 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOvercoming Autoware-Ubuntu Incompatibility in Autonomous Driving Systems-Equipped Vehicles: Lessons Learned
Oct 09, 2024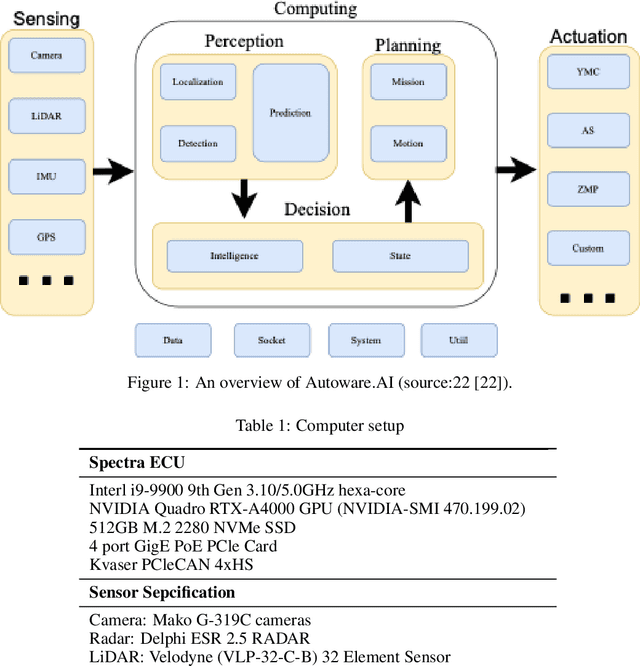
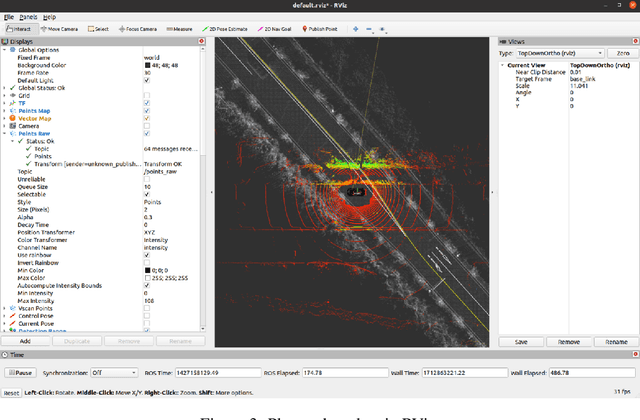
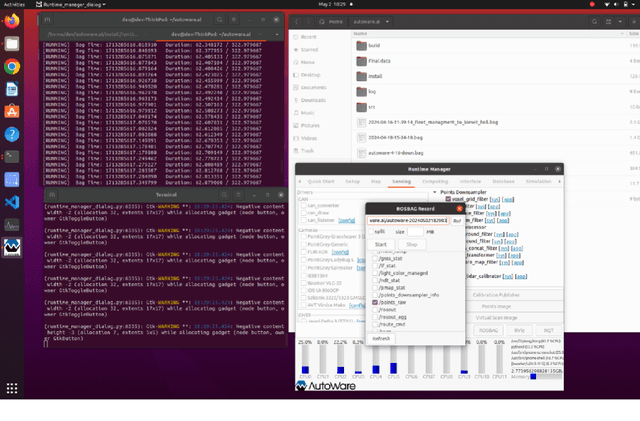
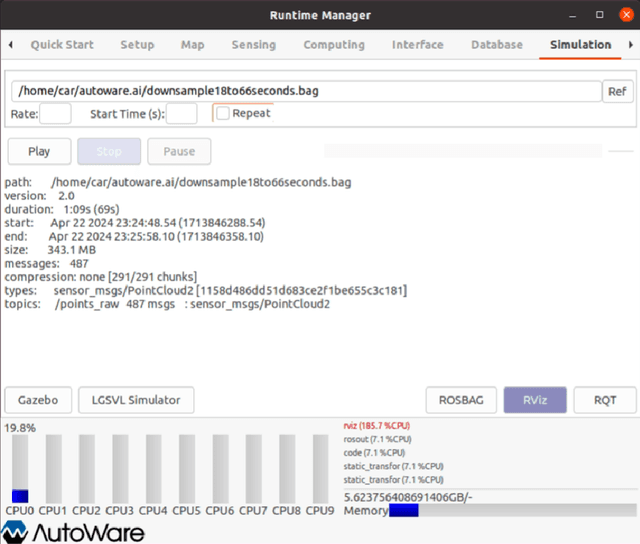
Autonomous vehicles have been rapidly developed as demand that provides safety and efficiency in transportation systems. As autonomous vehicles are designed based on open-source operating and computing systems, there are numerous resources aimed at building an operating platform composed of Ubuntu, Autoware, and Robot Operating System (ROS). However, no explicit guidelines exist to help scholars perform trouble-shooting due to incompatibility between the Autoware platform and Ubuntu operating systems installed in autonomous driving systems-equipped vehicles (i.e., Chrysler Pacifica). The paper presents an overview of integrating the Autoware platform into the autonomous vehicle's interface based on lessons learned from trouble-shooting processes for resolving incompatible issues. The trouble-shooting processes are presented based on resolving the incompatibility and integration issues of Ubuntu 20.04, Autoware.AI, and ROS Noetic software installed in an autonomous driving systems-equipped vehicle. Specifically, the paper focused on common incompatibility issues and code-solving protocols involving Python compatibility, Compute Unified Device Architecture (CUDA) installation, Autoware installation, and simulation in Autoware.AI. The objective of the paper is to provide an explicit and detail-oriented presentation to showcase how to address incompatibility issues among an autonomous vehicle's operating interference. The lessons and experience presented in the paper will be useful for researchers who encountered similar issues and could follow up by performing trouble-shooting activities and implementing ADS-related projects in the Ubuntu, Autoware, and ROS operating systems.
Deep Learning-based Text-in-Image Watermarking
Apr 19, 2024In this work, we introduce a novel deep learning-based approach to text-in-image watermarking, a method that embeds and extracts textual information within images to enhance data security and integrity. Leveraging the capabilities of deep learning, specifically through the use of Transformer-based architectures for text processing and Vision Transformers for image feature extraction, our method sets new benchmarks in the domain. The proposed method represents the first application of deep learning in text-in-image watermarking that improves adaptivity, allowing the model to intelligently adjust to specific image characteristics and emerging threats. Through testing and evaluation, our method has demonstrated superior robustness compared to traditional watermarking techniques, achieving enhanced imperceptibility that ensures the watermark remains undetectable across various image contents.
Image-based Deep Learning for Smart Digital Twins: a Review
Jan 04, 2024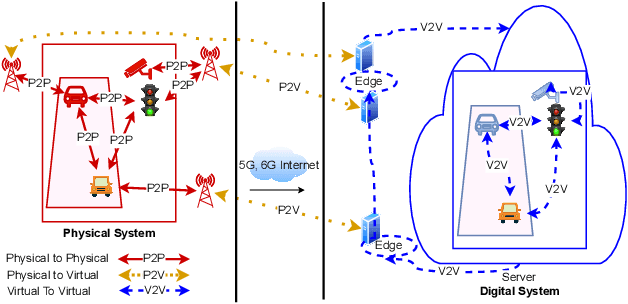
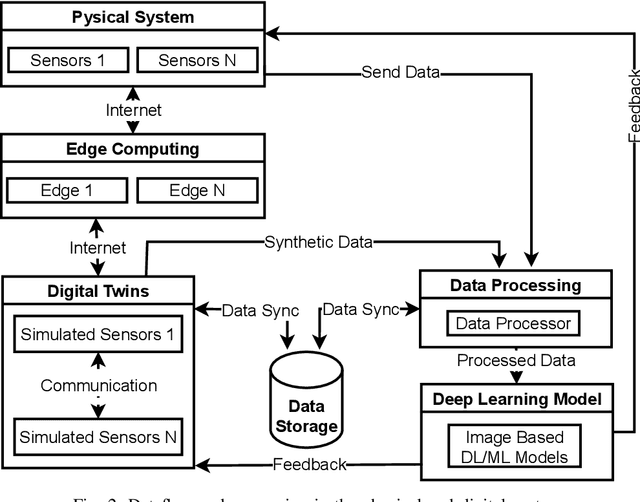
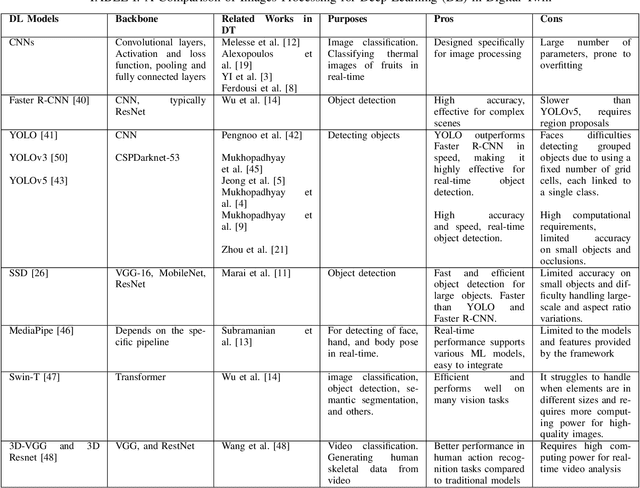
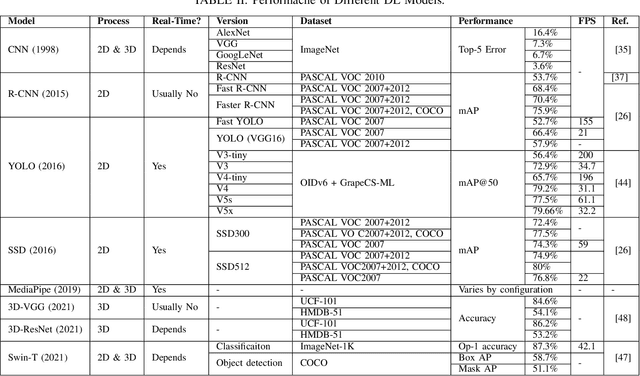
Smart Digital twins (SDTs) are being increasingly used to virtually replicate and predict the behaviors of complex physical systems through continual data assimilation enabling the optimization of the performance of these systems by controlling the actions of systems. Recently, deep learning (DL) models have significantly enhanced the capabilities of SDTs, particularly for tasks such as predictive maintenance, anomaly detection, and optimization. In many domains, including medicine, engineering, and education, SDTs use image data (image-based SDTs) to observe and learn system behaviors and control their behaviors. This paper focuses on various approaches and associated challenges in developing image-based SDTs by continually assimilating image data from physical systems. The paper also discusses the challenges involved in designing and implementing DL models for SDTs, including data acquisition, processing, and interpretation. In addition, insights into the future directions and opportunities for developing new image-based DL approaches to develop robust SDTs are provided. This includes the potential for using generative models for data augmentation, developing multi-modal DL models, and exploring the integration of DL with other technologies, including 5G, edge computing, and IoT. In this paper, we describe the image-based SDTs, which enable broader adoption of the digital twin DT paradigms across a broad spectrum of areas and the development of new methods to improve the abilities of SDTs in replicating, predicting, and optimizing the behavior of complex systems.
Padding Module: Learning the Padding in Deep Neural Networks
Jan 11, 2023
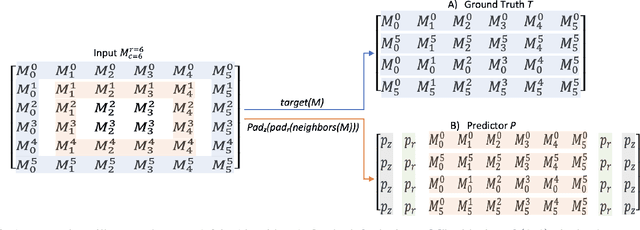
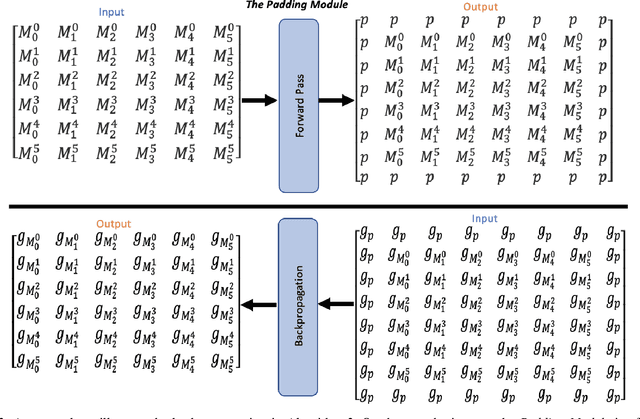
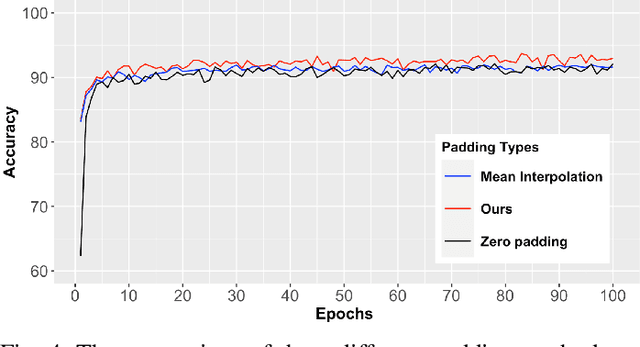
During the last decades, many studies have been dedicated to improving the performance of neural networks, for example, the network architectures, initialization, and activation. However, investigating the importance and effects of learnable padding methods in deep learning remains relatively open. To mitigate the gap, this paper proposes a novel trainable Padding Module that can be placed in a deep learning model. The Padding Module can optimize itself without requiring or influencing the model's entire loss function. To train itself, the Padding Module constructs a ground truth and a predictor from the inputs by leveraging the underlying structure in the input data for supervision. As a result, the Padding Module can learn automatically to pad pixels to the border of its input images or feature maps. The padding contents are realistic extensions to its input data and simultaneously facilitate the deep learning model's downstream task. Experiments have shown that the proposed Padding Module outperforms the state-of-the-art competitors and the baseline methods. For example, the Padding Module has 1.23% and 0.44% more classification accuracy than the zero padding when tested on the VGG16 and ResNet50.
FOD-A: A Dataset for Foreign Object Debris in Airports
Oct 06, 2021

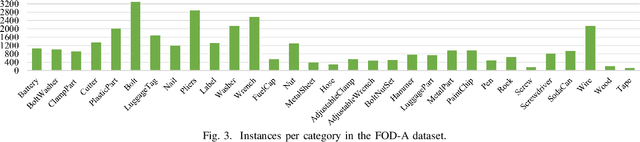
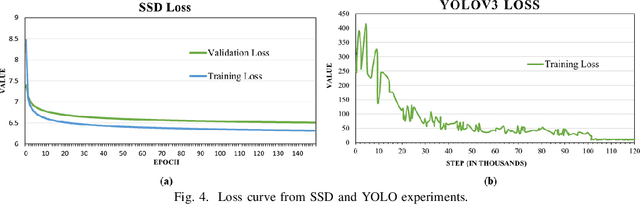
Foreign Object Debris (FOD) detection has attracted increased attention in the area of machine learning and computer vision. However, a robust and publicly available image dataset for FOD has not been initialized. To this end, this paper introduces an image dataset of FOD, named FOD in Airports (FOD-A). FOD-A object categories have been selected based on guidance from prior documentation and related research by the Federal Aviation Administration (FAA). In addition to the primary annotations of bounding boxes for object detection, FOD-A provides labeled environmental conditions. As such, each annotation instance is further categorized into three light level categories (bright, dim, and dark) and two weather categories (dry and wet). Currently, FOD-A has released 31 object categories and over 30,000 annotation instances. This paper presents the creation methodology, discusses the publicly available dataset extension process, and demonstrates the practicality of FOD-A with widely used machine learning models for object detection.
SQRP: Sensing Quality-aware Robot Programming System for Non-expert Programmers
Jun 30, 2021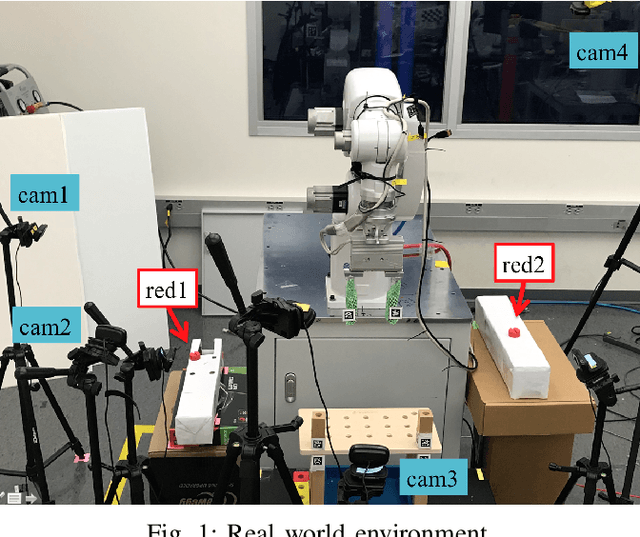
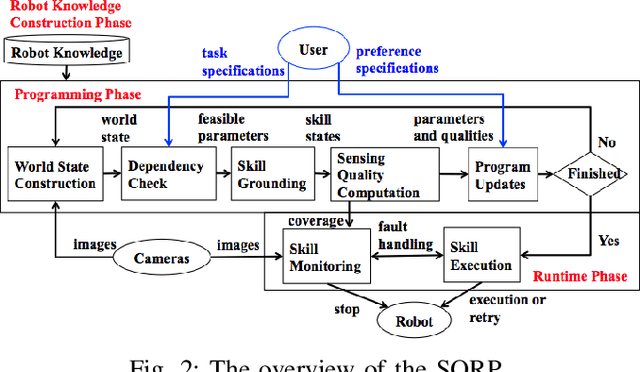
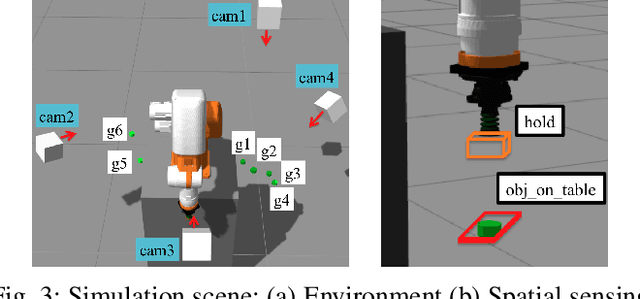
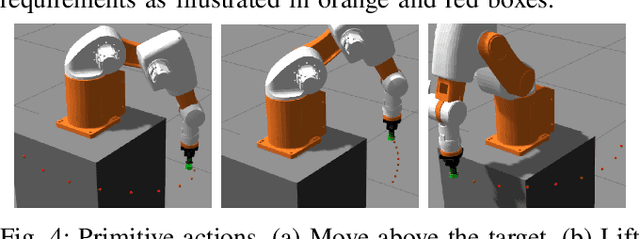
Robot programming typically makes use of a set of mechanical skills that is acquired by machine learning. Because there is in general no guarantee that machine learning produces robot programs that are free of surprising behavior, the safe execution of a robot program must utilize monitoring modules that take sensor data as inputs in real time to ensure the correctness of the skill execution. Owing to the fact that sensors and monitoring algorithms are usually subject to physical restrictions and that effective robot programming is sensitive to the selection of skill parameters, these considerations may lead to different sensor input qualities such as the view coverage of a vision system that determines whether a skill can be successfully deployed in performing a task. Choosing improper skill parameters may cause the monitoring modules to delay or miss the detection of important events such as a mechanical failure. These failures may reduce the throughput in robotic manufacturing and could even cause a destructive system crash. To address above issues, we propose a sensing quality-aware robot programming system that automatically computes the sensing qualities as a function of the robot's environment and uses the information to guide non-expert users to select proper skill parameters in the programming phase. We demonstrate our system framework on a 6DOF robot arm for an object pick-up task.
DLWIoT: Deep Learning-based Watermarking for Authorized IoT Onboarding
Oct 18, 2020
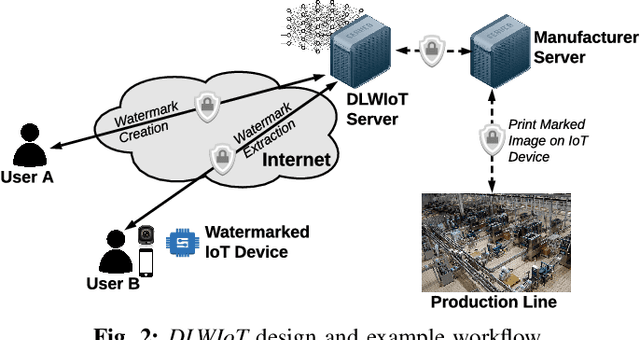
The onboarding of IoT devices by authorized users constitutes both a challenge and a necessity in a world, where the number of IoT devices and the tampering attacks against them continuously increase. Commonly used onboarding techniques today include the use of QR codes, pin codes, or serial numbers. These techniques typically do not protect against unauthorized device access-a QR code is physically printed on the device, while a pin code may be included in the device packaging. As a result, any entity that has physical access to a device can onboard it onto their network and, potentially, tamper it (e.g.,install malware on the device). To address this problem, in this paper, we present a framework, called Deep Learning-based Watermarking for authorized IoT onboarding (DLWIoT), featuring a robust and fully automated image watermarking scheme based on deep neural networks. DLWIoT embeds user credentials into carrier images (e.g., QR codes printed on IoT devices), thus enables IoT onboarding only by authorized users. Our experimental results demonstrate the feasibility of DLWIoT, indicating that authorized users can onboard IoT devices with DLWIoT within 2.5-3sec.
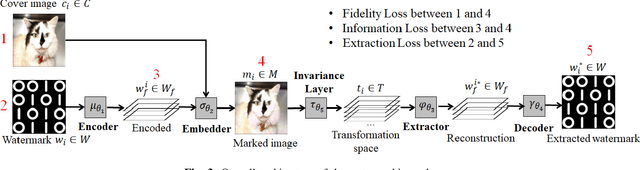
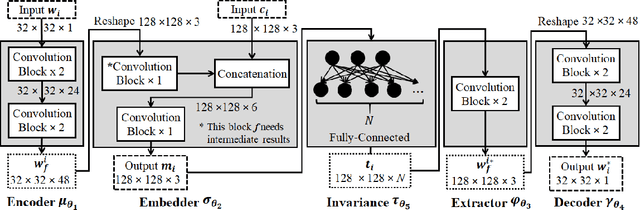
An Automated and Robust Image Watermarking Scheme Based on Deep Neural Networks
Jul 05, 2020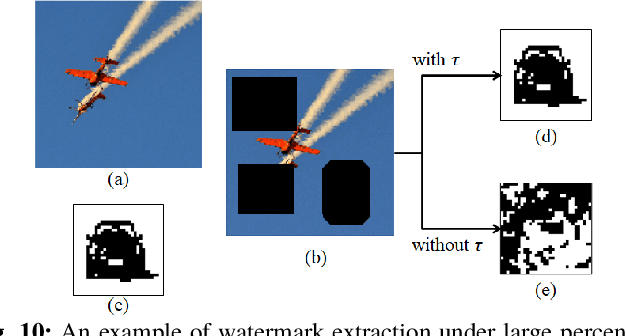
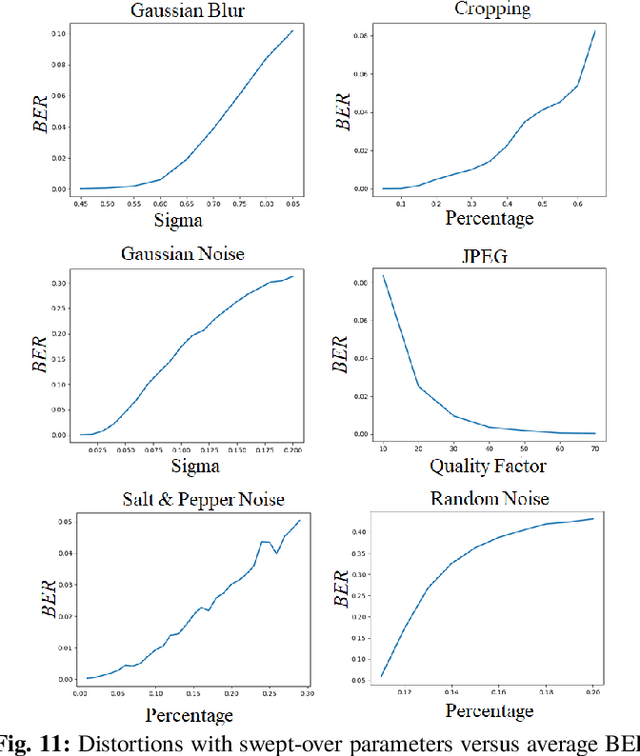

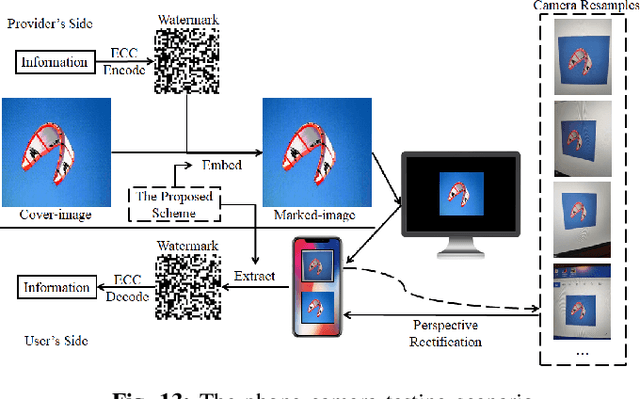
Digital image watermarking is the process of embedding and extracting a watermark covertly on a cover-image. To dynamically adapt image watermarking algorithms, deep learning-based image watermarking schemes have attracted increased attention during recent years. However, existing deep learning-based watermarking methods neither fully apply the fitting ability to learn and automate the embedding and extracting algorithms, nor achieve the properties of robustness and blindness simultaneously. In this paper, a robust and blind image watermarking scheme based on deep learning neural networks is proposed. To minimize the requirement of domain knowledge, the fitting ability of deep neural networks is exploited to learn and generalize an automated image watermarking algorithm. A deep learning architecture is specially designed for image watermarking tasks, which will be trained in an unsupervised manner to avoid human intervention and annotation. To facilitate flexible applications, the robustness of the proposed scheme is achieved without requiring any prior knowledge or adversarial examples of possible attacks. A challenging case of watermark extraction from phone camera-captured images demonstrates the robustness and practicality of the proposal. The experiments, evaluation, and application cases confirm the superiority of the proposed scheme.