 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViewMix: Augmentation for Robust Representation in Self-Supervised Learning
Sep 06, 2023



Joint Embedding Architecture-based self-supervised learning methods have attributed the composition of data augmentations as a crucial factor for their strong representation learning capabilities. While regional dropout strategies have proven to guide models to focus on lesser indicative parts of the objects in supervised methods, it hasn't been adopted by self-supervised methods for generating positive pairs. This is because the regional dropout methods are not suitable for the input sampling process of the self-supervised methodology. Whereas dropping informative pixels from the positive pairs can result in inefficient training, replacing patches of a specific object with a different one can steer the model from maximizing the agreement between different positive pairs. Moreover, joint embedding representation learning methods have not made robustness their primary training outcome. To this end, we propose the ViewMix augmentation policy, specially designed for self-supervised learning, upon generating different views of the same image, patches are cut and pasted from one view to another. By leveraging the different views created by this augmentation strategy, multiple joint embedding-based self-supervised methodologies obtained better localization capability and consistently outperformed their corresponding baseline methods. It is also demonstrated that incorporating ViewMix augmentation policy promotes robustness of the representations in the state-of-the-art methods. Furthermore, our experimentation and analysis of compute times suggest that ViewMix augmentation doesn't introduce any additional overhead compared to other counterparts.
Deep Learning based Image Watermarking: A Brief Survey
Aug 08, 2023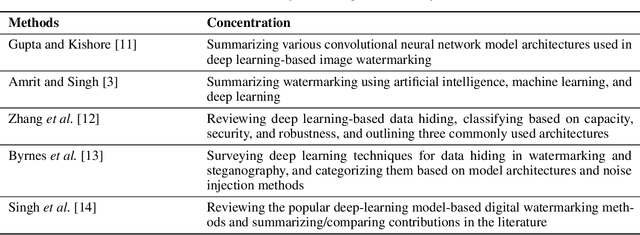
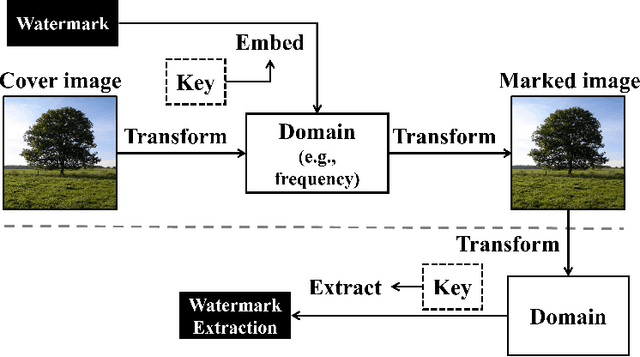
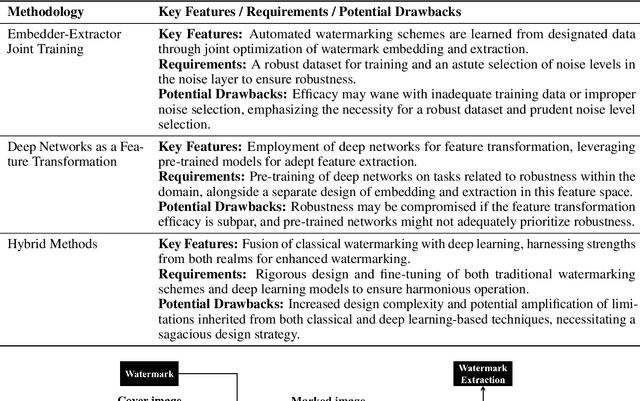
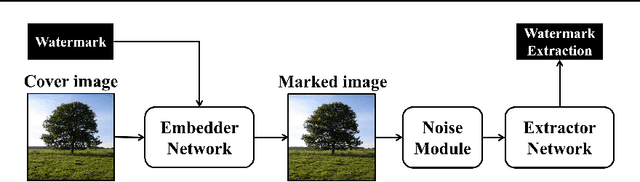
The act of secretly embedding and extracting a watermark on a cover image to protect it is known as image watermarking. In recent years, deep learning-based image watermarking techniques have been emerging one after another. To study the state-of-the-art, this survey categorizes cutting-edge deep learning-based image watermarking techniques into Embedder-Extractor Joint Training, Deep Networks as a Feature Transformation, and Hybrid schemes. Research directions in each category are also analyzed and summarized. Additionally, potential future research directions are discussed to envision future studies.
A Deep Learning-based Audio-in-Image Watermarking Scheme
Oct 06, 2021

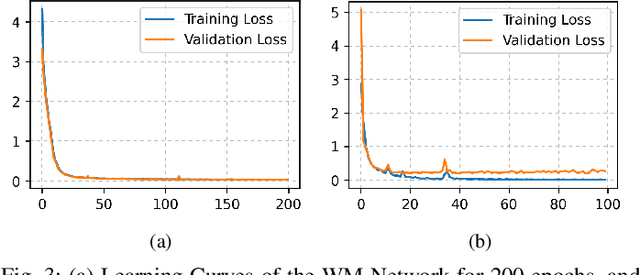

This paper presents a deep learning-based audio-in-image watermarking scheme. Audio-in-image watermarking is the process of covertly embedding and extracting audio watermarks on a cover-image. Using audio watermarks can open up possibilities for different downstream applications. For the purpose of implementing an audio-in-image watermarking that adapts to the demands of increasingly diverse situations, a neural network architecture is designed to automatically learn the watermarking process in an unsupervised manner. In addition, a similarity network is developed to recognize the audio watermarks under distortions, therefore providing robustness to the proposed method. Experimental results have shown high fidelity and robustness of the proposed blind audio-in-image watermarking scheme.