 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMUG: Meta-path-aware Universal Heterogeneous Graph Pre-Training
Feb 26, 2026Universal graph pre-training has emerged as a key paradigm in graph representation learning, offering a promising way to train encoders to learn transferable representations from unlabeled graphs and to effectively generalize across a wide range of downstream tasks. However, recent explorations in universal graph pre-training primarily focus on homogeneous graphs and it remains unexplored for heterogeneous graphs, which exhibit greater structural and semantic complexity. This heterogeneity makes it highly challenging to train a universal encoder for diverse heterogeneous graphs: (i) the diverse types with dataset-specific semantics hinder the construction of a unified representation space; (ii) the number and semantics of meta-paths vary across datasets, making encoding and aggregation patterns learned from one dataset difficult to apply to others. To address these challenges, we propose a novel Meta-path-aware Universal heterogeneous Graph pre-training (MUG) approach. Specifically, for challenge (i), MUG introduces a input unification module that integrates information from multiple node and relation types within each heterogeneous graph into a unified representation.This representation is then projected into a shared space by a dimension-aware encoder, enabling alignment across graphs with diverse schemas.Furthermore, for challenge (ii), MUG trains a shared encoder to capture consistent structural patterns across diverse meta-path views rather than relying on dataset-specific aggregation strategies, while a global objective encourages discriminability and reduces dataset-specific biases. Extensive experiments demonstrate the effectiveness of MUG on some real datasets.
Unified Multi-Domain Graph Pre-training for Homogeneous and Heterogeneous Graphs via Domain-Specific Expert Encoding
Feb 13, 2026Graph pre-training has achieved remarkable success in recent years, delivering transferable representations for downstream adaptation. However, most existing methods are designed for either homogeneous or heterogeneous graphs, thereby hindering unified graph modeling across diverse graph types. This separation contradicts real-world applications, where mixed homogeneous and heterogeneous graphs are ubiquitous, and distribution shifts between upstream pre-training and downstream deployment are common. In this paper, we empirically demonstrate that a balanced mixture of homogeneous and heterogeneous graph pre-training benefits downstream tasks and propose a unified multi-domain \textbf{G}raph \textbf{P}re-training method across \textbf{H}omogeneous and \textbf{H}eterogeneous graphs ($\mathbf{GPH^{2}}$). To address the lack of a unified encoder for homogeneous and heterogeneous graphs, we propose a Unified Multi-View Graph Construction that simultaneously encodes both without explicit graph-type-specific designs. To cope with the increased cross-domain distribution discrepancies arising from mixed graphs, we introduce domain-specific expert encoding. Each expert is independently pre-trained on a single graph to capture domain-specific knowledge, thereby shielding the pre-training encoder from the adverse effects of cross-domain discrepancies. For downstream tasks, we further design a Task-oriented Expert Fusion Strategy that adaptively integrates multiple experts based on their discriminative strengths. Extensive experiments on mixed graphs demonstrate that $\text{GPH}^{2}$ enables stable transfer across graph types and domains, significantly outperforming existing graph pre-training methods.
GP2F: Cross-Domain Graph Prompting with Adaptive Fusion of Pre-trained Graph Neural Networks
Feb 12, 2026Graph Prompt Learning (GPL) has recently emerged as a promising paradigm for downstream adaptation of pre-trained graph models, mitigating the misalignment between pre-training objectives and downstream tasks. Recently, the focus of GPL has shifted from in-domain to cross-domain scenarios, which is closer to the real world applications, where the pre-training source and downstream target often differ substantially in data distribution. However, why GPLs remain effective under such domain shifts is still unexplored. Empirically, we observe that representative GPL methods are competitive with two simple baselines in cross-domain settings: full fine-tuning (FT) and linear probing (LP), motivating us to explore a deeper understanding of the prompting mechanism. We provide a theoretical analysis demonstrating that jointly leveraging these two complementary branches yields a smaller estimation error than using either branch alone, formally proving that cross-domain GPL benefits from the integration between pre-trained knowledge and task-specific adaptation. Based on this insight, we propose GP2F, a dual-branch GPL method that explicitly instantiates the two extremes: (1) a frozen branch that retains pre-trained knowledge, and (2) an adapted branch with lightweight adapters for task-specific adaptation. We then perform adaptive fusion under topology constraints via a contrastive loss and a topology-consistent loss. Extensive experiments on cross-domain few-shot node and graph classification demonstrate that our method outperforms existing methods.
One Prompt Fits All: Universal Graph Adaptation for Pretrained Models
Sep 26, 2025Graph Prompt Learning (GPL) has emerged as a promising paradigm that bridges graph pretraining models and downstream scenarios, mitigating label dependency and the misalignment between upstream pretraining and downstream tasks. Although existing GPL studies explore various prompt strategies, their effectiveness and underlying principles remain unclear. We identify two critical limitations: (1) Lack of consensus on underlying mechanisms: Despite current GPLs have advanced the field, there is no consensus on how prompts interact with pretrained models, as different strategies intervene at varying spaces within the model, i.e., input-level, layer-wise, and representation-level prompts. (2) Limited scenario adaptability: Most methods fail to generalize across diverse downstream scenarios, especially under data distribution shifts (e.g., homophilic-to-heterophilic graphs). To address these issues, we theoretically analyze existing GPL approaches and reveal that representation-level prompts essentially function as fine-tuning a simple downstream classifier, proposing that graph prompt learning should focus on unleashing the capability of pretrained models, and the classifier adapts to downstream scenarios. Based on our findings, we propose UniPrompt, a novel GPL method that adapts any pretrained models, unleashing the capability of pretrained models while preserving the structure of the input graph. Extensive experiments demonstrate that our method can effectively integrate with various pretrained models and achieve strong performance across in-domain and cross-domain scenarios.
DeRS: Towards Extremely Efficient Upcycled Mixture-of-Experts Models
Mar 03, 2025



Upcycled Mixture-of-Experts (MoE) models have shown great potential in various tasks by converting the original Feed-Forward Network (FFN) layers in pre-trained dense models into MoE layers. However, these models still suffer from significant parameter inefficiency due to the introduction of multiple experts. In this work, we propose a novel DeRS (Decompose, Replace, and Synthesis) paradigm to overcome this shortcoming, which is motivated by our observations about the unique redundancy mechanisms of upcycled MoE experts. Specifically, DeRS decomposes the experts into one expert-shared base weight and multiple expert-specific delta weights, and subsequently represents these delta weights in lightweight forms. Our proposed DeRS paradigm can be applied to enhance parameter efficiency in two different scenarios, including: 1) DeRS Compression for inference stage, using sparsification or quantization to compress vanilla upcycled MoE models; and 2) DeRS Upcycling for training stage, employing lightweight sparse or low-rank matrixes to efficiently upcycle dense models into MoE models. Extensive experiments across three different tasks show that the proposed methods can achieve extreme parameter efficiency while maintaining the performance for both training and compression of upcycled MoE models.
Adapter-X: A Novel General Parameter-Efficient Fine-Tuning Framework for Vision
Jun 06, 2024



Parameter-efficient fine-tuning (PEFT) has become increasingly important as foundation models continue to grow in both popularity and size. Adapter has been particularly well-received due to their potential for parameter reduction and adaptability across diverse tasks. However, striking a balance between high efficiency and robust generalization across tasks remains a challenge for adapter-based methods. We analyze existing methods and find that: 1) parameter sharing is the key to reducing redundancy; 2) more tunable parameters, dynamic allocation, and block-specific design are keys to improving performance. Unfortunately, no previous work considers all these factors. Inspired by this insight, we introduce a novel framework named Adapter-X. First, a Sharing Mixture of Adapters (SMoA) module is proposed to fulfill token-level dynamic allocation, increased tunable parameters, and inter-block sharing at the same time. Second, some block-specific designs like Prompt Generator (PG) are introduced to further enhance the ability of adaptation. Extensive experiments across 2D image and 3D point cloud modalities demonstrate that Adapter-X represents a significant milestone as it is the first to outperform full fine-tuning in both 2D image and 3D point cloud modalities with significantly fewer parameters, i.e., only 0.20% and 1.88% of original trainable parameters for 2D and 3D classification tasks. Our code will be publicly available.
Partial Fine-Tuning: A Successor to Full Fine-Tuning for Vision Transformers
Dec 25, 2023Fine-tuning pre-trained foundation models has gained significant popularity in various research fields. Existing methods for fine-tuning can be roughly divided into two categories, namely Parameter-Efficient Fine-Tuning and High-Performance Fine-Tuning. The former aims at improving efficiency, while the latter focuses on enhancing performance. Beyond these methods, we demonstrate that Partial Fine-Tuning can be an innovative and promising direction capable of concurrently enhancing both efficiency and accuracy. We first validate eight manually-defined partial fine-tuning strategies across kinds of datasets and vision transformer architectures, and find that some partial fine-tuning strategies (e.g., ffn only or attention only) can achieve better performance with fewer tuned parameters than full fine-tuning, and selecting appropriate layers is critical to partial fine-tuning. Thus, we propose a novel fine-tuned angle metric to guide the selection of appropriate layers for partial fine-tuning, making it flexible to be adapted to various scenarios for more practicable partial fine-tuning. Additionally, we show that partial fine-tuning can serve as a new dimension for Model Soups, improving both the model performance and generalization with fewer tuned parameters. Comprehensive experiments on a wide range of datasets and models validate the great potential of partial fine-tuning.
Merging Vision Transformers from Different Tasks and Domains
Dec 25, 2023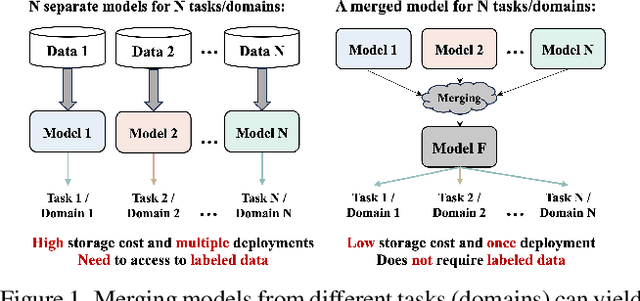

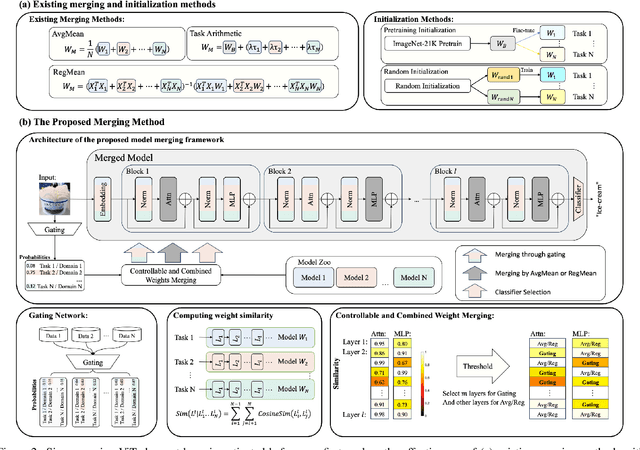
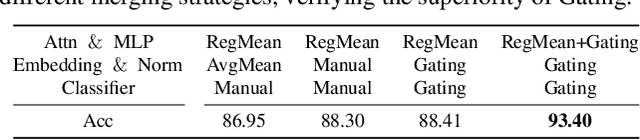
This work targets to merge various Vision Transformers (ViTs) trained on different tasks (i.e., datasets with different object categories) or domains (i.e., datasets with the same categories but different environments) into one unified model, yielding still good performance on each task or domain. Previous model merging works focus on either CNNs or NLP models, leaving the ViTs merging research untouched. To fill this gap, we first explore and find that existing model merging methods cannot well handle the merging of the whole ViT models and still have improvement space. To enable the merging of the whole ViT, we propose a simple-but-effective gating network that can both merge all kinds of layers (e.g., Embedding, Norm, Attention, and MLP) and select the suitable classifier. Specifically, the gating network is trained by unlabeled datasets from all the tasks (domains), and predicts the probability of which task (domain) the input belongs to for merging the models during inference. To further boost the performance of the merged model, especially when the difficulty of merging tasks increases, we design a novel metric of model weight similarity, and utilize it to realize controllable and combined weight merging. Comprehensive experiments on kinds of newly established benchmarks, validate the superiority of the proposed ViT merging framework for different tasks and domains. Our method can even merge beyond 10 ViT models from different vision tasks with a negligible effect on the performance of each task.
Experts Weights Averaging: A New General Training Scheme for Vision Transformers
Aug 25, 2023Structural re-parameterization is a general training scheme for Convolutional Neural Networks (CNNs), which achieves performance improvement without increasing inference cost. As Vision Transformers (ViTs) are gradually surpassing CNNs in various visual tasks, one may question: if a training scheme specifically for ViTs exists that can also achieve performance improvement without increasing inference cost? Recently, Mixture-of-Experts (MoE) has attracted increasing attention, as it can efficiently scale up the capacity of Transformers at a fixed cost through sparsely activated experts. Considering that MoE can also be viewed as a multi-branch structure, can we utilize MoE to implement a ViT training scheme similar to structural re-parameterization? In this paper, we affirmatively answer these questions, with a new general training strategy for ViTs. Specifically, we decouple the training and inference phases of ViTs. During training, we replace some Feed-Forward Networks (FFNs) of the ViT with specially designed, more efficient MoEs that assign tokens to experts by random uniform partition, and perform Experts Weights Averaging (EWA) on these MoEs at the end of each iteration. After training, we convert each MoE into an FFN by averaging the experts, transforming the model back into original ViT for inference. We further provide a theoretical analysis to show why and how it works. Comprehensive experiments across various 2D and 3D visual tasks, ViT architectures, and datasets validate the effectiveness and generalizability of the proposed training scheme. Besides, our training scheme can also be applied to improve performance when fine-tuning ViTs. Lastly, but equally important, the proposed EWA technique can significantly improve the effectiveness of naive MoE in various 2D visual small datasets and 3D visual tasks.