 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepTextMark: Deep Learning based Text Watermarking for Detection of Large Language Model Generated Text
May 09, 2023



The capabilities of text generators have grown with the rapid development of Large Language Models (LLM). To prevent potential misuse, the ability to detect whether texts are produced by LLM has become increasingly important. Several related works have attempted to solve this problem using binary classifiers that categorize input text as human-written or LLM-generated. However, these classifiers have been shown to be unreliable. As impactful decisions could be made based on the result of the classification, the text source detection needs to be high-quality. To this end, this paper presents DeepTextMark, a deep learning-based text watermarking method for text source detection. Applying Word2Vec and Sentence Encoding for watermark insertion and a transformer-based classifier for watermark detection, DeepTextMark achieves blindness, robustness, imperceptibility, and reliability simultaneously. As discussed further in the paper, these traits are indispensable for generic text source detection, and the application focus of this paper is on the text generated by LLM. DeepTextMark can be implemented as an "add-on" to existing text generation systems. That is, the method does not require access or modification to the text generation technique. Experiments have shown high imperceptibility, high detection accuracy, enhanced robustness, reliability, and fast running speed of DeepTextMark.
Foreign Object Debris Detection for Airport Pavement Images based on Self-supervised Localization and Vision Transformer
Oct 30, 2022
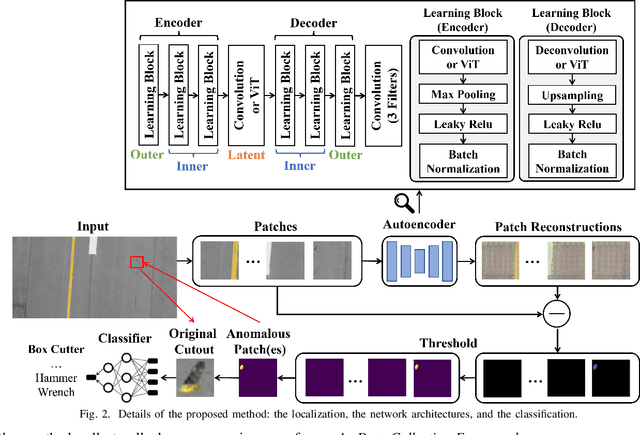

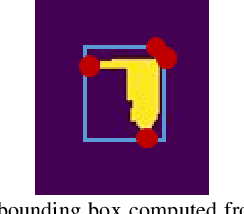
Supervised object detection methods provide subpar performance when applied to Foreign Object Debris (FOD) detection because FOD could be arbitrary objects according to the Federal Aviation Administration (FAA) specification. Current supervised object detection algorithms require datasets that contain annotated examples of every to-be-detected object. While a large and expensive dataset could be developed to include common FOD examples, it is infeasible to collect all possible FOD examples in the dataset representation because of the open-ended nature of FOD. Limitations of the dataset could cause FOD detection systems driven by those supervised algorithms to miss certain FOD, which can become dangerous to airport operations. To this end, this paper presents a self-supervised FOD localization by learning to predict the runway images, which avoids the enumeration of FOD annotation examples. The localization method utilizes the Vision Transformer (ViT) to improve localization performance. The experiments show that the method successfully detects arbitrary FOD in real-world runway situations. The paper also provides an extension to the localization result to perform classification; a feature that can be useful to downstream tasks. To train the localization, this paper also presents a simple and realistic dataset creation framework that only collects clean runway images. The training and testing data for this method are collected at a local airport using unmanned aircraft systems (UAS). Additionally, the developed dataset is provided for public use and further studies.
FOD-A: A Dataset for Foreign Object Debris in Airports
Oct 06, 2021

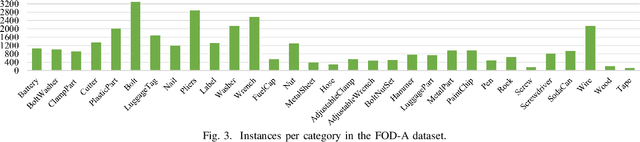
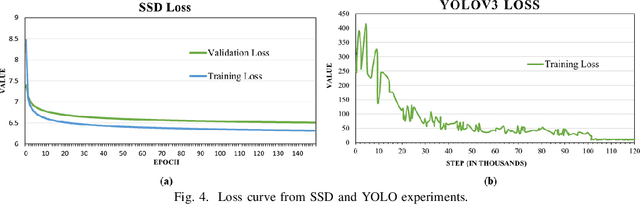
Foreign Object Debris (FOD) detection has attracted increased attention in the area of machine learning and computer vision. However, a robust and publicly available image dataset for FOD has not been initialized. To this end, this paper introduces an image dataset of FOD, named FOD in Airports (FOD-A). FOD-A object categories have been selected based on guidance from prior documentation and related research by the Federal Aviation Administration (FAA). In addition to the primary annotations of bounding boxes for object detection, FOD-A provides labeled environmental conditions. As such, each annotation instance is further categorized into three light level categories (bright, dim, and dark) and two weather categories (dry and wet). Currently, FOD-A has released 31 object categories and over 30,000 annotation instances. This paper presents the creation methodology, discusses the publicly available dataset extension process, and demonstrates the practicality of FOD-A with widely used machine learning models for object detection.