 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Model Performance Benchmarking on Mobile Platforms: A Thorough Evaluation
Oct 04, 2024
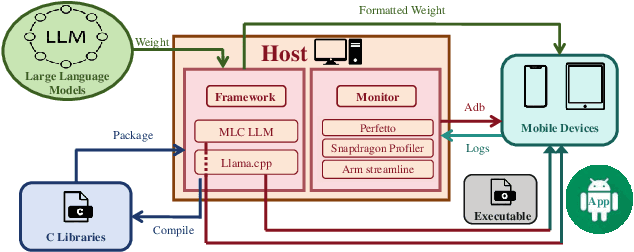
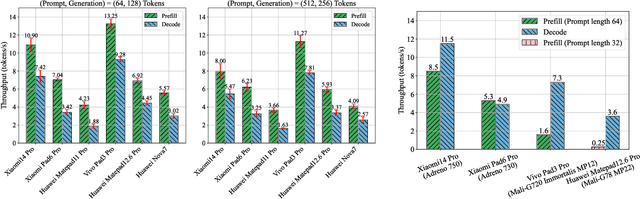
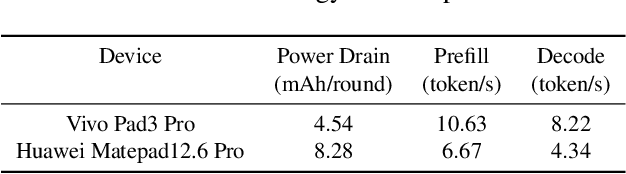
As large language models (LLMs) increasingly integrate into every aspect of our work and daily lives, there are growing concerns about user privacy, which push the trend toward local deployment of these models. There are a number of lightweight LLMs (e.g., Gemini Nano, LLAMA2 7B) that can run locally on smartphones, providing users with greater control over their personal data. As a rapidly emerging application, we are concerned about their performance on commercial-off-the-shelf mobile devices. To fully understand the current landscape of LLM deployment on mobile platforms, we conduct a comprehensive measurement study on mobile devices. We evaluate both metrics that affect user experience, including token throughput, latency, and battery consumption, as well as factors critical to developers, such as resource utilization, DVFS strategies, and inference engines. In addition, we provide a detailed analysis of how these hardware capabilities and system dynamics affect on-device LLM performance, which may help developers identify and address bottlenecks for mobile LLM applications. We also provide comprehensive comparisons across the mobile system-on-chips (SoCs) from major vendors, highlighting their performance differences in handling LLM workloads. We hope that this study can provide insights for both the development of on-device LLMs and the design for future mobile system architecture.
Online Resource Allocation for Edge Intelligence with Colocated Model Retraining and Inference
May 25, 2024



With edge intelligence, AI models are increasingly pushed to the edge to serve ubiquitous users. However, due to the drift of model, data, and task, AI model deployed at the edge suffers from degraded accuracy in the inference serving phase. Model retraining handles such drifts by periodically retraining the model with newly arrived data. When colocating model retraining and model inference serving for the same model on resource-limited edge servers, a fundamental challenge arises in balancing the resource allocation for model retraining and inference, aiming to maximize long-term inference accuracy. This problem is particularly difficult due to the underlying mathematical formulation being time-coupled, non-convex, and NP-hard. To address these challenges, we introduce a lightweight and explainable online approximation algorithm, named ORRIC, designed to optimize resource allocation for adaptively balancing the accuracy of model training and inference. The competitive ratio of ORRIC outperforms that of the traditional Inference-Only paradigm, especially when data drift persists for a sufficiently lengthy time. This highlights the advantages and applicable scenarios of colocating model retraining and inference. Notably, ORRIC can be translated into several heuristic algorithms for different resource environments. Experiments conducted in real scenarios validate the effectiveness of ORRIC.
FedDD: Toward Communication-efficient Federated Learning with Differential Parameter Dropout
Sep 01, 2023



Federated Learning (FL) requires frequent exchange of model parameters, which leads to long communication delay, especially when the network environments of clients vary greatly. Moreover, the parameter server needs to wait for the slowest client (i.e., straggler, which may have the largest model size, lowest computing capability or worst network condition) to upload parameters, which may significantly degrade the communication efficiency. Commonly-used client selection methods such as partial client selection would lead to the waste of computing resources and weaken the generalization of the global model. To tackle this problem, along a different line, in this paper, we advocate the approach of model parameter dropout instead of client selection, and accordingly propose a novel framework of Federated learning scheme with Differential parameter Dropout (FedDD). FedDD consists of two key modules: dropout rate allocation and uploaded parameter selection, which will optimize the model parameter uploading ratios tailored to different clients' heterogeneous conditions and also select the proper set of important model parameters for uploading subject to clients' dropout rate constraints. Specifically, the dropout rate allocation is formulated as a convex optimization problem, taking system heterogeneity, data heterogeneity, and model heterogeneity among clients into consideration. The uploaded parameter selection strategy prioritizes on eliciting important parameters for uploading to speedup convergence. Furthermore, we theoretically analyze the convergence of the proposed FedDD scheme. Extensive performance evaluations demonstrate that the proposed FedDD scheme can achieve outstanding performances in both communication efficiency and model convergence, and also possesses a strong generalization capability to data of rare classes.
FedNILM: Applying Federated Learning to NILM Applications at the Edge
Jun 07, 2021
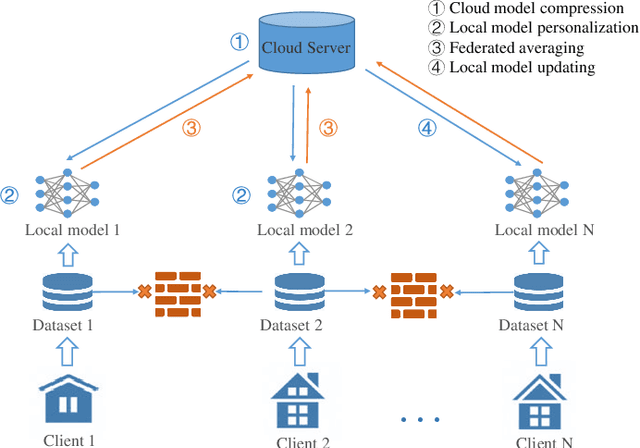
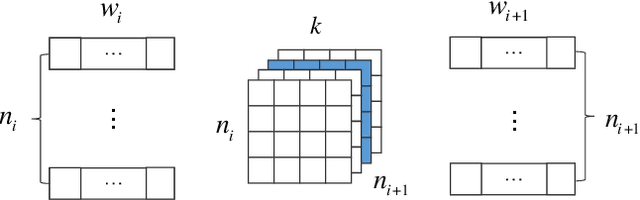
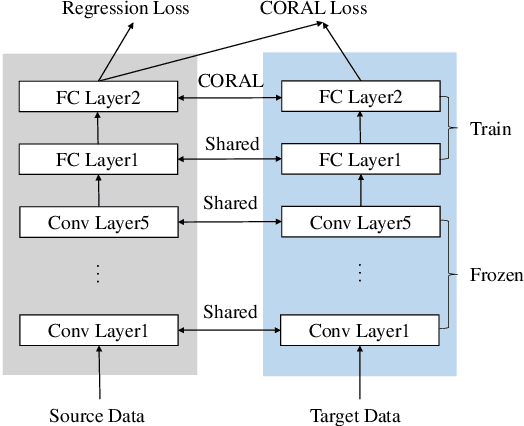
Non-intrusive load monitoring (NILM) helps disaggregate the household's main electricity consumption to energy usages of individual appliances, thus greatly cutting down the cost in fine-grained household load monitoring. To address the arisen privacy concern in NILM applications, federated learning (FL) could be leveraged for NILM model training and sharing. When applying the FL paradigm in real-world NILM applications, however, we are faced with the challenges of edge resource restriction, edge model personalization and edge training data scarcity. In this paper we present FedNILM, a practical FL paradigm for NILM applications at the edge client. Specifically, FedNILM is designed to deliver privacy-preserving and personalized NILM services to large-scale edge clients, by leveraging i) secure data aggregation through federated learning, ii) efficient cloud model compression via filter pruning and multi-task learning, and iii) personalized edge model building with unsupervised transfer learning. Our experiments on real-world energy data show that, FedNILM is able to achieve personalized energy disaggregation with the state-of-the-art accuracy, while ensuring privacy preserving at the edge client.
More Behind Your Electricity Bill: a Dual-DNN Approach to Non-Intrusive Load Monitoring
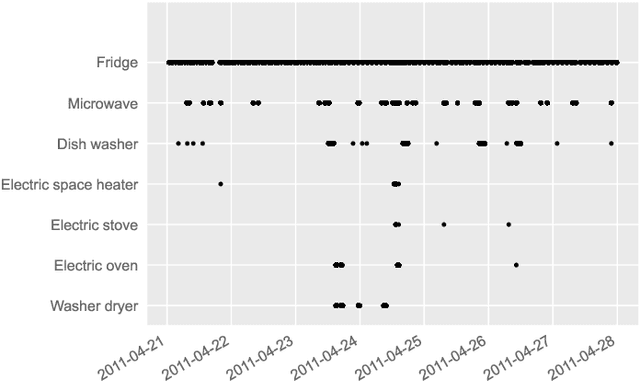
Jun 01, 2021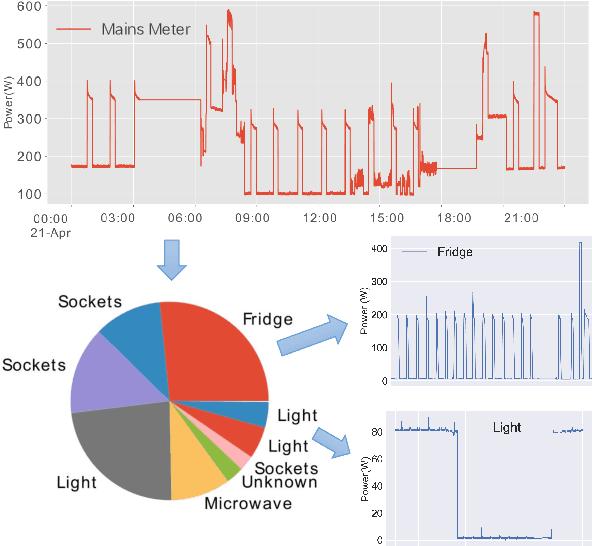
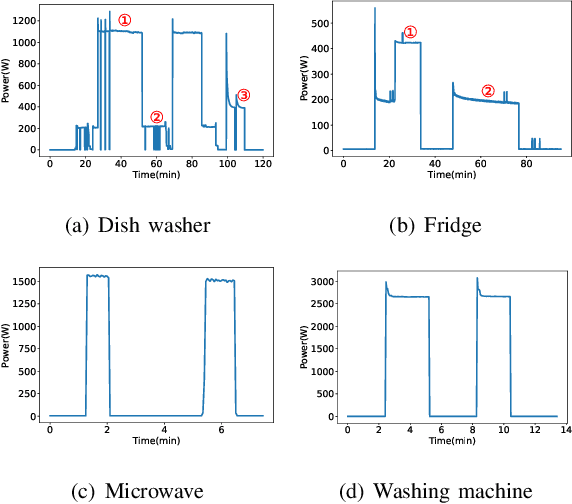
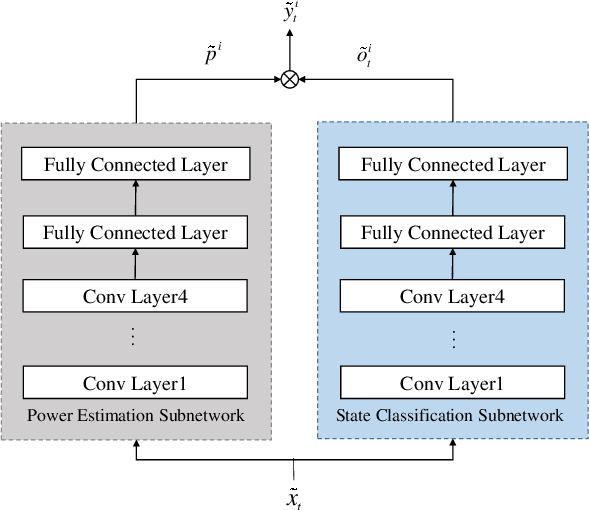
Non-intrusive load monitoring (NILM) is a well-known single-channel blind source separation problem that aims to decompose the household energy consumption into itemised energy usage of individual appliances. In this way, considerable energy savings could be achieved by enhancing household's awareness of energy usage. Recent investigations have shown that deep neural networks (DNNs) based approaches are promising for the NILM task. Nevertheless, they normally ignore the inherent properties of appliance operations in the network design, potentially leading to implausible results. We are thus motivated to develop the dual Deep Neural Networks (dual-DNN), which aims to i) take advantage of DNNs' learning capability of latent features and ii) empower the DNN architecture with identification ability of universal properties. Specifically in the design of dual-DNN, we adopt one subnetwork to measure power ratings of different appliances' operation states, and the other subnetwork to identify the running states of target appliances. The final result is then obtained by multiplying these two network outputs and meanwhile considering the multi-state property of household appliances. To enforce the sparsity property in appliance's state operating, we employ median filtering and hard gating mechanisms to the subnetwork for state identification. Compared with the state-of-the-art NILM methods, our dual-DNN approach demonstrates a 21.67% performance improvement in average on two public benchmark datasets.
ECGadv: Generating Adversarial Electrocardiogram to Misguide Arrhythmia Classification System
Jan 12, 2019
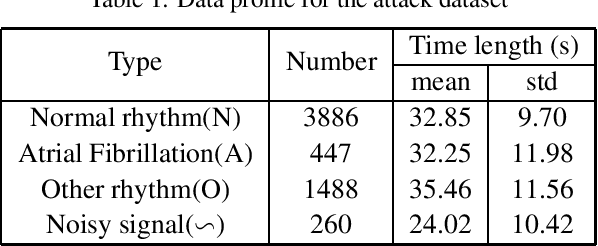
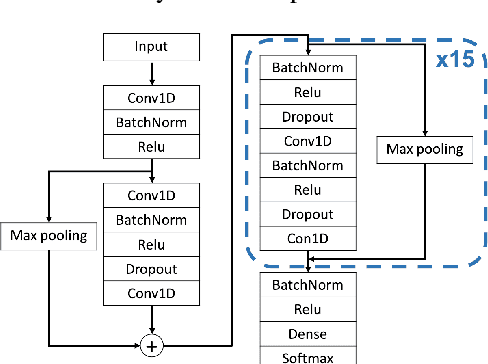

Deep neural networks (DNNs)-powered Electrocardiogram (ECG) diagnosis systems emerge recently, and are expected to take over tedious examinations by cardiologists. However, their vulnerability to adversarial attacks still lack of comprehensive investigation. ECG recordings differ from images in the visualization, dynamic property and accessibility, thus, the existing image-targeted attack may not directly applicable. To fill this gap, this paper proposes ECGadv to explore the feasibility of adversarial attacks on arrhythmia classification system. We identify the main issues under two different deployment models(i.e., cloud-based and local-based) and propose effective attack schemes respectively. Our results demonstrate the blind spots of DNN-powered diagnosis system under adversarial attacks, which facilitates future researches on countermeasures.