 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniEEG-Bench: A Standardized Evaluation Benchmark for EEG Foundation Models
May 30, 2026Electroencephalography (EEG) supports a variety of brain-computer interface (BCI) tasks ranging from brain-state monitoring to human-LLM interactions. EEG foundation models are emerging, but evaluation remains fragmented due to heterogeneous datasets and nconsistent task protocols. Here, we introduce OmniEEG-Bench, a unified benchmark and downstream task roadmap for EEG foundation models (FMs). It organizes evaluation of EEG FMs into six task families spanning (i) signal reliability, (ii) biometrics and disease, (iii) consciousness and state, (iv) cognition and emotion, (v) naturalistic stimulus decoding, and (vi) motor and interaction, introducing a new generation of tasks not systematically benchmarked in prior EEG FM work. OmniEEG-Bench standardizes model deployment, task definitions, and metrics through a task-card specification, and unifies 54 EEG datasets with consistent evaluation protocols. We benchmark 10 representative EEG foundation models and report a leaderboard that covers diverse evaluation settings. Both pretraining dataset diversity and model size are significantly associated with better average ranks across datasets, revealing scaling-law behavior in EEG foundation models (Figure 1). These results suggest that scaling EEG foundation models requires not only larger architectures but also broader and more diverse pretraining data. The benchmark code is available at https://github.com/ncclab-sustech/omni-eegbench.git.
FRISM: Fine-Grained Reasoning Injection via Subspace-Level Model Merging for Vision-Language Models
Jan 29, 2026Efficiently enhancing the reasoning capabilities of Vision-Language Models (VLMs) by merging them with Large Reasoning Models (LRMs) has emerged as a promising direction. However, existing methods typically operate at a coarse-grained layer level, which often leads to a trade-off between injecting reasoning capabilities and preserving visual capabilities. To address this limitation, we propose {FRISM} (Fine-grained Reasoning Injection via Subspace-level model Merging), a fine-grained reasoning injection framework based on subspace-level model merging. Observing that reasoning capabilities are encoded in distinct subspaces, FRISM decomposes LRM task vectors via Singular Value Decomposition (SVD) and adaptively tunes the scaling coefficients of each subspace through learning to realize fine-grained reasoning injection. Furthermore, we introduce a label-free self-distillation learning strategy with a dual-objective optimization using common vision-language perception datasets. Extensive experiments demonstrate that FRISM effectively improves reasoning capabilities without compromising the model's original visual capabilities by consistently achieving state-of-the-art performance across diverse visual reasoning benchmarks.
InfoAffect: A Dataset for Affective Analysis of Infographics
Nov 09, 2025Infographics are widely used to convey complex information, yet their affective dimensions remain underexplored due to the scarcity of data resources. We introduce a 3.5k-sample affect-annotated InfoAffect dataset, which combines textual content with real-world infographics. We first collect the raw data from six domains and aligned them via preprocessing, the accompanied-text-priority method, and three strategies to guarantee the quality and compliance. After that we construct an affect table and use it to constrain annotation. Five state-of-the-art multimodal large language models (MLLMs) then analyze both modalities, and their outputs are fused with Reciprocal Rank Fusion (RRF) algorithm to yield robust affects and confidences. We conducted a user study with two experiments to validate usability and assess InfoAffect dataset using the Composite Affect Consistency Index (CACI), achieving an overall score of 0.986, which indicates high accuracy.
UrbanGraph: Physics-Informed Spatio-Temporal Dynamic Heterogeneous Graphs for Urban Microclimate Prediction
Oct 01, 2025With rapid urbanization, predicting urban microclimates has become critical, as it affects building energy demand and public health risks. However, existing generative and homogeneous graph approaches fall short in capturing physical consistency, spatial dependencies, and temporal variability. To address this, we introduce UrbanGraph, a physics-informed framework integrating heterogeneous and dynamic spatio-temporal graphs. It encodes key physical processes -- vegetation evapotranspiration, shading, and convective diffusion -- while modeling complex spatial dependencies among diverse urban entities and their temporal evolution. We evaluate UrbanGraph on UMC4/12, a physics-based simulation dataset covering diverse urban configurations and climates. Results show that UrbanGraph improves $R^2$ by up to 10.8% and reduces FLOPs by 17.0% over all baselines, with heterogeneous and dynamic graphs contributing 3.5% and 7.1% gains. Our dataset provides the first high-resolution benchmark for spatio-temporal microclimate modeling, and our method extends to broader urban heterogeneous dynamic computing tasks.
Decouple and Orthogonalize: A Data-Free Framework for LoRA Merging
May 21, 2025With more open-source models available for diverse tasks, model merging has gained attention by combining models into one, reducing training, storage, and inference costs. Current research mainly focuses on model merging for full fine-tuning, overlooking the popular LoRA. However, our empirical analysis reveals that: a) existing merging methods designed for full fine-tuning perform poorly on LoRA; b) LoRA modules show much larger parameter magnitude variance than full fine-tuned weights; c) greater parameter magnitude variance correlates with worse merging performance. Considering that large magnitude variances cause deviations in the distribution of the merged parameters, resulting in information loss and performance degradation, we propose a Decoupled and Orthogonal merging approach(DO-Merging). By separating parameters into magnitude and direction components and merging them independently, we reduce the impact of magnitude differences on the directional alignment of the merged models, thereby preserving task information. Furthermore, we introduce a data-free, layer-wise gradient descent method with orthogonal constraints to mitigate interference during the merging of direction components. We provide theoretical guarantees for both the decoupling and orthogonal components. And we validate through extensive experiments across vision, language, and multi-modal domains that our proposed DO-Merging can achieve significantly higher performance than existing merging methods at a minimal cost. Notably, each component can be flexibly integrated with existing methods, offering near free-lunch improvements across tasks.
Interpretable Dual-Stream Learning for Local Wind Hazard Prediction in Vulnerable Communities
May 20, 2025


Wind hazards such as tornadoes and straight-line winds frequently affect vulnerable communities in the Great Plains of the United States, where limited infrastructure and sparse data coverage hinder effective emergency response. Existing forecasting systems focus primarily on meteorological elements and often fail to capture community-specific vulnerabilities, limiting their utility for localized risk assessment and resilience planning. To address this gap, we propose an interpretable dual-stream learning framework that integrates structured numerical weather data with unstructured textual event narratives. Our architecture combines a Random Forest and RoBERTa-based transformer through a late fusion mechanism, enabling robust and context-aware wind hazard prediction. The system is tailored for underserved tribal communities and supports block-level risk assessment. Experimental results show significant performance gains over traditional baselines. Furthermore, gradient-based sensitivity and ablation studies provide insight into the model's decision-making process, enhancing transparency and operational trust. The findings demonstrate both predictive effectiveness and practical value in supporting emergency preparedness and advancing community resilience.
Dynamic Base model Shift for Delta Compression
May 16, 2025
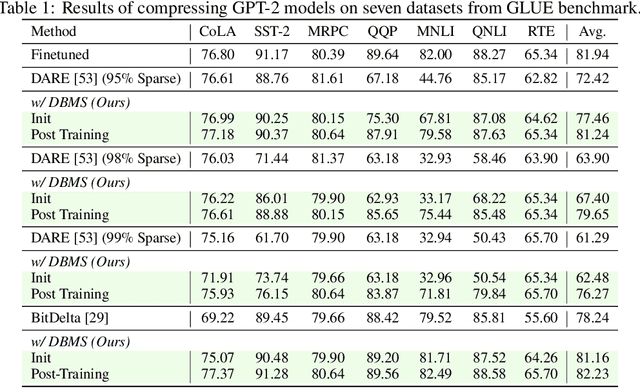

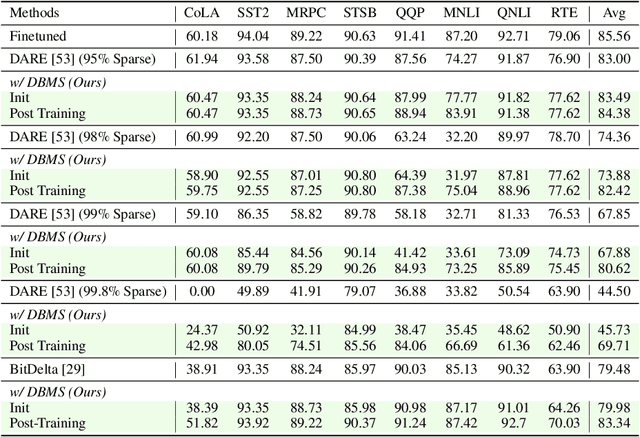
Transformer-based models with the pretrain-finetune paradigm bring about significant progress, along with the heavy storage and deployment costs of finetuned models on multiple tasks. Delta compression attempts to lower the costs by reducing the redundancy of delta parameters (i.e., the difference between the finetuned and pre-trained model weights) through pruning or quantization. However, existing methods by default employ the pretrained model as the base model and compress the delta parameters for every task, which may causes significant performance degradation, especially when the compression rate is extremely high. To tackle this issue, we investigate the impact of different base models on the performance of delta compression and find that the pre-trained base model can hardly be optimal. To this end, we propose Dynamic Base Model Shift (DBMS), which dynamically adapts the base model to the target task before performing delta compression. Specifically, we adjust two parameters, which respectively determine the magnitude of the base model shift and the overall scale of delta compression, to boost the compression performance on each task. Through low-cost learning of these two parameters, our DBMS can maintain most of the finetuned model's performance even under an extremely high compression ratio setting, significantly surpassing existing methods. Moreover, our DBMS is orthogonal and can be integrated with a variety of other methods, and it has been evaluated across different types of models including language, vision transformer, and multi-modal models.
Seeing Delta Parameters as JPEG Images: Data-Free Delta Compression with Discrete Cosine Transform
Mar 09, 2025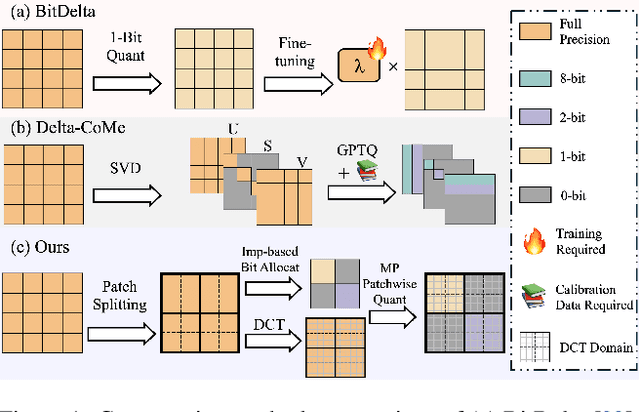



With transformer-based models and the pretrain-finetune paradigm becoming mainstream, the high storage and deployment costs of individual finetuned models on multiple tasks pose critical challenges. Delta compression attempts to lower the costs by reducing the redundancy of delta parameters (i.e., the difference between the finetuned and pre-trained model weights). However, existing methods usually face problems including data accessibility and training requirements. To tackle this issue, we introduce Delta-DCT, the first data-free delta compression method inspired by classic JPEG image compression, leveraging the Discrete Cosine Transform (DCT). We first (a) group delta parameters within a layer into patches. Then we (b) assess the importance of each patch and allocate them with different quantization bit-widths. Afterwards, we (c) convert these patches to the DCT domain and conduct quantization to each patch based on the allocated bit-width. The proposed Delta-DCT does not require any training or data calibration, while achieving performance comparable to or even surpassing original finetuned models under 1-bit equivalent delta compression ratios on different kinds of models including: (1) recently-released LLMs of different sizes from 7B to 13B, (2) relatively smaller language models including RoBERTa and T5 models, (3) variants of vision transformer models, and (4) multi-modal BEiT-3 models.
DeRS: Towards Extremely Efficient Upcycled Mixture-of-Experts Models
Mar 03, 2025



Upcycled Mixture-of-Experts (MoE) models have shown great potential in various tasks by converting the original Feed-Forward Network (FFN) layers in pre-trained dense models into MoE layers. However, these models still suffer from significant parameter inefficiency due to the introduction of multiple experts. In this work, we propose a novel DeRS (Decompose, Replace, and Synthesis) paradigm to overcome this shortcoming, which is motivated by our observations about the unique redundancy mechanisms of upcycled MoE experts. Specifically, DeRS decomposes the experts into one expert-shared base weight and multiple expert-specific delta weights, and subsequently represents these delta weights in lightweight forms. Our proposed DeRS paradigm can be applied to enhance parameter efficiency in two different scenarios, including: 1) DeRS Compression for inference stage, using sparsification or quantization to compress vanilla upcycled MoE models; and 2) DeRS Upcycling for training stage, employing lightweight sparse or low-rank matrixes to efficiently upcycle dense models into MoE models. Extensive experiments across three different tasks show that the proposed methods can achieve extreme parameter efficiency while maintaining the performance for both training and compression of upcycled MoE models.
OmniSR: Shadow Removal under Direct and Indirect Lighting
Oct 02, 2024



Shadows can originate from occlusions in both direct and indirect illumination. Although most current shadow removal research focuses on shadows caused by direct illumination, shadows from indirect illumination are often just as pervasive, particularly in indoor scenes. A significant challenge in removing shadows from indirect illumination is obtaining shadow-free images to train the shadow removal network. To overcome this challenge, we propose a novel rendering pipeline for generating shadowed and shadow-free images under direct and indirect illumination, and create a comprehensive synthetic dataset that contains over 30,000 image pairs, covering various object types and lighting conditions. We also propose an innovative shadow removal network that explicitly integrates semantic and geometric priors through concatenation and attention mechanisms. The experiments show that our method outperforms state-of-the-art shadow removal techniques and can effectively generalize to indoor and outdoor scenes under various lighting conditions, enhancing the overall effectiveness and applicability of shadow removal methods.