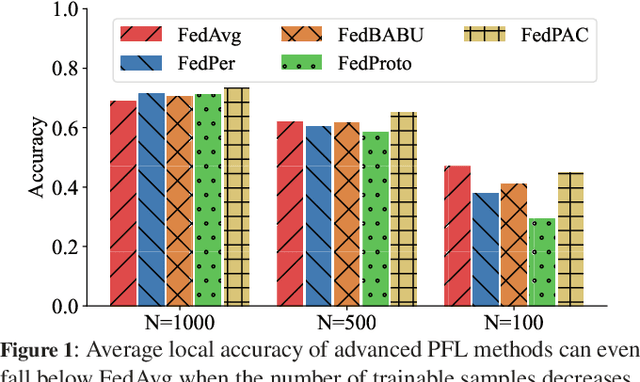
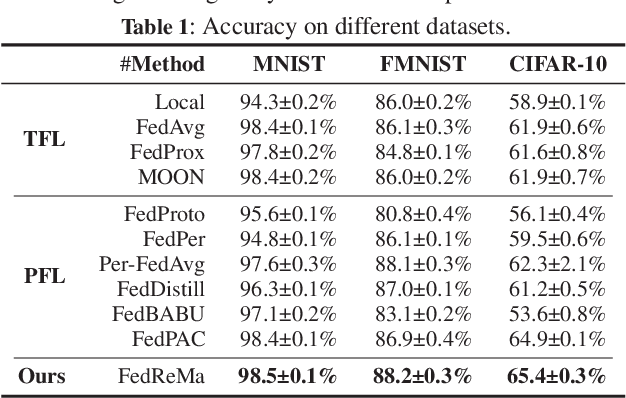
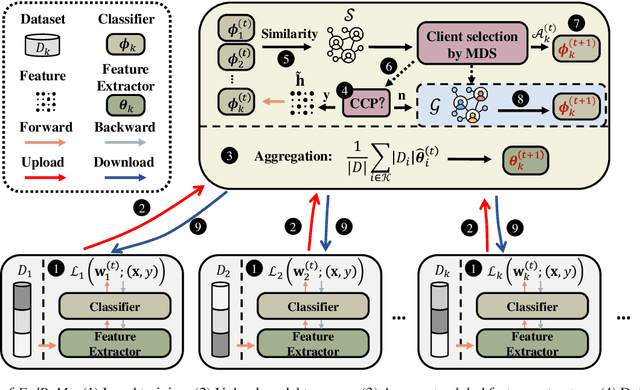
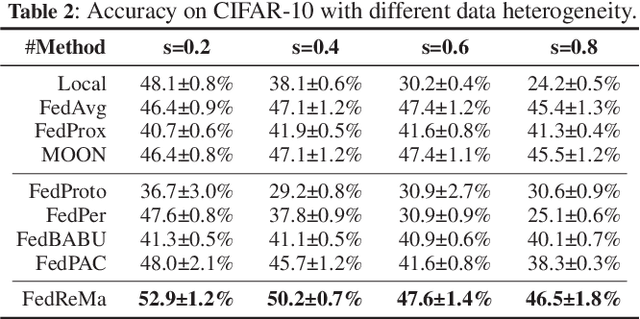
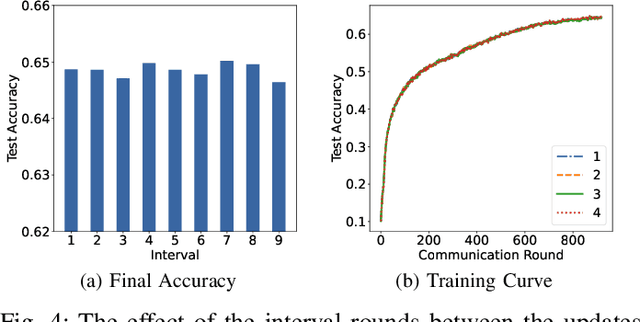
Federated Learning (FL) is a distributed machine learning paradigm that achieves a globally robust model through decentralized computation and periodic model synthesis, primarily focusing on the global model's accuracy over aggregated datasets of all participating clients. Personalized Federated Learning (PFL) instead tailors exclusive models for each client, aiming to enhance the accuracy of clients' individual models on specific local data distributions. Despite of their wide adoption, existing FL and PFL works have yet to comprehensively address the class-imbalance issue, one of the most critical challenges within the realm of data heterogeneity in PFL and FL research. In this paper, we propose FedReMa, an efficient PFL algorithm that can tackle class-imbalance by 1) utilizing an adaptive inter-client co-learning approach to identify and harness different clients' expertise on different data classes throughout various phases of the training process, and 2) employing distinct aggregation methods for clients' feature extractors and classifiers, with the choices informed by the different roles and implications of these model components. Specifically, driven by our experimental findings on inter-client similarity dynamics, we develop critical co-learning period (CCP), wherein we introduce a module named maximum difference segmentation (MDS) to assess and manage task relevance by analyzing the similarities between clients' logits of their classifiers. Outside the CCP, we employ an additional scheme for model aggregation that utilizes historical records of each client's most relevant peers to further enhance the personalization stability. We demonstrate the superiority of our FedReMa in extensive experiments.
DYNAMITE: Dynamic Interplay of Mini-Batch Size and Aggregation Frequency for Federated Learning with Static and Streaming Dataset
Oct 20, 2023Federated Learning (FL) is a distributed learning paradigm that can coordinate heterogeneous edge devices to perform model training without sharing private data. While prior works have focused on analyzing FL convergence with respect to hyperparameters like batch size and aggregation frequency, the joint effects of adjusting these parameters on model performance, training time, and resource consumption have been overlooked, especially when facing dynamic data streams and network characteristics. This paper introduces novel analytical models and optimization algorithms that leverage the interplay between batch size and aggregation frequency to navigate the trade-offs among convergence, cost, and completion time for dynamic FL training. We establish a new convergence bound for training error considering heterogeneous datasets across devices and derive closed-form solutions for co-optimized batch size and aggregation frequency that are consistent across all devices. Additionally, we design an efficient algorithm for assigning different batch configurations across devices, improving model accuracy and addressing the heterogeneity of both data and system characteristics. Further, we propose an adaptive control algorithm that dynamically estimates network states, efficiently samples appropriate data batches, and effectively adjusts batch sizes and aggregation frequency on the fly. Extensive experiments demonstrate the superiority of our offline optimal solutions and online adaptive algorithm.
FedDD: Toward Communication-efficient Federated Learning with Differential Parameter Dropout
Sep 01, 2023



Federated Learning (FL) requires frequent exchange of model parameters, which leads to long communication delay, especially when the network environments of clients vary greatly. Moreover, the parameter server needs to wait for the slowest client (i.e., straggler, which may have the largest model size, lowest computing capability or worst network condition) to upload parameters, which may significantly degrade the communication efficiency. Commonly-used client selection methods such as partial client selection would lead to the waste of computing resources and weaken the generalization of the global model. To tackle this problem, along a different line, in this paper, we advocate the approach of model parameter dropout instead of client selection, and accordingly propose a novel framework of Federated learning scheme with Differential parameter Dropout (FedDD). FedDD consists of two key modules: dropout rate allocation and uploaded parameter selection, which will optimize the model parameter uploading ratios tailored to different clients' heterogeneous conditions and also select the proper set of important model parameters for uploading subject to clients' dropout rate constraints. Specifically, the dropout rate allocation is formulated as a convex optimization problem, taking system heterogeneity, data heterogeneity, and model heterogeneity among clients into consideration. The uploaded parameter selection strategy prioritizes on eliciting important parameters for uploading to speedup convergence. Furthermore, we theoretically analyze the convergence of the proposed FedDD scheme. Extensive performance evaluations demonstrate that the proposed FedDD scheme can achieve outstanding performances in both communication efficiency and model convergence, and also possesses a strong generalization capability to data of rare classes.
A3D: Adaptive, Accurate, and Autonomous Navigation for Edge-Assisted Drones
Jul 19, 2023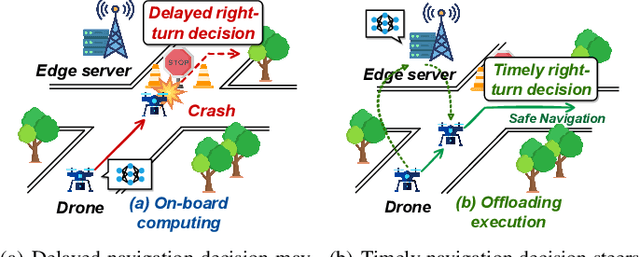
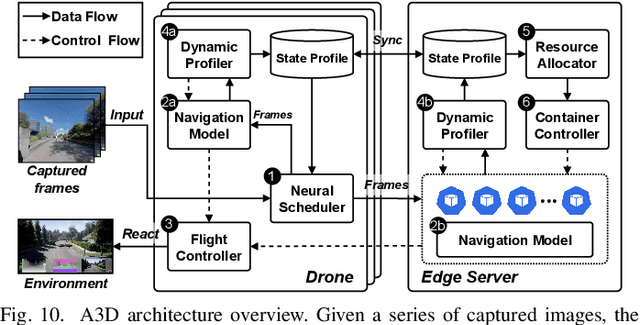
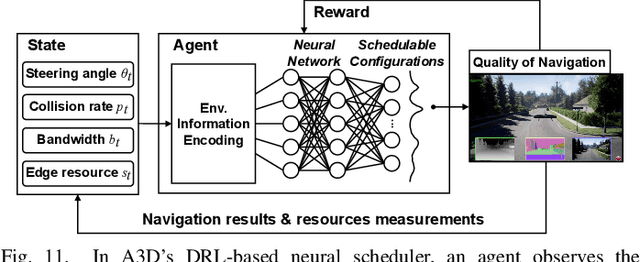
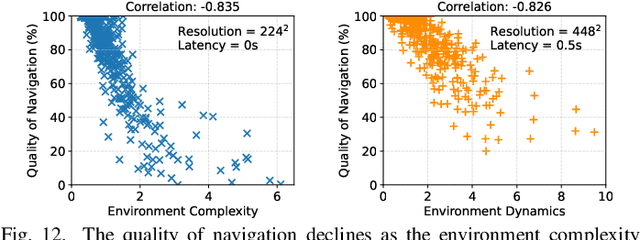
Accurate navigation is of paramount importance to ensure flight safety and efficiency for autonomous drones. Recent research starts to use Deep Neural Networks to enhance drone navigation given their remarkable predictive capability for visual perception. However, existing solutions either run DNN inference tasks on drones in situ, impeded by the limited onboard resource, or offload the computation to external servers which may incur large network latency. Few works consider jointly optimizing the offloading decisions along with image transmission configurations and adapting them on the fly. In this paper, we propose A3D, an edge server assisted drone navigation framework that can dynamically adjust task execution location, input resolution, and image compression ratio in order to achieve low inference latency, high prediction accuracy, and long flight distances. Specifically, we first augment state-of-the-art convolutional neural networks for drone navigation and define a novel metric called Quality of Navigation as our optimization objective which can effectively capture the above goals. We then design a deep reinforcement learning based neural scheduler at the drone side for which an information encoder is devised to reshape the state features and thus improve its learning ability. To further support simultaneous multi-drone serving, we extend the edge server design by developing a network-aware resource allocation algorithm, which allows provisioning containerized resources aligned with drones' demand. We finally implement a proof-of-concept prototype with realistic devices and validate its performance in a real-world campus scene, as well as a simulation environment for thorough evaluation upon AirSim. Extensive experimental results show that A3D can reduce end-to-end latency by 28.06% and extend the flight distance by up to 27.28% compared with non-adaptive solutions.