 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMerging Vision Transformers from Different Tasks and Domains
Paper and Code
Dec 25, 2023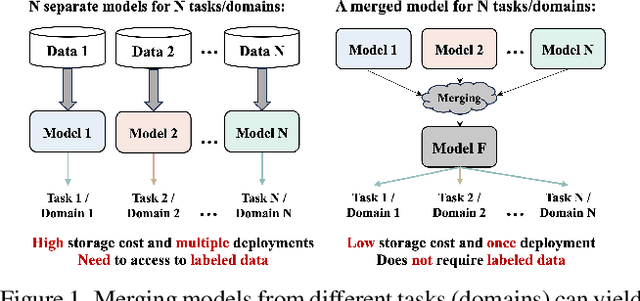

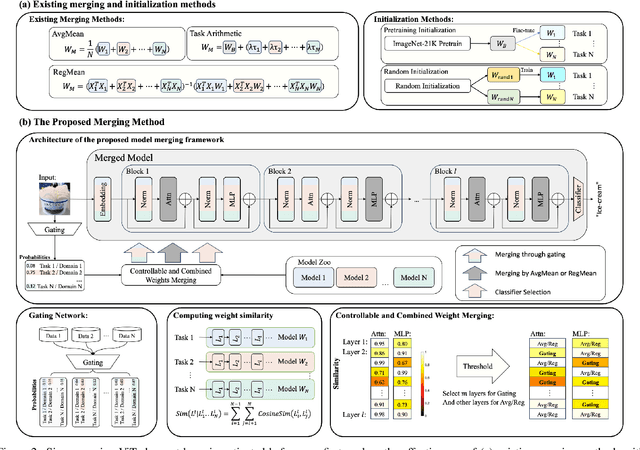
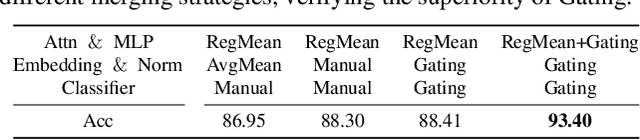
This work targets to merge various Vision Transformers (ViTs) trained on different tasks (i.e., datasets with different object categories) or domains (i.e., datasets with the same categories but different environments) into one unified model, yielding still good performance on each task or domain. Previous model merging works focus on either CNNs or NLP models, leaving the ViTs merging research untouched. To fill this gap, we first explore and find that existing model merging methods cannot well handle the merging of the whole ViT models and still have improvement space. To enable the merging of the whole ViT, we propose a simple-but-effective gating network that can both merge all kinds of layers (e.g., Embedding, Norm, Attention, and MLP) and select the suitable classifier. Specifically, the gating network is trained by unlabeled datasets from all the tasks (domains), and predicts the probability of which task (domain) the input belongs to for merging the models during inference. To further boost the performance of the merged model, especially when the difficulty of merging tasks increases, we design a novel metric of model weight similarity, and utilize it to realize controllable and combined weight merging. Comprehensive experiments on kinds of newly established benchmarks, validate the superiority of the proposed ViT merging framework for different tasks and domains. Our method can even merge beyond 10 ViT models from different vision tasks with a negligible effect on the performance of each task.