 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImperceptible Adversarial Attack on Deep Neural Networks from Image Boundary
Aug 29, 2023Although Deep Neural Networks (DNNs), such as the convolutional neural networks (CNN) and Vision Transformers (ViTs), have been successfully applied in the field of computer vision, they are demonstrated to be vulnerable to well-sought Adversarial Examples (AEs) that can easily fool the DNNs. The research in AEs has been active, and many adversarial attacks and explanations have been proposed since they were discovered in 2014. The mystery of the AE's existence is still an open question, and many studies suggest that DNN training algorithms have blind spots. The salient objects usually do not overlap with boundaries; hence, the boundaries are not the DNN model's attention. Nevertheless, recent studies show that the boundaries can dominate the behavior of the DNN models. Hence, this study aims to look at the AEs from a different perspective and proposes an imperceptible adversarial attack that systemically attacks the input image boundary for finding the AEs. The experimental results have shown that the proposed boundary attacking method effectively attacks six CNN models and the ViT using only 32% of the input image content (from the boundaries) with an average success rate (SR) of 95.2% and an average peak signal-to-noise ratio of 41.37 dB. Correlation analyses are conducted, including the relation between the adversarial boundary's width and the SR and how the adversarial boundary changes the DNN model's attention. This paper's discoveries can potentially advance the understanding of AEs and provide a different perspective on how AEs can be constructed.
Deep Learning based Image Watermarking: A Brief Survey
Aug 08, 2023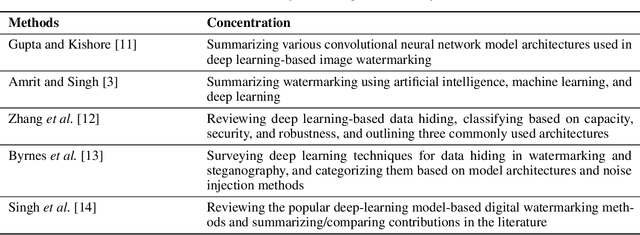
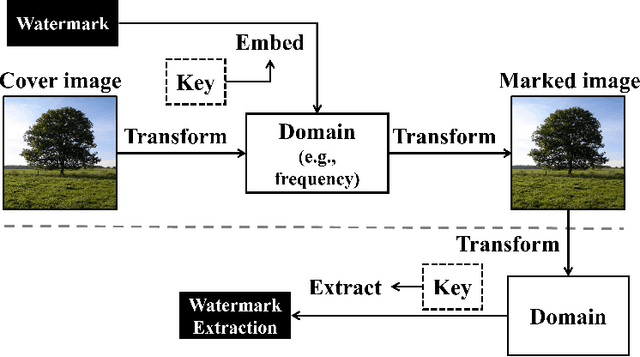
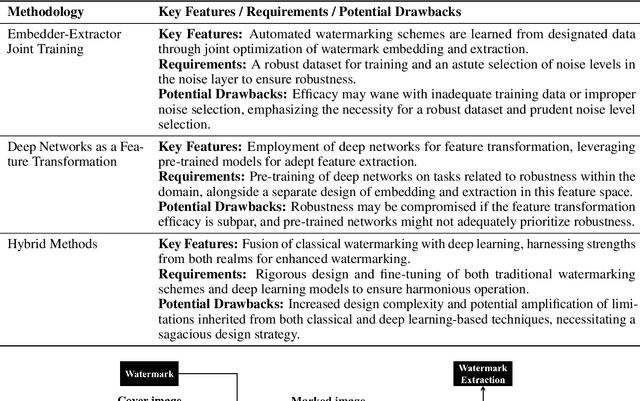
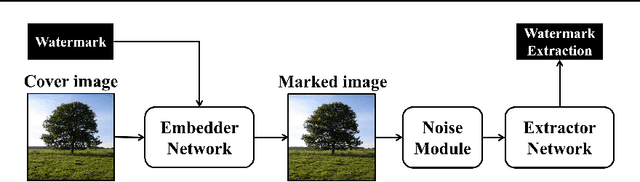
The act of secretly embedding and extracting a watermark on a cover image to protect it is known as image watermarking. In recent years, deep learning-based image watermarking techniques have been emerging one after another. To study the state-of-the-art, this survey categorizes cutting-edge deep learning-based image watermarking techniques into Embedder-Extractor Joint Training, Deep Networks as a Feature Transformation, and Hybrid schemes. Research directions in each category are also analyzed and summarized. Additionally, potential future research directions are discussed to envision future studies.
Padding Module: Learning the Padding in Deep Neural Networks
Jan 11, 2023
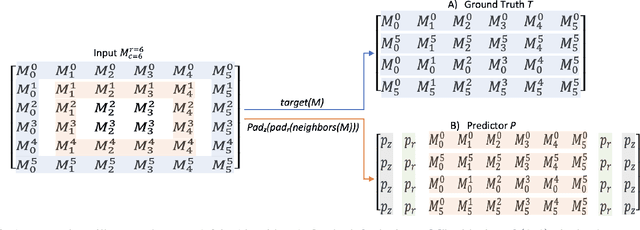
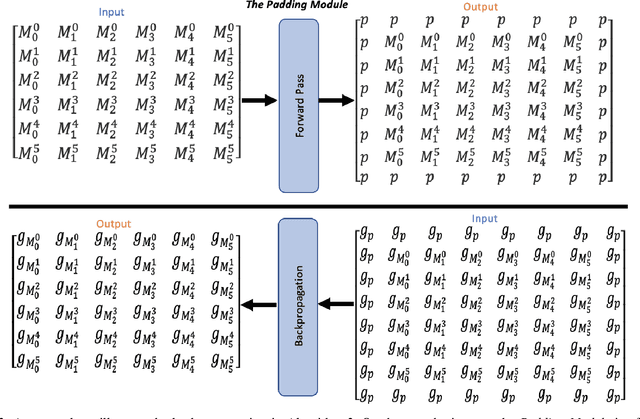
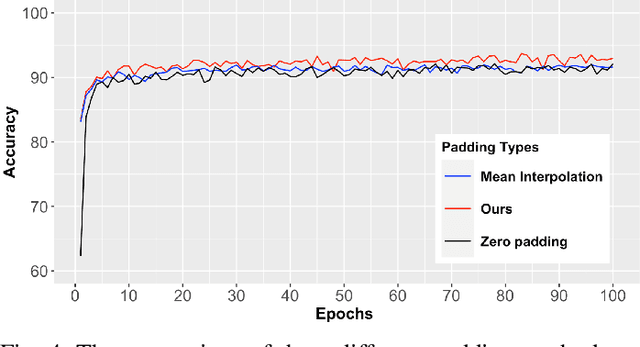
During the last decades, many studies have been dedicated to improving the performance of neural networks, for example, the network architectures, initialization, and activation. However, investigating the importance and effects of learnable padding methods in deep learning remains relatively open. To mitigate the gap, this paper proposes a novel trainable Padding Module that can be placed in a deep learning model. The Padding Module can optimize itself without requiring or influencing the model's entire loss function. To train itself, the Padding Module constructs a ground truth and a predictor from the inputs by leveraging the underlying structure in the input data for supervision. As a result, the Padding Module can learn automatically to pad pixels to the border of its input images or feature maps. The padding contents are realistic extensions to its input data and simultaneously facilitate the deep learning model's downstream task. Experiments have shown that the proposed Padding Module outperforms the state-of-the-art competitors and the baseline methods. For example, the Padding Module has 1.23% and 0.44% more classification accuracy than the zero padding when tested on the VGG16 and ResNet50.